OpenAI Embeddings API
Using OpenAI API with openai.Embedding.create()
Using OpenAIEmbeddings from langchain or another library
Ollama (Local Self-hosted Models)
Using Ollama API with ollama.embed
Using OllamaEmbeddingsfrom langchain
Hugging Face (Transformers & Sentence-BERT)
Using Hugging Face API (Direct HTTP Request)
OpenAI Embeddings API
Two way
Using OpenAI API with openai.Embedding.create()
Using OpenAIEmbeddings from langchain or another library
Using OpenAI API with openai.Embedding.create()
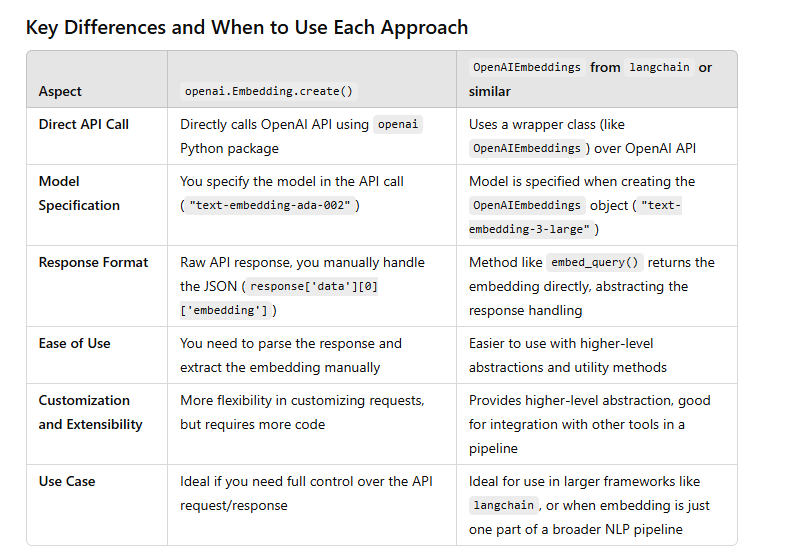
OpenAI provides an API to generate embeddings using its powerful models such as text-embedding-ada-002. This method is cloud-based and requires an API key.
import openai
# Set your OpenAI API key
openai.api_key = 'your-api-key-here'
def get_openai_embedding(text):
# Use the text-embedding-ada-002 model to get text embeddings
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=text
)
embedding = response['data'][0]['embedding']
return embedding
# Example usage
text = "OpenAI provides cutting-edge AI models."
embedding = get_openai_embedding(text)
print(embedding)
output
print(response)
{
"object": "list",
"data": [
{
"object": "embedding",
"embedding": [0.001, -0.003, 0.024, ...], // The embedding vector
"index": 0
}
],
"model": "text-embedding-ada-002",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}
print(embedding)
[0.001, -0.003, 0.024, 0.010, -0.012, ...]

Embedding Multiple document Using OpenAI Api
import openai
# Set your OpenAI API key
openai.api_key = 'your-api-key-here'
def get_openai_embeddings(texts):
# Request embeddings for multiple documents
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=texts
)
# Extract embeddings for each document
embeddings = [item['embedding'] for item in response['data']]
return embeddings
# Example usage
documents = [
"Alpha is the first letter of the Greek alphabet",
"Beta is the second letter of the Greek alphabet"
]
embeddings = get_openai_embeddings(documents)
# Print the embedding for the second document
print(embeddings[1])
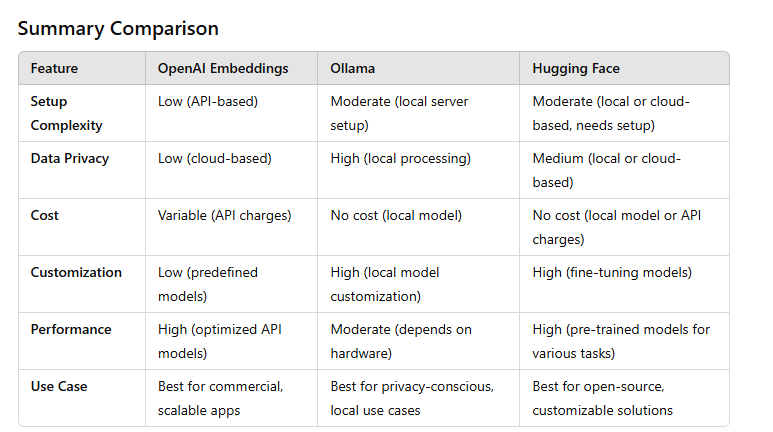
Advantages:
High Quality: OpenAI’s models (like text-embedding-ada-002) are well-optimized for generating highly accurate and meaningful embeddings.
