concept of epoc,batch size,steps
how epoc,steps and batch size determine trining losses,validation losses in neural network
how epoc,steps and batch size determine training accuracy and validation accuracy in neural network
Neural Networks
A neural network is a supervised machine learning algorithm. We can train neural networks to solve classification or regression problems. Yet, utilizing neural networks for a machine learning problem has its pros and cons.
Building a neural network model requires answering lots of architecture-oriented questions. Depending on the complexity of the problem and available data, we can train neural networks with different sizes and depths. Furthermore, we need to preprocess our input features, initialize the weights, add bias if needed, and choose appropriate activation functions.
- Epoch in Neural Networks An epoch means training the neural network with all the training data for one cycle. In an epoch, we use all of the data exactly once. A forward pass and a backward pass together are counted as one pass:
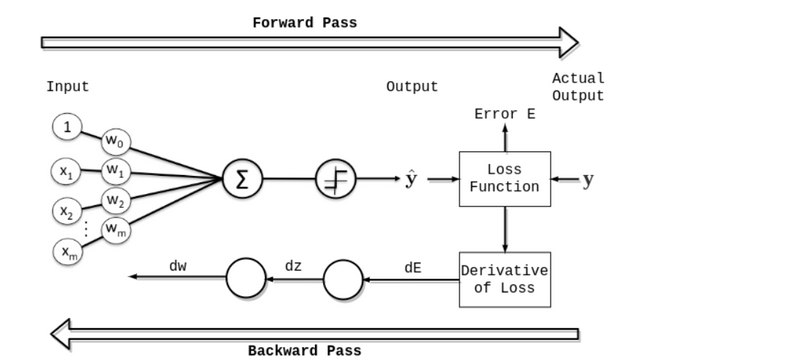
epoch fwd bwd pass
An epoch is made up of one or more batches, where we use a part of the dataset to train the neural network. We call passing through the training examples in a batch an iteration.
An epoch is sometimes mixed with an iteration. To clarify the concepts, let’s consider a simple example where we have 1000 data points as presented in the figure below:
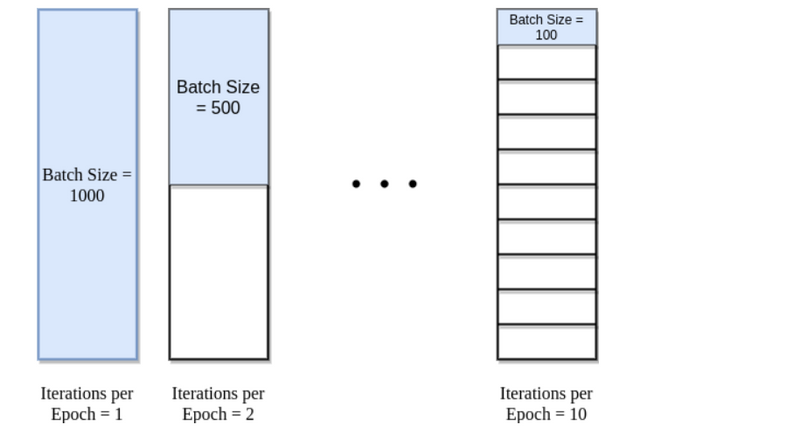
epoch batch size
If the batch size is 1000, we can complete an epoch with a single iteration. Similarly, if the batch size is 500, an epoch takes two iterations. So, if the batch size is 100, an epoch takes 10 iterations to complete. Simply, for each epoch, the required number of iterations times the batch size gives the number of data points.
We can use multiple epochs in training. In this case, the neural network is fed the same data more than once.
- Neural Network Training Convergence Deciding on the architecture of a neural network is a big step in model building. Still, we need to train the model and tune more hyperparameters on the way.
During the training phase, we aim to minimize the error rate as well as to make sure that the model generalizes well on new data. The bias-variance tradeoff is still a potential pitfall we want to avoid, as in other supervised machine learning algorithms.
freestar
We face overfitting (high variance) when the model fits perfectly to the training examples but has limited capability
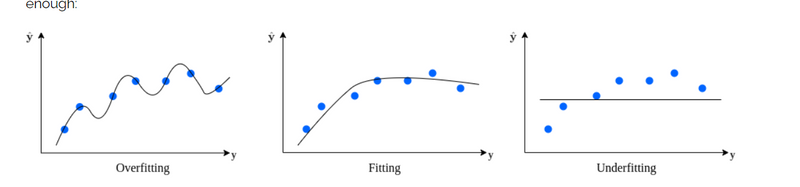
generalization. On the other hand, if the model is said to be underfitting (high bias) if it didn’t learn the data well enough:
epoch bias variance
A good model is expected to capture the underlying structure of the data. In other words, it does not overfit or underfit.
