Explain the component of backpropogation
How backpropogation minimize loss
explain chain rule of differentiation
how to apply chain rule of differentitaion in back propogation
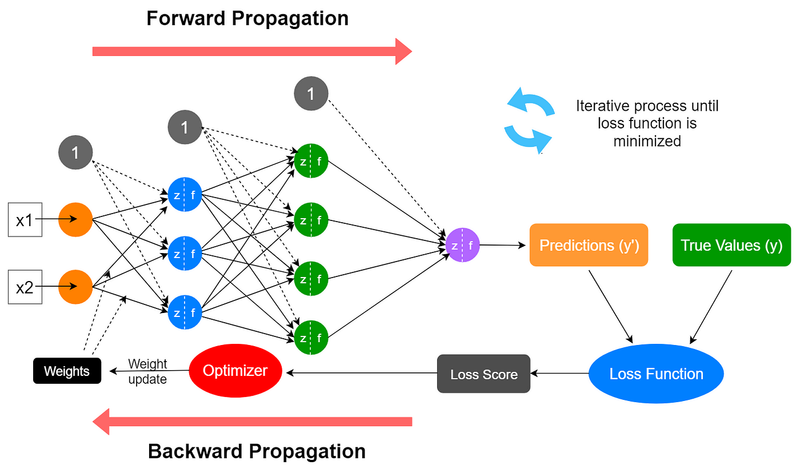
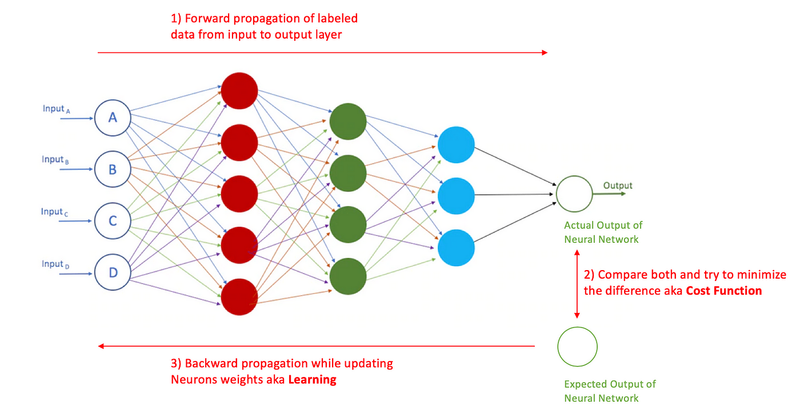
Backpropagation, short for "backward propagation of errors," is a key algorithm for training neural networks. It enables the network to learn from its mistakes and adjust its parameters (weights and biases) to minimize the error in its predictions. Here's an explanation of backpropagation with an example:
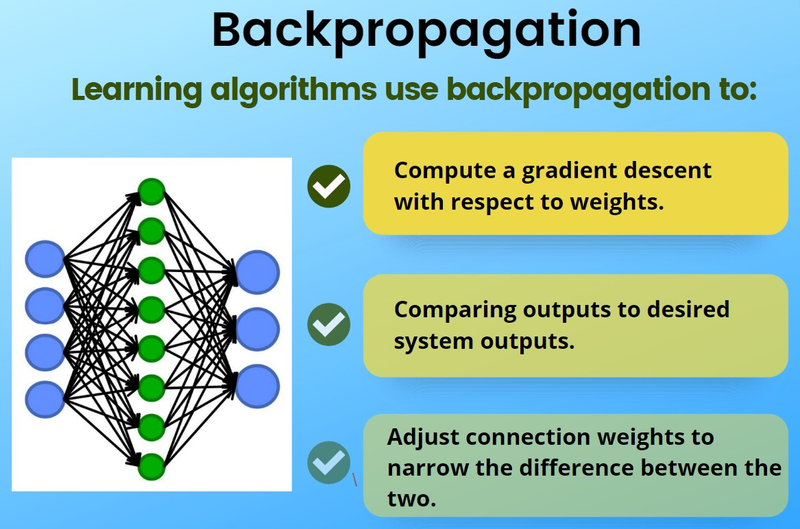
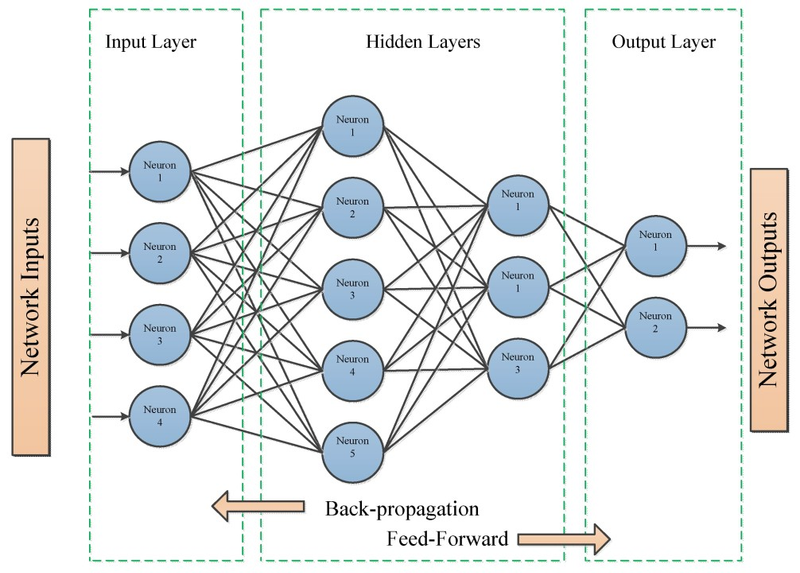

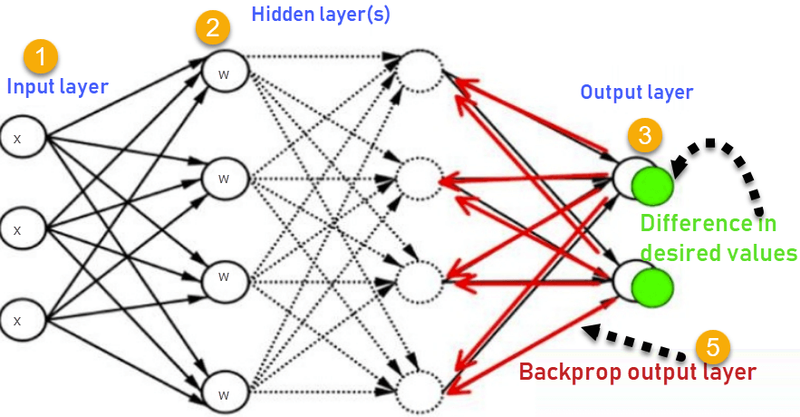
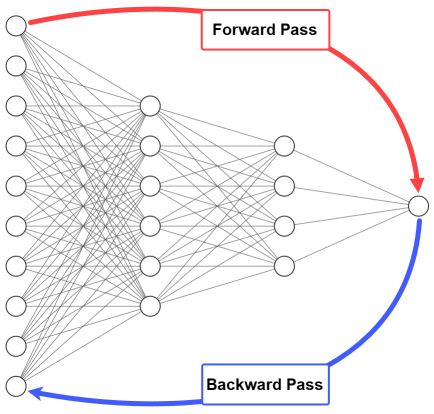
Components of Backpropagation:
Forward Pass:
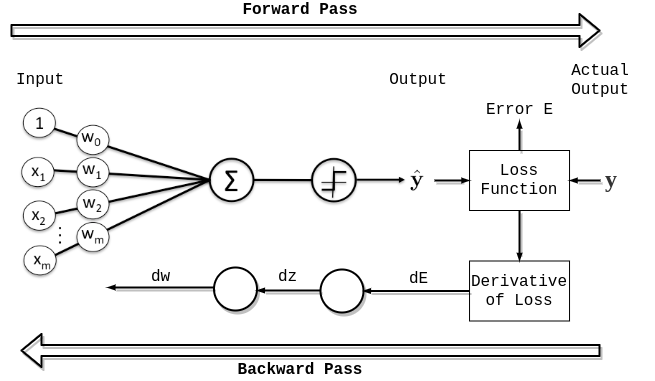
- In the forward pass, input data is fed through the neural network to make predictions. Each neuron computes a weighted sum of its inputs, applies an activation function, and passes the result to the next layer.