No Setup Required: You don’t need to worry about model architecture, training, or running inference on your hardware.
Scalability: OpenAI’s API is highly scalable for large volumes of requests.
Disadvantages:
Cost: Using OpenAI’s API incurs ongoing costs, especially with large volumes of data or frequent API calls.
Dependency: Requires a stable internet connection and a valid API key, meaning you depend on OpenAI’s availability and service uptime.
Data Privacy: Data sent to OpenAI's servers is processed externally, which may not be suitable for highly sensitive information.
When to Use:
Best for Commercial Applications: If you want a powerful, pre-trained model with high-quality embeddings without the need for infrastructure setup.
When Scalability is Needed: If your application needs to handle a large number of requests efficiently without worrying about infrastructure.
Using OpenAIEmbeddings from langchain or another library
import os
from dotenv import load_dotenv
load_dotenv()
os.environ["OPENAI_API_KEY"]=os.getenv("OPENAI_API_KEY")
from langchain_openai import OpenAIEmbeddings
embeddings=OpenAIEmbeddings(model="text-embedding-3-large")
embeddings
text="This is a tutorial on OPENAI embedding"
query_result=embeddings.embed_query(text)
query_result
output
print(embedding)
OpenAIEmbeddings(client=<openai.resources.embeddings.Embeddings object at 0x000001A000D82C20>, async_client=<openai.resources.embeddings.AsyncEmbeddings object at 0x000001A003551630>, model='text-embedding-3-large', dimensions=None, deployment='text-embedding-ada-002', openai_api_version='', openai_api_base=None, openai_api_type='', openai_proxy='', embedding_ctx_length=8191, openai_api_key=SecretStr('**********'), openai_organization=None, allowed_special=None, disallowed_special=None, chunk_size=1000, max_retries=2, request_timeout=None, headers=None, tiktoken_enabled=True, tiktoken_model_name=None, show_progress_bar=False, model_kwargs={}, skip_empty=False, default_headers=None, default_query=None, retry_min_seconds=4, retry_max_seconds=20, http_client=None, http_async_client=None, check_embedding_ctx_length=True)
print(query_result)
[0.001956823281943798,
0.041745562106370926,
-0.013878178782761097,
-0.039858128875494,
0.023981492966413498,
0.004118349868804216,
0.016626058146357536,
-0.01966537907719612,
0.005950269289314747,
-0.003684656461700797,
...]
Embedding with Dimension 4096 for Large Texts
from langchain_openai import OpenAIEmbeddings
# Use higher dimensions (4096) for handling complex texts
embeddings_4096 = OpenAIEmbeddings(model="text-embedding-3-large", dimensions=4096)
text = "Deep learning is a powerful technique in machine learning"
query_result = embeddings_4096.embed_query(text)
# Output the embedding and its length
print(query_result)
print(len(query_result))
Embedding Multiple document Using OpenAIEmbeddings
from langchain.embeddings import OpenAIEmbeddings
# Initialize OpenAIEmbeddings with the desired model
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
# Embed multiple documents
r1 = embeddings.embed_documents([
"Alpha is the first letter of the Greek alphabet",
"Beta is the second letter of the Greek alphabet"
])
# Print the embedding for the second document
print(r1[1])
[0.0034, -0.0012, 0.0051, ..., 0.0023] # A list of 1536 float values.

