Explain AdaBoost technique
when to use AdaBoost technique
Boosting is a machine learning ensemble technique that combines the predictions of multiple weak learners (often decision trees) to create a strong predictive model. There are several variations of boosting techniques, each with its own characteristics and advantages. Here are some of the most common types of boosting techniques, along with examples:
AdaBoost (Adaptive Boosting):
- AdaBoost assigns weights to training instances and focuses on misclassified instances by giving them higher weights in subsequent iterations. It combines the weighted predictions of weak learners to create a strong classifier.
- Example: Classifying emails as spam or not spam, where each email is represented as a set of features, and AdaBoost combines multiple decision stumps (shallow trees) to make the final prediction
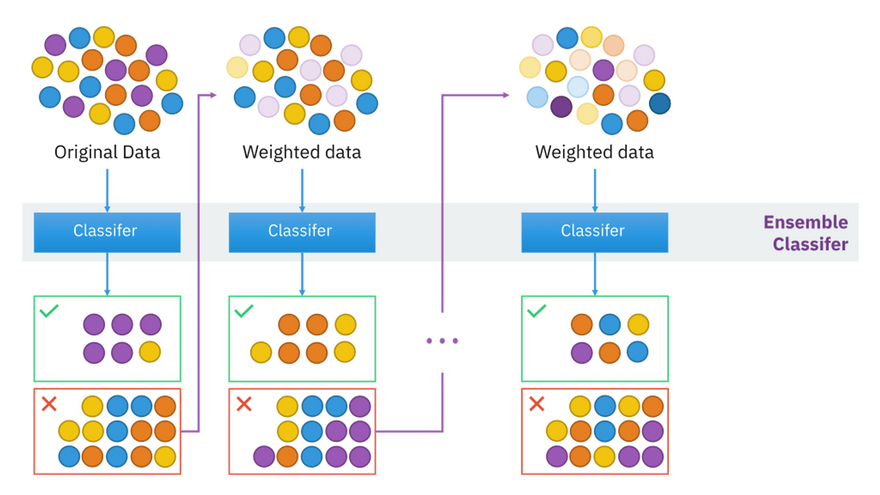
.AdaBoost (Adaptive Boosting) is a machine learning ensemble technique that combines the predictions of multiple weak learners (usually decision trees or other simple models) to create a strong and accurate predictive model. It assigns different weights to training instances, focusing more on the ones that were misclassified by previous models. Here's how AdaBoost works with a simple example in Python using the scikit-learn library:
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Generate a synthetic dataset
X, y = make_classification(n_samples=100, n_features=2, random_state=42)
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a base classifier (a decision tree with depth 1)
base_classifier = DecisionTreeClassifier(max_depth=1)
# Create an AdaBoost classifier
adaboost_classifier = AdaBoostClassifier(base_classifier, n_estimators=50, random_state=42)
# Train the AdaBoost classifier on the training data
adaboost_classifier.fit(X_train, y_train)
# Make predictions on the test data
y_pred = adaboost_classifier.predict(X_test)
# Calculate the accuracy of the AdaBoost classifier
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
In this example:
1.We generate a synthetic dataset with two features (X) and binary labels (y) using make_classification.
2.We split the dataset into training and testing sets using train_test_split.
3.We create a weak learner as the base classifier, which is a decision tree with a maximum depth of 1. This simple classifier is often referred to as a "stump."
4.We create an AdaBoost classifier that uses the base classifier and specify the number of estimators (in this case, 50), which are the weak classifiers to be combined.
5.We train the AdaBoost classifier on the training data using the fit method.
6.We use the trained AdaBoost classifier to make predictions on the test data.
7.Finally, we calculate the accuracy of the AdaBoost classifier using the accuracy_score function from scikit-learn.
AdaBoost assigns different weights to each training instance based on whether it was correctly or incorrectly classified by the previous weak classifiers. It focuses more on the misclassified instances, allowing it to iteratively improve its performance. The final prediction is made by combining the weighted predictions of all weak learners.
AdaBoost is particularly useful when dealing with complex datasets and can be applied to various classification problems to improve accuracy.
when to use adaboost technique in ml
AdaBoost (Adaptive Boosting) is a versatile machine learning ensemble technique that can be effective in a wide range of scenarios. Here are some situations where AdaBoost can be particularly useful in machine learning:
Classification Tasks: AdaBoost is primarily designed for classification problems. It excels when you have a binary or multiclass classification problem and can be used with a variety of weak classifiers, such as decision trees, as its base model.