When building a neural network model, we set the number of epochs parameter before the training starts. However, initially, we can’t know how many epochs is good for the model. Depending on the neural network architecture and data set, we need to decide when the neural network weights are converged.
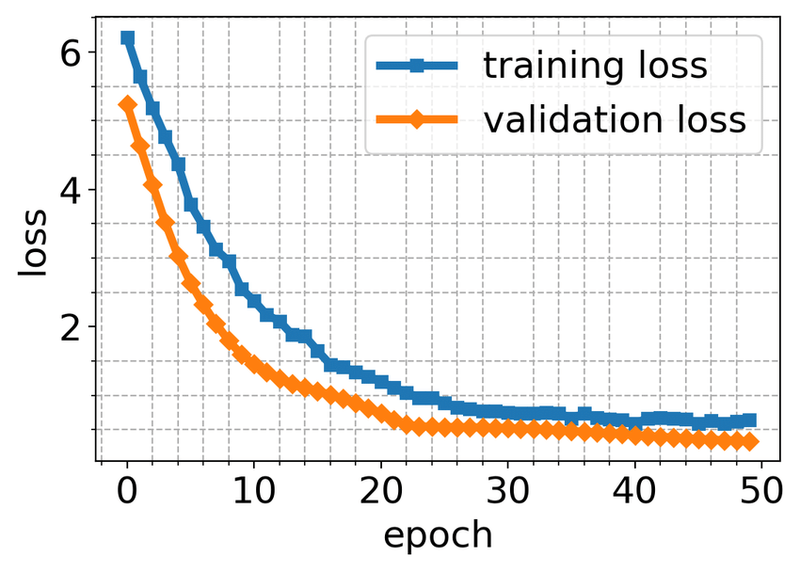
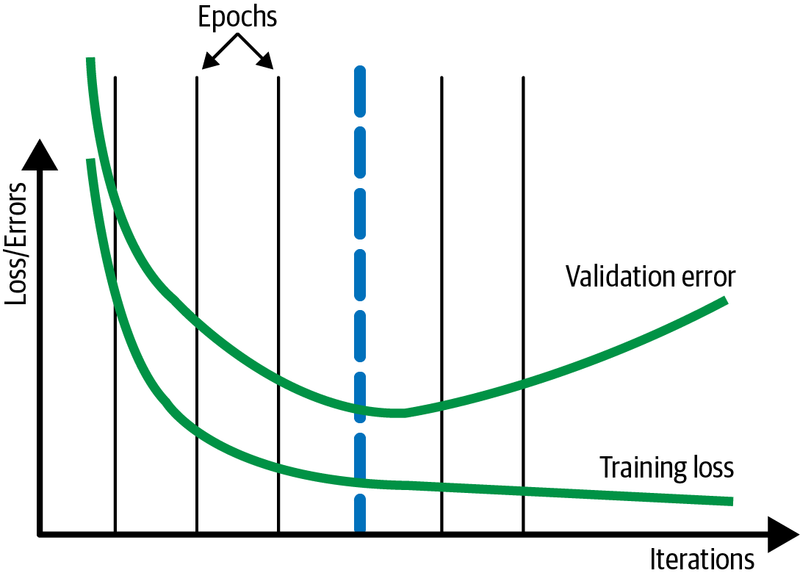
For neural network models, it is common to examine learning curve graphs to decide on model convergence. Generally, we plot loss (or error) vs. epoch or accuracy vs. epoch graphs. During the training, we expect the loss to decrease and accuracy to increase as the number of epochs increases. However, we expect both loss and accuracy to stabilize after some point.
As usual, it is recommended to divide the data set into training and validation sets. By doing so, we can plot learning curve graphs for different sets. These graphs help us diagnose if the model has over-learned, under-learned, or fits the learning set.
We expect a neural network to converge after training for a number of epochs. Depending on the architecture and data available, we can treat the number of epochs to train as a hyperparameter.
Neural network weights are updated iteratively, as it is a gradient descent based algorithm. A single epoch in training is not enough and leads to underfitting. Given the complexity of real-world problems, it may take hundreds of epochs to train a neural network.