Ollama (Local Self-hosted Models)
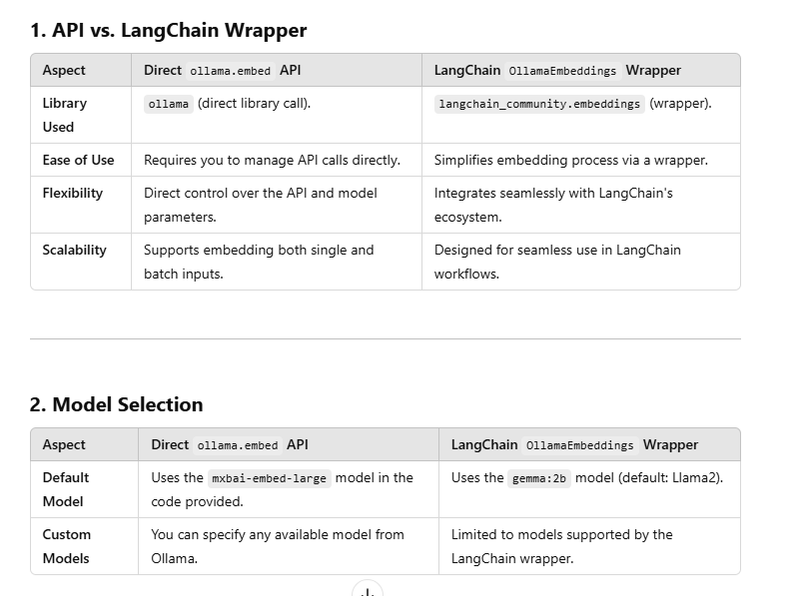
Ollama provides AI models that can be run locally, offering a more flexible solution. You can either use a local Ollama server or access models via the Python API. This is particularly useful for those who want to avoid cloud costs or need more control over data privacy.
Two way
Using Ollama API with ollama.embed
Using OllamaEmbeddingsfrom langchain
Embedding single document using Ollama API with ollama.embed
import ollama
def get_ollama_embedding(text):
# Request the embedding from an Ollama model using embed function
response = ollama.embed(model="mxbai-embed-large", input=text)
return response['embedding']
# Example usage
text = "Ollama provides powerful local models."
embedding = get_ollama_embedding(text)
print(embedding)
[0.0025, -0.0043, 0.0011, 0.0078, -0.0065, ..., 0.0032]
Embedding Multiple document Using ollama Api
import ollama
def get_ollama_embeddings(texts):
# Request embeddings for multiple documents
embeddings = [] # To store the embeddings
for text in texts:
response = ollama.embed(model="mxbai-embed-large", input=text)
embeddings.append(response['embedding'])
return embeddings
# Example usage
documents = [
"Ollama provides powerful local models.",
"It allows efficient embeddings and processing of text.",
"Embeddings are used for various NLP tasks."
]
embeddings = get_ollama_embeddings(documents)
# Print embeddings for each document
for i, embedding in enumerate(embeddings):
print(f"Document {i + 1}: {embedding[:5]}...") # Print the first 5 values for brevity
output

How to embed a single document using OllamaEmbeddings
from langchain_community.embeddings import OllamaEmbeddings
# Initialize OllamaEmbeddings
embeddings = OllamaEmbeddings(model="gemma:2b") # By default, uses Llama2
# Single document to embed
text = "Alpha is the first letter of the Greek alphabet."
# Embed the single document
embedding = embeddings.embed_query(text)
# Print the embedding for the single document
print(embedding)

Embedding Multiple document Using ollama embedding wrapper class
from langchain_community.embeddings import OllamaEmbeddings
embeddings=(
OllamaEmbeddings(model="gemma:2b") ##by default it ues llama2
)
r1=embeddings.embed_documents(
[
"Alpha is the first letter of Greek alphabet",
"Beta is the second letter of Greek alphabet",
]
)
print(r1[1])
[-2.3592045307159424,
-0.8716640472412109,
-0.22409206628799438,
2.4858193397521973,
1.262244462966919,
-1.7182726860046387,
-0.11123710125684738,
0.7157507538795471,
1.6657123565673828,
-0.8437683582305908,
0.7881910800933838,
0.3762670159339905,
...]
Advantages:
Local Processing: Since it runs locally, data does not need to leave your premises, providing better privacy and security.
No API Costs: There are no ongoing costs associated with API calls, as you can run the models on your own hardware.
Customizability: Ollama allows more flexibility in customizing the models and deploying them in specific environments.
Disadvantages:
Requires Local Hardware: To run models locally, you need adequate hardware (GPUs or TPUs for larger models).
Complex Setup: Setting up Ollama models locally can be more complex than using a cloud-based API.
Performance: Local models may not always match the performance and optimization of cloud-based models like OpenAI, especially for large-scale tasks.
When to Use:
When Data Privacy is Critical: If you're working with sensitive information and cannot afford to send data to external servers.
When Cloud Services are Not Feasible: If you are working in a restricted environment where internet access or API usage is limited, running Ollama locally can be a good alternative.
For Cost-Effective Solutions: If you have the hardware to run models and want to avoid ongoing costs from API usage.
