Explain Ensemble approach
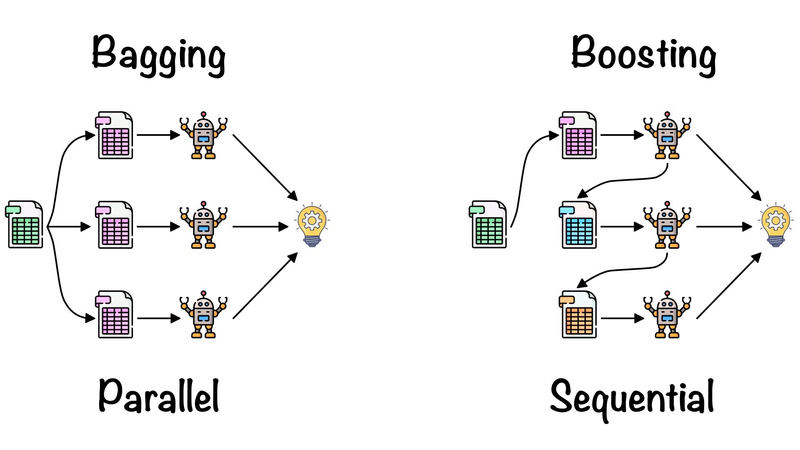
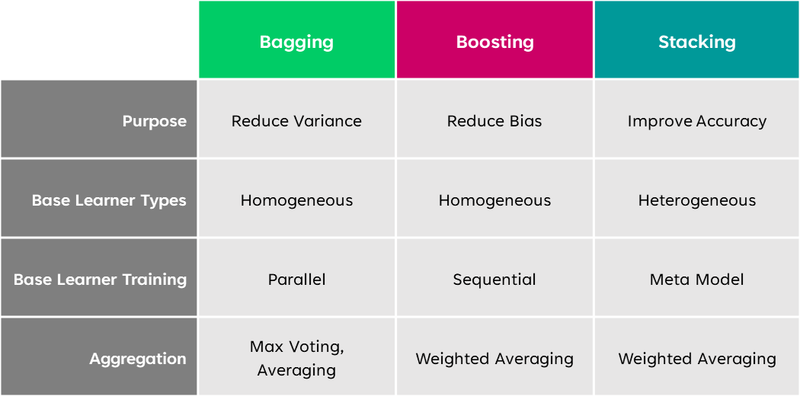
Difference between bagging and Boosting Approach
Explain AdaBoost (Adaptive Boosting)
Explain Pros and cons of Boosting Approach
Ensemble learning is a powerful machine learning technique that combines multiple individual models (learners) to create a more accurate and robust prediction model. The basic idea behind ensemble methods is that by combining multiple weak learners, the ensemble can achieve higher predictive performance than any individual learner alone. There are two main types of ensemble methods: bagging and boosting.