As a result, we expect to see the learning curve graphs getting better and better until convergence. Then if we keep training the model, it will overfit, and validation errors begin to increase:
epoch training curve
Training a neural network takes a considerable amount of time, even with the current technology. In the model-building phase, if we set the number of epochs too low, then the training will stop even before the model converges. Conversely, if we set the number of epochs too high, we’ll face overfitting. On top of that, we’ll waste computing power and time.
A widely adopted solution to this problem is to use early stopping. It is a form of regularization.
As the name suggests, the main idea in early stopping is to stop training when certain criteria are met. Usually, we stop training a model when generalization error starts to increase (model loss starts to increase, or accuracy starts to decrease). To decide on the change in generalization errors, we evaluate the model on the validation set after each epoch.
By utilizing early stopping, we can initially set the number of epochs to a high number. This way, we ensure that the resulting model has learned from the data. Once the training is complete, we can always check the learning curve graphs to make sure the model fits well.
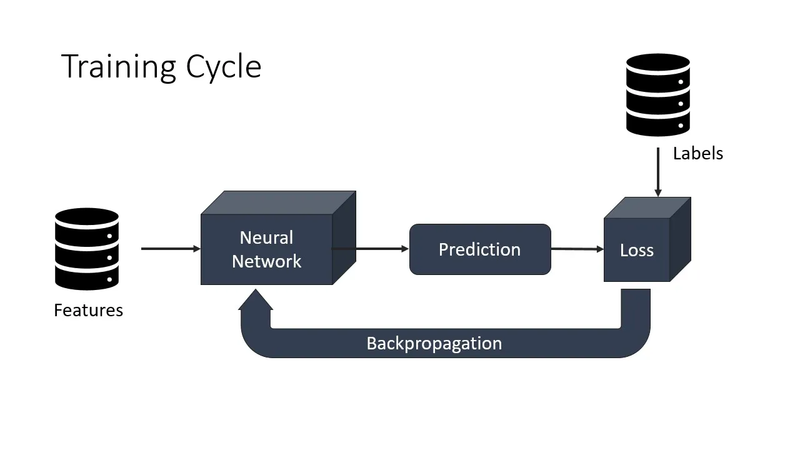
In machine learning, the process of training a neural network involves updating the weights and biases of the network based on the training data. The parameters that control the training process, such as the number of epochs and the batch size, play an important role in how the model learns from the data.
Epochs:
An epoch is a single pass through the entire training dataset. During each epoch, the model processes the training data, calculates the loss, and updates the model's parameters (weights and biases) based on the optimization algorithm used. By specifying the number of epochs, you determine how many times the model will iterate over the entire training dataset.
Batch Size:
The batch size refers to the number of training examples (samples) processed in a single iteration. In each iteration, the model computes the loss and updates the parameters using the gradients computed from a batch of training examples. The batch size determines the number of samples used to estimate the gradient before each weight update.
The choice of the batch size and the number of epochs can affect the model's training dynamics, convergence speed, and generalization performance. Here are some considerations:
- Larger batch sizes provide a more accurate estimate of the gradient but require more memory and computational resources.
- Smaller batch sizes introduce more noise into the gradient estimation but allow for more frequent weight updates and faster convergence.
- The number of epochs should be set to an appropriate value based on the complexity of the problem and the convergence behavior of the model. It should be large enough to ensure that the model has sufficient iterations to learn the patterns in the data but not too large to risk overfitting . In the example
model.fit(X_train, y_train, epochs=100, batch_size=2),
the model will be trained for 100 epochs, meaning it will iterate over the entire training dataset 100 times. The batch size is set to 2, indicating that the model will update its parameters after processing 2 training examples in each iteration.
These values can be adjusted based on the specific problem, dataset size, and available computational resources to find the right balance between accuracy, convergence speed, and resource efficiency.
In the context of training a neural network, "epoch," "steps," and "batch size" are essential concepts that determine how the model is trained on the dataset. Here's an explanation of each concept with examples:
Epoch:
An epoch is a complete pass through the entire training dataset. In one epoch, the model is exposed to and trained on each example in the dataset once. The number of epochs specifies how many times the model goes through the entire dataset.
Example: If you have 1,000 training examples and you set the number of epochs to 10, the model will see all 1,000 examples ten times during training.