- The network's output is compared to the true target values, and the error (loss) is calculated using a loss function (e.g., mean squared error or cross-entropy) .
Backward Pass (Backpropagation):
- The backward pass is where the network learns by adjusting its parameters.
- The main idea is to calculate the gradients of the loss with respect to the network's weights and biases. These gradients indicate how much each weight and bias should be adjusted to minimize the loss .

Steps of Backpropagation:
Calculate Output Layer Gradients:
Start with the output layer and calculate the gradient of the loss with respect to the output values. This is often computed using the derivative of the chosen loss function.
Backpropagate the Gradients:
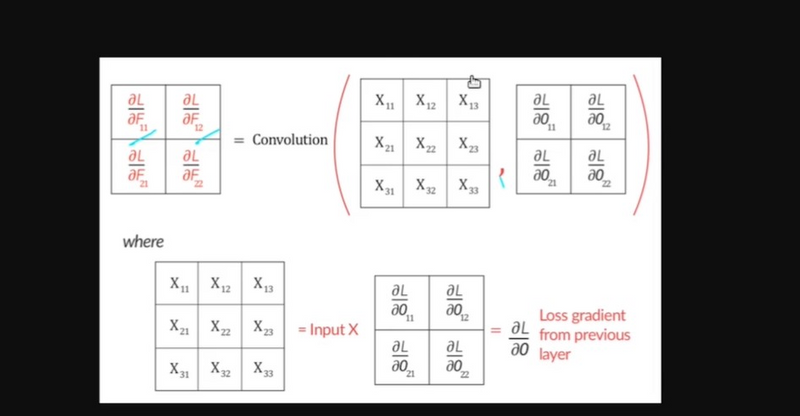
Move backward through the network, layer by layer, to calculate the gradients at each layer. The gradients are calculated based on the gradients from the subsequent layer using the chain rule.
Update Weights and Biases:
For each layer, the gradients are used to update the weights and biases. The update is performed in the opposite direction of the gradient, which reduces the loss.
The update rule is typically of the form: parameter_new = parameter_old - learning_rate * gradient, where the learning rate controls the size of the updates.
Example:
Let's consider a simple feedforward neural network for binary classification:
Input Layer: Two features (X1 and X2).
Hidden Layer: One neuron with a sigmoid activation function.
Output Layer: One neuron with a sigmoid activation function.
Forward Pass:
- Input data (X1, X2) is passed through the network.
- Each neuron calculates the weighted sum of its inputs, applies the sigmoid activation function, and produces an output.
The output is compared to the true target value, and the loss (e.g., binary cross-entropy) is computed
.
Backward Pass (Backpropagation):Calculate the gradient of the loss with respect to the output neuron's output. This gradient indicates how the output should change to minimize the loss.
Backpropagate this gradient to the hidden layer, calculating the gradient of the loss with respect to the hidden layer's output.
Update the weights and biases of both the output and hidden layers using the gradients and the learning rate
.
The process is repeated for multiple epochs, iteratively adjusting the network's parameters to reduce the loss. Over time, the network learns to make better predictions by updating its weights and biases based on the errors it made during training.