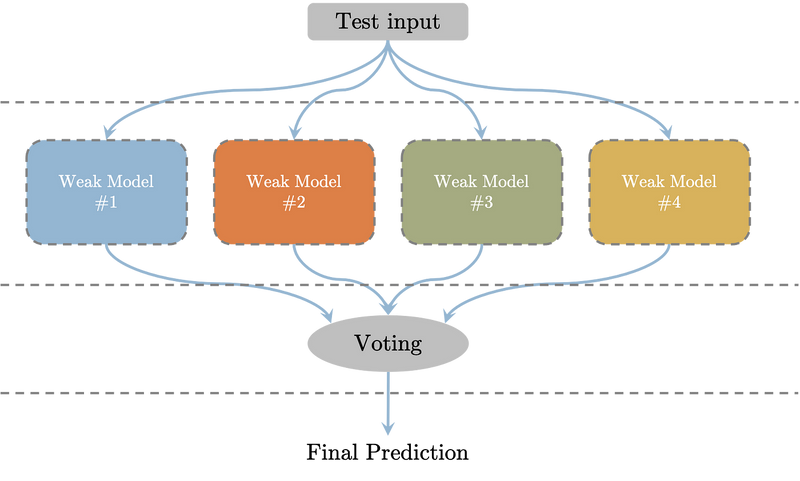
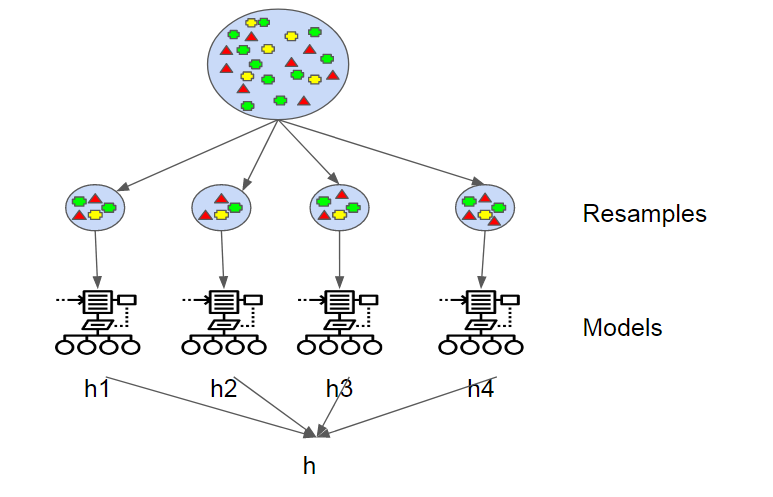
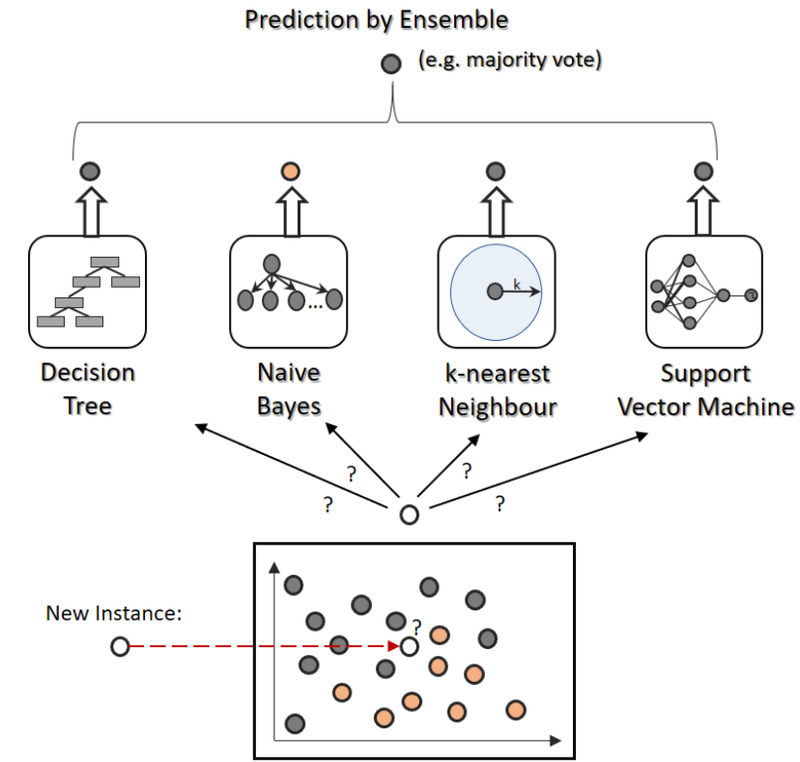
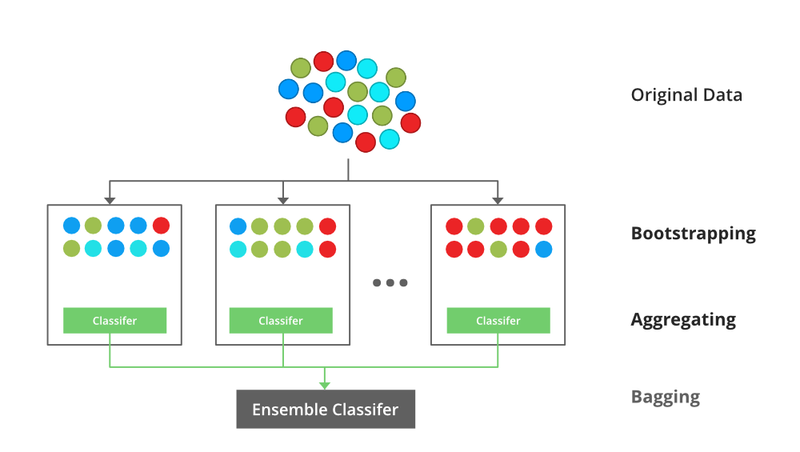
Bagging:
Bagging stands for Bootstrap Aggregating. In bagging, multiple learners are trained independently on different subsets of the training data, typically obtained by random sampling with replacement (bootstrap samples). The final prediction is made by aggregating the predictions of all individual models, such as taking a majority vote for classification tasks or averaging for regression tasks.
