Keras: mnist.load_data()
Scikit-learn: load_digits()
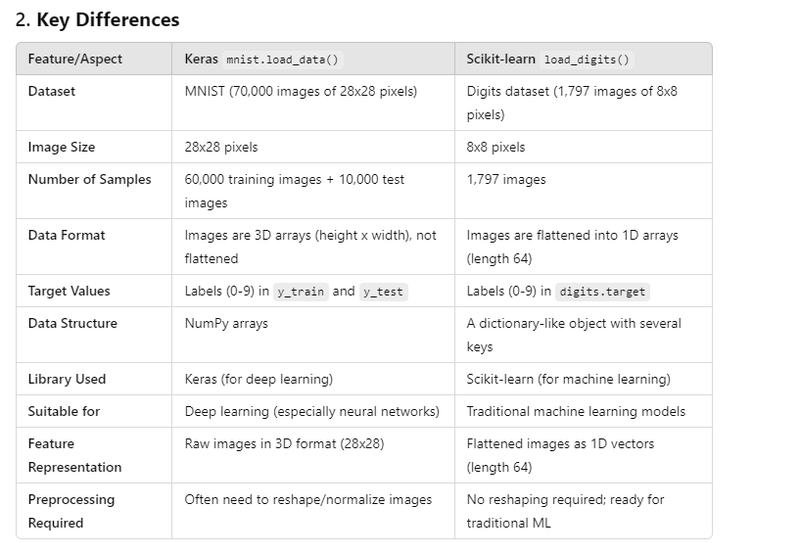
Tabular Comparision between Keras: mnist.load_data and Scikit-learn: load_digits
When to Use Which
How to create pandas dataframe from MNIST datasets
Keras mnist.load_data() vs. Scikit-learn load_digits()
Keras: mnist.load_data()
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()
Dataset:
This loads the MNIST dataset, which contains 70,000 grayscale images of handwritten digits (0-9), where each image is a 28x28 pixel image.
This is one of the most popular datasets for image classification, especially for benchmarking machine learning models on digit recognition tasks.
Data format:
Images (X_train, X_test):
Each image is represented as a 2D array (28x28 pixels) with integer values (0 to 255) representing pixel intensity (grayscale).
X_train: Contains 60,000 training images.
X_test: Contains 10,000 test images.
Labels (y_train, y_test):
These represent the digit corresponding to each image (0-9).
y_train: Contains 60,000 labels for training.
y_test: Contains 10,000 labels for testing.
Shape:
X_train: (60000, 28, 28) → 60,000 images of size 28x28 pixels.
y_train: (60000,) → 60,000 labels (digits 0-9).
X_test: (10000, 28, 28) → 10,000 images of size 28x28 pixels.
y_test: (10000,) → 10,000 labels.
Key characteristics:
The data is returned as NumPy arrays, and the images are structured in a 3D array (samples x height x width).
This is a raw image dataset, suitable for image classification tasks.
You usually need to preprocess the images (e.g., flatten them into vectors if used with traditional machine learning models or normalize pixel values between 0 and 1).
Scikit-learn: load_digits()
import pandas as pd
from sklearn.datasets import load_digits
digits = load_digits()
Dataset:
This loads the Digits dataset, a smaller dataset similar to MNIST. It contains 1,797 images of digits (0-9), where each image is 8x8 pixels.
It is also used for digit classification but is much smaller than MNIST, with lower resolution images (8x8 vs. 28x28 in MNIST).
Data format:
Images (digits.data):
The images are represented as flattened vectors (1D arrays) of length 64 (8x8 = 64 pixels). Each value represents the intensity of a pixel (from 0 to 16 in grayscale).
Labels (digits.target):
These represent the digit corresponding to each image (0-9).
Scikit-learn's load_digits() returns the data as a dictionary-like object, which contains:
'data': The pixel values for each image (flattened to 1D array).
'target': The label for each image (0-9).
'target_names': The unique labels (digits 0-9).
'images': The original 8x8 images in a 3D array (useful for visualizing the images).
'DESCR': A description of the dataset.