How backpropogation minimize loss
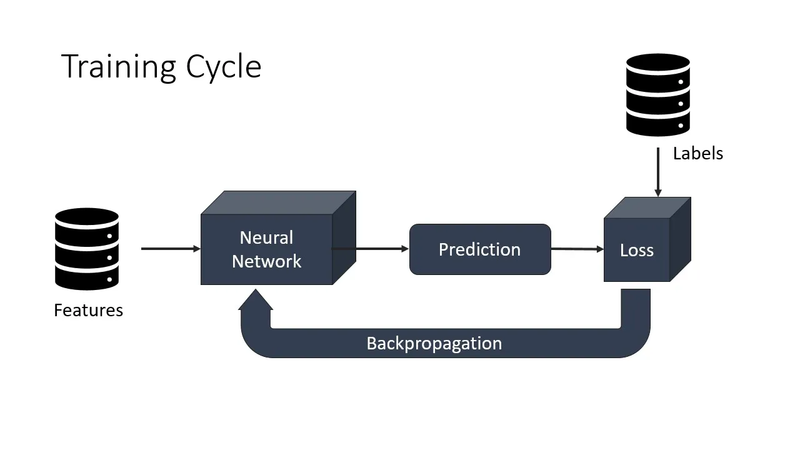
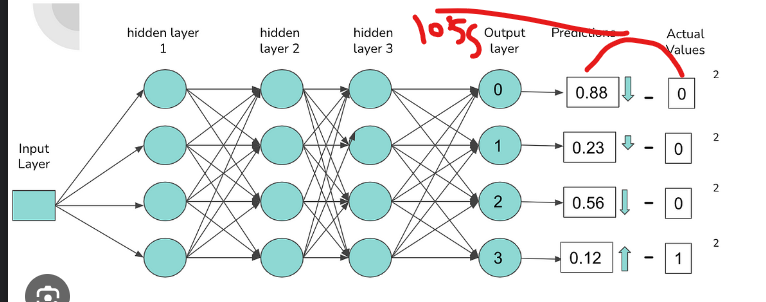
Backpropagation minimizes the loss in a neural network by iteratively adjusting the network's parameters (weights and biases) in the direction that reduces the loss. Let's explore how backpropagation achieves this with a real example:
Example: Binary Classification with a Single Neuron
Suppose you have a neural network with a single neuron for binary classification. The network takes two input features (X1 and X2) and produces a binary output (0 or 1). The network's goal is to correctly classify examples into two classes, and you're using the binary cross-entropy loss as the loss function.
Steps of Backpropagation:
Initialization:
Initialize the network's weights and biases with small random values.
Forward Pass:
Take an example from your dataset (X1, X2) and feed it through the network.
Calculate the weighted sum of the inputs, apply the sigmoid activation function, and obtain an output between 0 and 1.
Compute Loss:
Compare the network's output to the true target label (0 or 1) for that example.
Calculate the loss using the binary cross-entropy loss function.
Backward Pass (Backpropagation):
1.Calculate the gradient of the loss with respect to the network's output. This gradient indicates how much the output should change to minimize the loss.
2.Propagate this gradient backward to the sigmoid activation function in the output neuron, calculating the gradient with respect to the weighted sum (z) of the neuron.
3.Continue propagating the gradient further backward to the weights and bias of the output neuron and update them using the gradient and a learning rate.
4.Use the chain rule to calculate the gradient of the loss with respect to the neuron's weighted sum.
5.Continue backpropagating this gradient to the weights and bias of the hidden layer neuron and update them using the chain rule and learning rate.
Iteration:
Repeat steps 2 to 4 for each example in your dataset.
Calculate the average loss over all examples in the dataset.
Update Parameters:
Adjust the weights and biases in the direction that reduces the loss. For each parameter, update it using the formula: parameter_new = parameter_old - learning_rate * gradient.
Repeat:
Repeat steps 2 to 6 for a specified number of iterations (epochs).
As you continue this process over multiple epochs, the network learns to make better predictions. Backpropagation guides the network to update its weights and biases in a way that minimizes the loss, making the predictions more accurate. With each epoch, the loss generally decreases, and the network becomes better at classifying examples correctly.