Example - Random Forest:
Random Forest is one of the most popular bagging ensemble methods. It combines multiple decision trees to create a more robust and accurate model. Each tree in the forest is trained on a different random subset of the training data and features. Let's see an example of Random Forest for a classification problem using scikit-learn:
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the Iris dataset
data = load_iris()
X, y = data.data, data.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Create a Random Forest classifier with 100 trees
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the classifier
rf_classifier.fit(X_train, y_train)
# Make predictions on the test set
y_pred = rf_classifier.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Random Forest Accuracy:", accuracy)
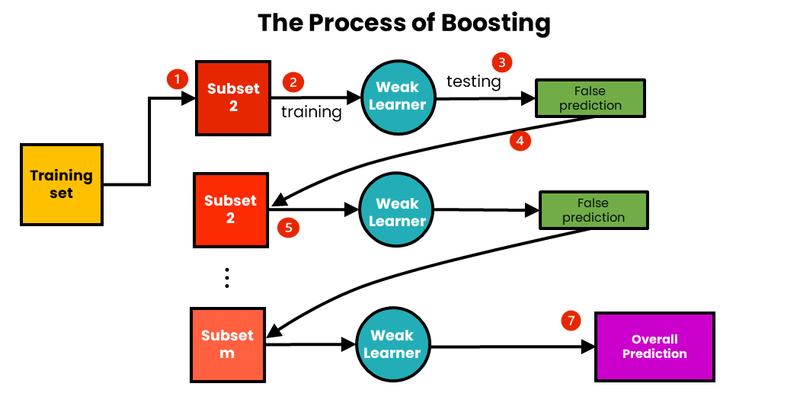
Boosting:
Boosting is another ensemble technique where learners are trained sequentially, and each learner tries to correct the errors of its predecessors. Boosting assigns higher weights to misclassified instances to focus on the hard-to-classify samples. The final prediction is a weighted combination of all the learners' predictions.
Example - AdaBoost (Adaptive Boosting):
AdaBoost is a popular boosting algorithm that iteratively trains weak learners, such as decision stumps (short decision trees with only one split). It gives more weight to misclassified samples in each iteration, leading to a more accurate model. Let's see an example of AdaBoost for a classification problem using scikit-learn:
from sklearn.ensemble import AdaBoostClassifier
# Create an AdaBoost classifier with 50 decision stumps as weak learners
adaboost_classifier = AdaBoostClassifier(n_estimators=50, random_state=42)
# Train the classifier
adaboost_classifier.fit(X_train, y_train)
# Make predictions on the test set
y_pred = adaboost_classifier.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("AdaBoost Accuracy:", accuracy)
In this example, the AdaBoost algorithm combines multiple decision stumps to create a more accurate classification model.
Ensemble methods like Random Forest and AdaBoost are widely used because they can significantly improve the performance of machine learning models, handle complex relationships in data, and reduce overfitting. They are especially effective when the individual learners are diverse and capable of capturing different patterns in the data.