Imbalanced Datasets: When dealing with imbalanced datasets where one class has significantly fewer examples than the other, AdaBoost can help improve the classification of the minority class by focusing on the misclassified instances from that class.
Weak Learners: AdaBoost is effective when you have weak learners or simple models as base classifiers. It can boost their performance by combining them into a strong ensemble.
Text and Natural Language Processing (NLP): AdaBoost can be used for text classification tasks like sentiment analysis or spam detection when combined with appropriate text processing techniques.
Face Detection: AdaBoost has historically been used in computer vision for face detection, where it can help identify facial features within an image.
Real-world Applications: AdaBoost is suitable for practical applications such as credit scoring, fraud detection, medical diagnosis, and customer churn prediction.
Ensemble Model Improvement: AdaBoost can be used in combination with other ensemble techniques like Random Forests or Gradient Boosting to further enhance model performance.
Data with Noise or Outliers: AdaBoost is robust to noisy data, and its sequential learning process can help reduce the impact of outliers.
Interpretable Models: Unlike some complex ensemble techniques, AdaBoost often produces relatively simple models (e.g., shallow decision trees), which can be easier to interpret, making it a good choice when model interpretability is essential.
When Speed is Not the Primary Concern: While AdaBoost can be computationally intensive due to its sequential nature, it may still be suitable for applications where real-time processing is not a strict requirement.
However, there are situations where AdaBoost may not be the best choice:
Large Datasets: AdaBoost can become computationally expensive on very large datasets because it sequentially trains multiple models.
Noisy Data: While AdaBoost is somewhat robust to noisy data, excessive noise or outliers can still negatively affect its performance.
Highly Imbalanced Datasets: In cases of extreme class imbalance, AdaBoost may not be sufficient on its own, and additional techniques like resampling or modifying class weights may be necessary.
Regression Problems: AdaBoost is primarily designed for classification tasks. For regression problems, Gradient Boosting (e.g., XGBoost, LightGBM) is typically a better choice.
In summary, AdaBoost is a valuable technique for classification tasks, particularly when dealing with weak learners, imbalanced data, and problems where interpretability is crucial. However, its appropriateness depends on the specific characteristics of your dataset and problem domain. Always consider experimenting with different algorithms to determine which one performs best for your particular use case.
Gradient Boosting:
- Gradient Boosting builds an ensemble of decision trees sequentially, with each tree correcting the errors made by the previous ones. It uses gradient descent optimization to minimize a loss function.
Example: Predicting housing prices based on features like square footage, number of bedrooms, and location. Gradient Boosting regressors like XGBoost or LightGBM can be used to build a strong regression model
.
Extreme Gradient Boosting (XGBoost):XGBoost is an optimized version of Gradient Boosting that incorporates regularization techniques and parallel processing, making it efficient and powerful. It's widely used in Kaggle competitions and real-world applications.
Example: Identifying fraudulent transactions in credit card data by combining XGBoost classifiers
.
Light Gradient Boosting Machine (LightGBM):LightGBM is another efficient gradient boosting variant known for its speed and memory efficiency. It uses a histogram-based approach for tree building.
Example: Customer churn prediction in a telecom company, where LightGBM can be used to build a classification model
.
CatBoost:CatBoost is a boosting algorithm developed by Yandex, designed to handle categorical features efficiently. It automatically encodes categorical variables and is robust to overfitting.
Example: Predicting click-through rates in online advertising, where there are many categorical features like user IDs and ad campaign IDs
.
Stochastic Gradient Boosting (SGDBoost):SGDBoost combines elements of stochastic gradient descent and boosting to train weak learners. It updates the weights of training instances in a manner similar to AdaBoost.
Example: Identifying diseases based on medical test results, where SGDBoost can be used to create a diagnostic model
.
BrownBoost:BrownBoost is a variant of AdaBoost that uses the minimum margin of misclassified instances as a measure to assign weights. It's less sensitive to noisy data compared to AdaBoost.
Example: Detecting defects in manufacturing processes, where BrownBoost can be used to improve the accuracy of defect detection
.
LPBoost (Linear Programming Boosting):LPBoost combines boosting with linear programming to optimize the coefficients of weak learners. It's suitable for problems with linear separability.
Example: Text classification tasks, such as sentiment analysis, where LPBoost can be applied to linearly separate positive and negative sentiment
s.

Top comments (0)