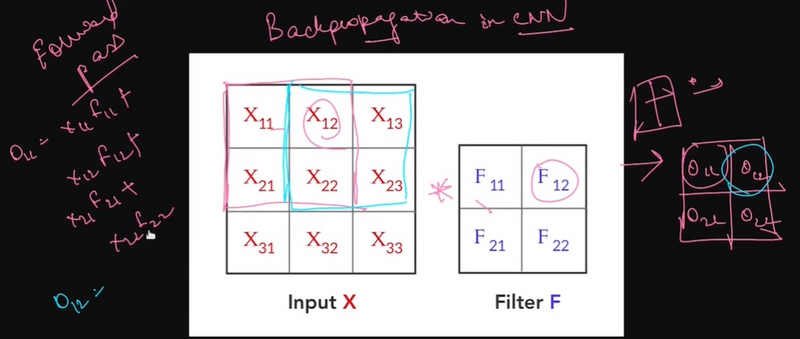
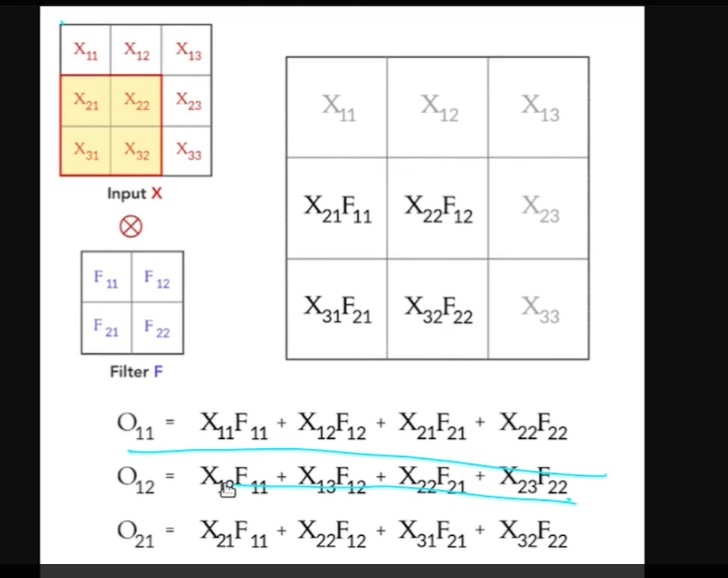
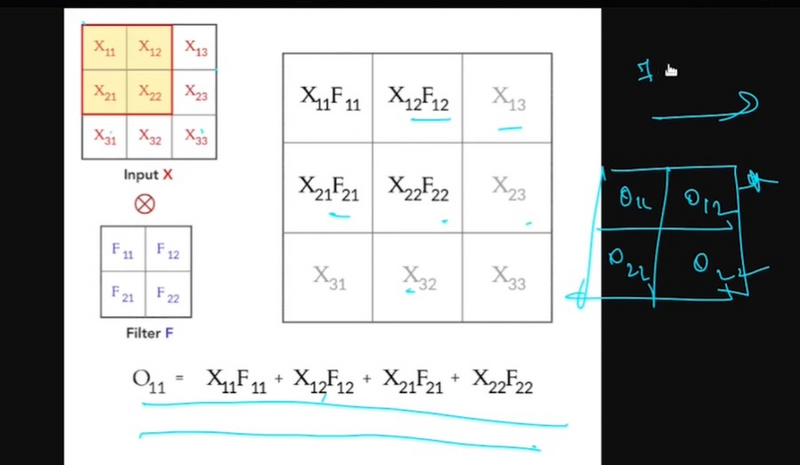
explain chain rule of differentiation
note
1 epoc=1 forward + 1 backward



In summary, the chain rule allows you to find the derivative of a composite function by multiplying the derivatives of the individual functions involved and taking into account how they depend on each other. It's a crucial tool in calculus and plays a significant role in various fields of mathematics and science.











Top comments (0)