When to use Ensamble Approach
Ensemble approaches are powerful techniques that can significantly improve the performance of machine learning models in various scenarios. Here are some situations when ensemble methods are particularly useful:
High Variance Models: Ensemble methods are effective in reducing the variance of a model, especially when dealing with complex or high-dimensional data. Individual models (learners) in an ensemble may have high variance, but by combining them, the ensemble can achieve a more stable and accurate prediction.
Low Bias, High Variance Trade-off: When dealing with learning algorithms that have low bias but high variance (e.g., decision trees), ensemble methods can strike a balance by reducing the overall variance while retaining the individual learners' low bias.
Improving Model Accuracy: If the individual models perform reasonably well on their own, combining them through ensemble methods can lead to even better predictive accuracy. Ensemble methods often outperform single models, especially when there are diverse and independent learners.
Handling Noisy Data: Ensemble methods are robust to noisy data, as they can aggregate predictions from multiple models, which helps reduce the impact of outliers or noisy instances.
Handling Imbalanced Data: In classification tasks with imbalanced classes, where one class significantly outnumbers the others, ensemble methods can help improve the performance by giving more weight to the minority class.
Outlier Detection: In outlier detection tasks, ensembles can be used to identify outliers that deviate significantly from the majority of the data.
Model Stability: Ensemble methods can improve model stability, as they are less sensitive to changes in the training data or random initialization of parameters.
Handling Complex Relationships: Ensembles can capture complex relationships in the data, especially when individual learners have different perspectives on the patterns in the data.
Despite their effectiveness, ensemble methods may not always be the best choice. Here are some considerations:
Computational Complexity: Ensemble methods may require more computational resources and training time compared to single models.
Model Interpretability: Ensembles can be harder to interpret than single models, especially when combining different types of learners.
Overfitting: While ensembles can reduce overfitting, they may still be susceptible to overfitting if the individual models are overfitted themselves.

Pros and Cons of Boosting Technique
Boosting is a machine learning ensemble technique that combines the predictions from multiple weak learners (typically decision trees) to create a strong predictive model. It aims to improve the overall model performance by sequentially training weak models on the errors made by the previous ones. Below are the pros and cons of boosting, along with examples:
Pros of Boosting:
Improved Predictive Accuracy:
Example: Boosting can be used for tasks like image classification. Each weak learner focuses on classifying difficult-to-distinguish examples, gradually improving the model's accuracy.
Handles Complex Relationships:
Example: In financial fraud detection, boosting can capture intricate patterns in transaction data to identify fraudulent activities.
Reduced Overfitting:
Example: In healthcare, boosting can be employed to predict patient outcomes. By sequentially fitting models, boosting can help reduce overfitting to noisy data.
Feature Importance Estimation:
Example: In e-commerce, boosting can be used to predict customer preferences. The feature importance scores obtained from boosting can help identify which product attributes influence buying decisions the most.
Versatility with Weak Learners:
Example: Boosting is compatible with various weak learners, including decision stumps (shallow trees), which can be useful for text classification tasks, such as sentiment analysis.
Cons of Boosting:
Sensitivity to Noisy Data:
Example: In a spam email classification task, boosting may overemphasize noisy features if not properly tuned, leading to poor generalization.
Computationally Intensive:
Example: In real-time applications like autonomous vehicles, boosting may be too computationally expensive due to its sequential nature.
Risk of Overfitting:
Example: In stock market prediction, boosting can overfit to historical data if not carefully regularized, resulting in poor performance on unseen data.
Difficulty in Interpreting Models:
Example: In legal cases, where explanations are required, the complex ensemble of models generated by boosting can be challenging to interpret.
Sensitive to Outliers:
Example: In credit scoring, boosting may give undue importance to outliers, potentially leading to suboptimal credit risk assessments.
Parameter Tuning Complexity:
Example: In natural language processing for sentiment analysis, selecting the right hyperparameters for boosting can be challenging and time-consuming.
In summary, boosting is a powerful ensemble technique that can significantly enhance predictive performance but requires careful tuning and consideration of its potential downsides, particularly in scenarios where interpretability and computational efficiency are crucial. Its success often depends on the nature of the data and the problem being addressed.

Top comments (0)