Shape:
digits.data: (1797, 64) → 1,797 samples, each flattened into a 64-element vector (8x8 pixels).
digits.target: (1797,) → 1,797 labels (digits 0-9).
digits.images: (1797, 8, 8) → 1,797 images in their original 8x8 pixel format.
Key characteristics:
The images are returned as flattened vectors, which makes it easier to work with traditional machine learning algorithms that expect a 2D array (i.e., samples x features).
The dataset is smaller and simpler compared to MNIST.
This is more of a tabular dataset (because the images are flattened), and is easy to feed directly into scikit-learn models like logistic regression, SVMs, etc.
When to Use Which
Use Keras mnist.load_data():
When you're working with deep learning models like Convolutional Neural Networks (CNNs), which can handle image data in its 2D form (28x28).
When you need a larger dataset for training models that require a lot of data (e.g., deep neural networks).
When you are working with more detailed, higher-resolution digit images.
Use Scikit-learn load_digits():
When you're working with traditional machine learning models that require 2D input (samples x features) such as Support Vector Machines (SVMs), Logistic Regression, k-NN, etc.
When you want to quickly experiment with a smaller, simpler dataset.
If you're looking for an easier dataset to understand and use in educational or prototyping scenarios, as the Digits dataset is smaller and requires less processing.
Example of loading and inspecting load_digits data:
python
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
# Load the Digits dataset
digits = load_digits()
# Show the data keys (similar to 'feature names')
print(digits.keys())
# Display the first image in the dataset
plt.imshow(digits.images[0], cmap='gray')
plt.title(f'Label: {digits.target[0]}')
plt.show()
# Print the first image's flattened data (1D array)
print("Flattened image data:", digits.data[0])
This will display the first image in the Digits dataset, along with its label and flattened pixel values.
Conclusion:
Keras' MNIST dataset is more suited for deep learning applications, with a larger number of higher-resolution images.
Scikit-learn's Digits dataset is ideal for traditional machine learning tasks, as the images are smaller and already flattened for ease of use.
Both datasets are great for experimenting with digit classification, but they are tailored for different types of models.
Coding on Keras mnist.load_data()
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
(X_train, y_train) , (X_test, y_test) = keras.datasets.mnist.load_data()
len(X_train)
60000
len(X_test)
10000
#X_train.shape =>(60000, 28, 28)
X_train[0].shape==>(28, 28)
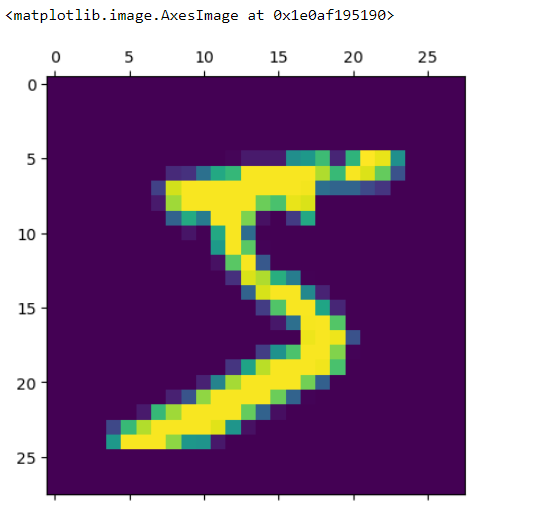
plt.matshow(X_train[0])
num_images = 5 # Number of images to display
for i in range(num_images):
plt.figure(figsize=(2, 2))
plt.imshow(X_train[i], cmap='gray')
plt.title(f"Label: {y_train[i]}")
plt.axis('off')
plt.show()


How to create pandas dataframe from MNIST datasets
import numpy as np
import pandas as pd# Step 2: Combine train and test data into a single dataset
X = np.concatenate([X_train, X_test])
y = np.concatenate([y_train, y_test])
print(X)
print('print value of y')
print(y)
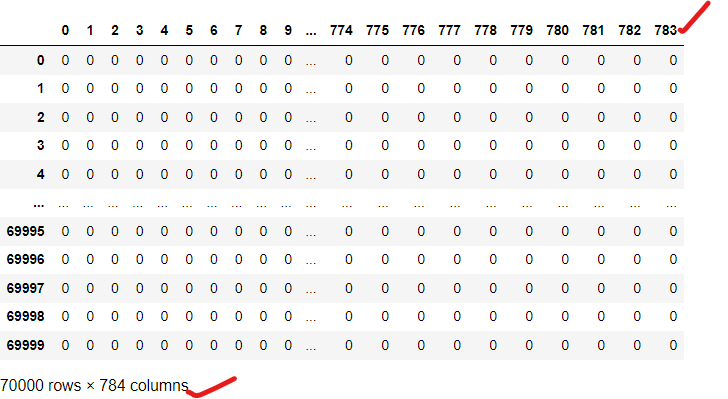
# Step 3: Flatten the images from 28x28 into 1D array of 784 elements
X_flattened = X.reshape(X.shape[0], -1)
print('print value of X_flattened')
print(X_flattened)
# Step 4: Create a pandas DataFrame from the flattened images
mnist_data = pd.DataFrame(X_flattened)
print('print value ofmnist_data')
mnist_data
OUTPUT


print value of y
print value of X_flattened

print value of mnist_data
Coding on Scikit-learn load_digits()
import pandas as pd
from sklearn.datasets import load_digits
digits = load_digits()
dir(digits)
['DESCR', 'data', 'feature_names', 'frame', 'images', 'target', 'target_names']
%matplotlib inline
import matplotlib.pyplot as plt
plt.gray()
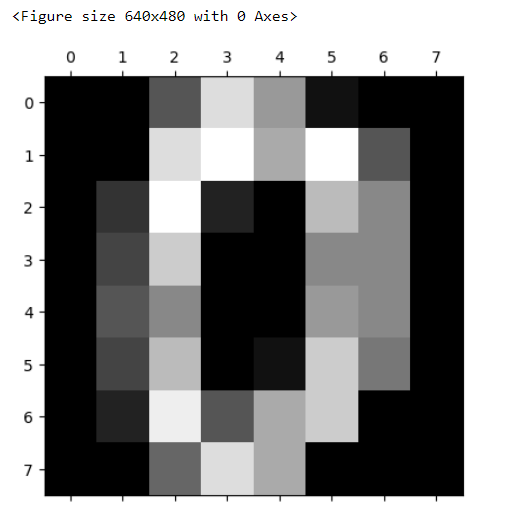
for i in range(4):
plt.matshow(digits.images[i])
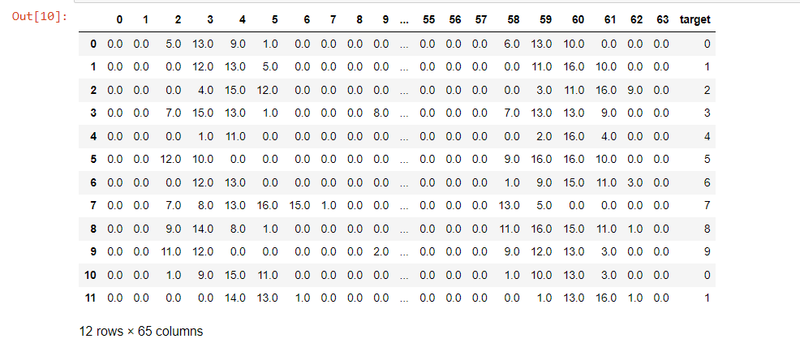
df = pd.DataFrame(digits.data)
df.head()
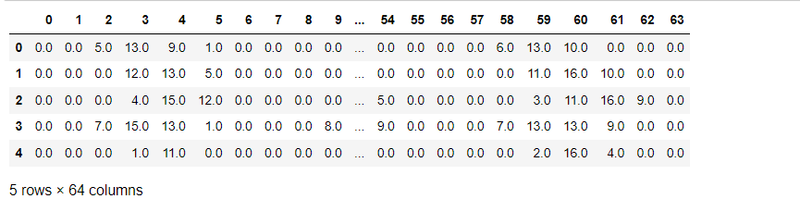
df['target'] = digits.target
df[0:12]

Top comments (0)