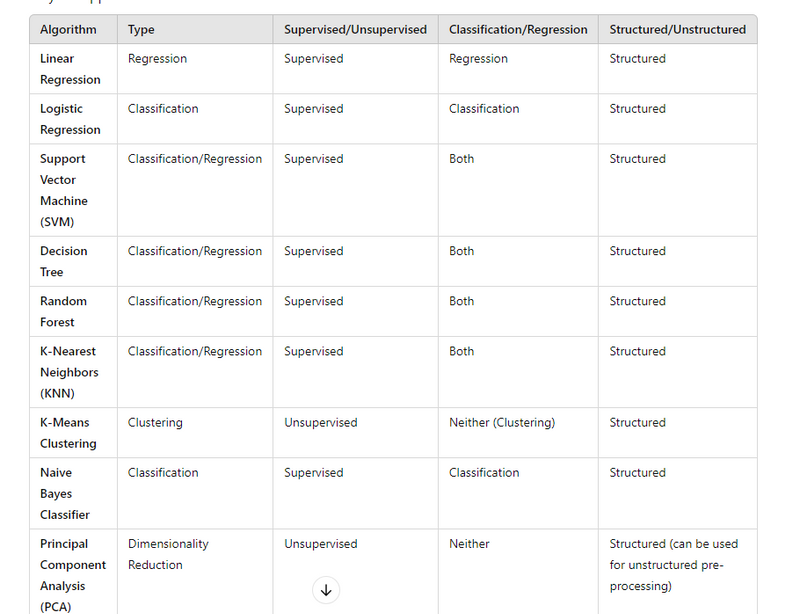
Linear Regression:
Type: Regression
Supervised: The model learns from labeled data.
Usage: Used for predicting continuous variables (e.g., predicting house prices).
Data: Typically used for structured data (tabular data).
Logistic Regression:
Type: Classification
Supervised: The model learns from labeled data.
Usage: Used for binary classification (e.g., spam detection).
Data: Used for structured data.
Support Vector Machine (SVM):
Type: Can be used for both classification and regression (Support Vector Regression for regression).
Supervised: The model learns from labeled data.
Usage: Classifies data by finding the optimal hyperplane that separates classes; can also be used for regression.
Data: Mostly used for structured data.
Decision Tree:
Type: Both classification and regression.
Supervised: The model learns from labeled data.
Usage: Works by splitting data into decision nodes, used for both classification (e.g., medical diagnosis) and regression.
Data: Structured data.
Random Forest:
Type: Both classification and regression.
Supervised: The model learns from labeled data.
Usage: An ensemble of decision trees that improves prediction by reducing variance.
Data: Used for structured data.
K-Nearest Neighbors (KNN):
Type: Both classification and regression.
Supervised: The model uses labeled data, but makes predictions based on the proximity (distance) to other data points.
Usage: For classification (e.g., image recognition) and regression (e.g., house price prediction).
Data: Structured data.
K-Means Clustering:
Type: Clustering (groups data into clusters based on similarity).
Unsupervised: The model does not require labeled data.
Usage: For clustering tasks, such as customer segmentation.
Data: Typically used with structured data.
Naive Bayes Classifier:
Type: Classification.
Supervised: The model learns from labeled data using Bayes' Theorem.
Usage: Used for text classification (e.g., spam detection).
Data: Structured data, often with categorical features.
Principal Component Analysis (PCA):
Type: Dimensionality reduction.
Unsupervised: No labeled data required.
Usage: Reduces the dimensionality of large datasets while retaining most of the variance.
Data: Primarily structured data, but can also be applied as a pre-processing step for unstructured data like images.

Top comments (0)