Steps per Epoch:
Steps per epoch defines how many batches of data are processed in one epoch. It's often used when the dataset is large, and it may not be efficient to process the entire dataset in one pass. By specifying the steps per epoch, you can control the number of batches processed.
Example: If you have 1,000 training examples and a batch size of 32, you would have 1,000 / 32 = 31.25 batches per epoch. You can specify steps_per_epoch=31 to process 31 batches in one epoch.
Batch Size:
The batch size determines how many training examples are used in each update of the model's weights. Using mini-batches rather than the entire dataset for each update makes the training process more computationally efficient and often helps improve convergence.
Example: If you have 1,000 training examples and set the batch size to 32, the model will process 32 examples at a time before updating the weights during each training step.
Example:
Let's put these concepts together in a Python code example using TensorFlow/Keras to train a neural network with epochs, steps per epoch, and batch size:
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
# Generate synthetic data
X = np.random.rand(1000, 2)
y = 3 * X[:, 0] + 4 * X[:, 1] + 1 + 0.1 * np.random.randn(1000)
# Define a simple feedforward neural network
model = Sequential()
model.add(Dense(1, input_dim=2, activation='linear'))
# Compile the model
optimizer = SGD(learning_rate=0.01)
model.compile(optimizer=optimizer, loss='mean_squared_error')
# Set batch size and number of epochs
batch_size = 32
epochs = 10
steps_per_epoch = len(X) // batch_size
# Train the model
model.fit(X, y, epochs=epochs, batch_size=batch_size, steps_per_epoch=steps_per_epoch)
In this example:
- We generate synthetic data for a regression task.
- We define a simple neural network and compile it with a mean squared error loss function.
- We set the batch size to 32 and the number of epochs to 10.
- We calculate the steps_per_epoch based on the dataset size and the specified batch size.
- We train the model using these parameters, going through the dataset in batches for the specified number of epochs . The concept of epochs, steps, and batch size is essential for efficiently training neural networks on large datasets and controlling the training process. It allows you to find a balance between computational efficiency and model convergence.
how epoc,steps and batch size determine trining losses,validation losses in neural network
60,000 thousand data point, batch size--32
i 1st steps 32 data point go divide 60,000/32 that no of steps will go total no of epoc is 1
1875 steps
if no of epoc increses more accuracy is there
Epochs, steps, and batch size play a crucial role in determining the training losses and validation losses in a neural network. These parameters affect how the model is trained, how data is processed, and how learning occurs. Let's explore how they influence training and validation losses with an example:
Example: Let's consider a classification task with a neural network and a dataset of 1,000 examples. We'll investigate the impact of epochs, steps, and batch size on training and validation losses.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from sklearn.model_selection import train_test_split
# Generate synthetic data
X = np.random.rand(1000, 2)
y = ((X[:, 0] + X[:, 1]) > 1).astype(int)
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
# Define a simple feedforward neural network
model = Sequential()
model.add(Dense(1, input_dim=2, activation='sigmoid'))
# Compile the model
optimizer = SGD(learning_rate=0.01)
model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])
# Set batch size, epochs, and steps per epoch
batch_size = 32
epochs = 10
steps_per_epoch = len(X_train) // batch_size
# Train the model with varying parameters
model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, steps_per_epoch=steps_per_epoch, validation_data=(X_val, y_val))
In this example:
Epochs:
We set the number of epochs to 10. This means that the model will go through the entire training dataset 10 times during training. Each epoch is a complete pass through the data.
Steps per Epoch:
We calculate the steps per epoch based on the training dataset size and the batch size. In this case, we have 800 training examples and a batch size of 32, so there are 25 steps per epoch.
Batch Size:
We set the batch size to 32, which means that the model processes 32 training examples in each training step.
The combination of these parameters affects how training and validation losses change over time:
Training Loss: The training loss measures how well the model fits the training data. In each epoch, the training loss decreases as the model learns from the data. The choice of batch size and steps per epoch controls how often the model's parameters are updated.
Validation Loss: The validation loss measures how well the model generalizes to unseen data. It is computed at the end of each epoch using the validation dataset. A lower validation loss indicates better generalization. The number of epochs controls how many times the model is exposed to the entire training dataset.
Adjusting these parameters allows you to find a balance between underfitting (if too few epochs or steps) and overfitting (if too many epochs or steps) while optimizing model performance. Experimentation and monitoring of training and validation losses are critical to finding the right configuration for your specific problem.

Top comments (0)