Hugging Face (Transformers & Sentence-BERT)
Hugging Face provides a broad range of transformer models, including Sentence-BERT, which is widely used for sentence embeddings. You can use Hugging Face's transformers library to easily download and use pre-trained models for generating embeddings.
Using HuggingFaceEmbeddings Wrapper Class
import os
from dotenv import load_dotenv
load_dotenv() #load all the environment variables
os.environ['HF_TOKEN']=os.getenv("HF_TOKEN")
from langchain_huggingface import HuggingFaceEmbeddings
embeddings=HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
text="this is atest documents"
query_result=embeddings.embed_query(text)
query_result
Using Hugging face api
import os
from dotenv import load_dotenv
import requests
# Load environment variables from .env file
load_dotenv()
HF_TOKEN = os.getenv("HF_TOKEN") # Your Hugging Face API Token
# API URL for the embedding model
API_URL = "https://api-inference.huggingface.co/models/sentence-transformers/all-MiniLM-L6-v2"
# Headers with the authorization token
headers = {
"Authorization": f"Bearer {HF_TOKEN}"
}
# Text to embed
text = "this is a test document"
# API Request
def get_huggingface_embedding(text):
response = requests.post(API_URL, headers=headers, json={"inputs": text})
response.raise_for_status() # Raise an error if the request fails
return response.json() # Return the embedding
# Generate the embedding
embedding = get_huggingface_embedding(text)
# Print the embedding
print("Embedding for the text:", text)
print(embedding[:5], "...") # Display first 5 values for brevity
output
Embedding for the text: Hugging Face provides state-of-the-art machine learning models.
[0.1234, -0.0023, 0.0456, 0.0678, -0.0031] ...
from sentence_transformers import SentenceTransformer
# Load the pre-trained model for sentence embeddings
model = SentenceTransformer('all-MiniLM-L6-v2')
def get_huggingface_embedding(text):
# Get the vector embedding for the text
embedding = model.encode(text)
return embedding
# Example usage
text = "Hugging Face offers powerful NLP models."
embedding = get_huggingface_embedding(text)
print(embedding)
Handling Multiple Documents
def get_huggingface_embeddings(texts):
headers = {"Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(API_URL, headers=headers, json={"inputs": texts})
response.raise_for_status()
return response.json()
# Batch embedding
texts = [
"Hugging Face provides state-of-the-art machine learning models.",
"Transformers library is very powerful for NLP tasks."
]
embeddings = get_huggingface_embeddings(texts)
# Print embeddings for each document
for i, embedding in enumerate(embeddings):
print(f"Embedding for document {i+1}: {embedding[:5]} ...")
Wrapper Method (Batch Processing):
def get_huggingface_embeddings_wrapper(texts):
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.tolist()
# Batch embedding
texts = [
"Hugging Face provides state-of-the-art machine learning models.",
"Transformers library is very powerful for NLP tasks."
]
embeddings = get_huggingface_embeddings_wrapper(texts)
# Print embeddings for each document
for i, embedding in enumerate(embeddings):
print(f"Embedding for document {i+1}: {embedding[:5]} ...")
Advantages:
Open Source: Hugging Face offers a large collection of pre-trained models for various tasks, including sentence embeddings, which are open source and free to use.
Flexibility: You can fine-tune models on your own data or choose from a wide variety of pre-trained models for different NLP tasks.
Local or Cloud Execution: You can run the models locally or use Hugging Face’s API for cloud execution, giving you flexibility based on your requirements.
Disadvantages:
Requires Setup: You need to handle model management and possibly deal with hardware limitations when running models locally.
Model Size: Some transformer models are quite large, requiring significant memory and computation resources for inference.
Performance: While Hugging Face models are generally high-quality, they might not be as optimized for speed or accuracy as OpenAI's offerings.

SUMMARY
OpenAI Embeddings API
Using OpenAI API with openai.Embedding.create()[single and multiple]
Using OpenAIEmbeddings from langchain or another library[single and multiple]
Ollama (Local Self-hosted Models)
Using Ollama API with ollama.embed[single and multiple]
Using OllamaEmbeddingsfrom langchain[single and multiple]
Hugging Face (Transformers & Sentence-BERT)
Using Hugging Face API (Direct HTTP Request)[single and multiple]
response = openai.Embedding.create(model="text-embedding-ada-002",input=text) ||embedding = response['data'][0]['embedding']
Embedding Multiple document Using OpenAI Api====
documents is in list form follow above process
embeddings = [item['embedding'] for item in response['data']]

Top comments (0)