In convolutional neural networks (CNNs), convolution is extended to handle multiple channels or 3D images (such as RGB images). The concept is based on 3D convolutional operations, where the convolutional filter has depth to account for the multiple channels in the input. Let's go through the steps of how convolution is done on a multi-channel or 3D image:
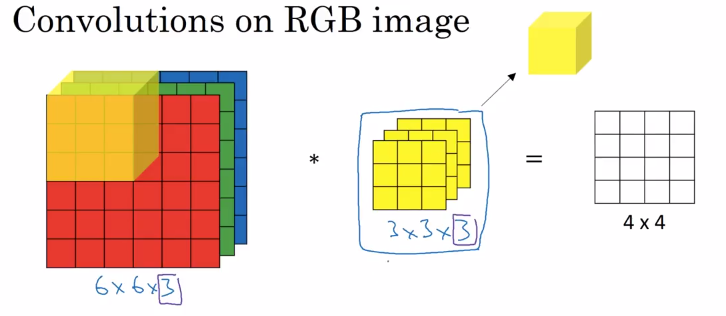
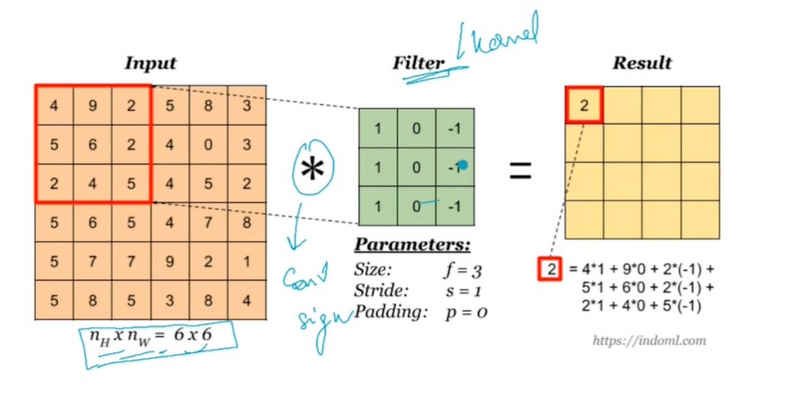
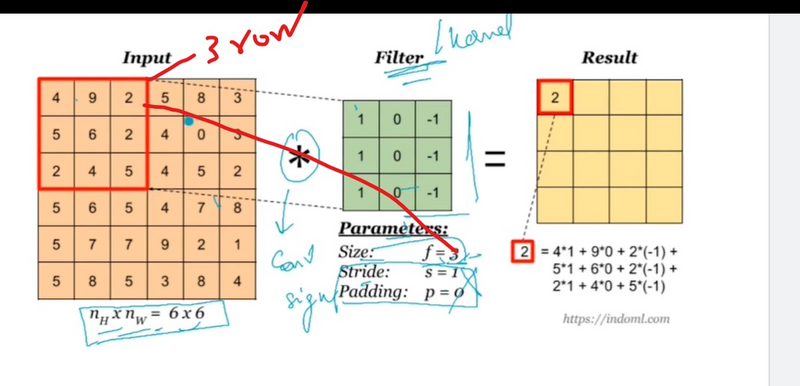
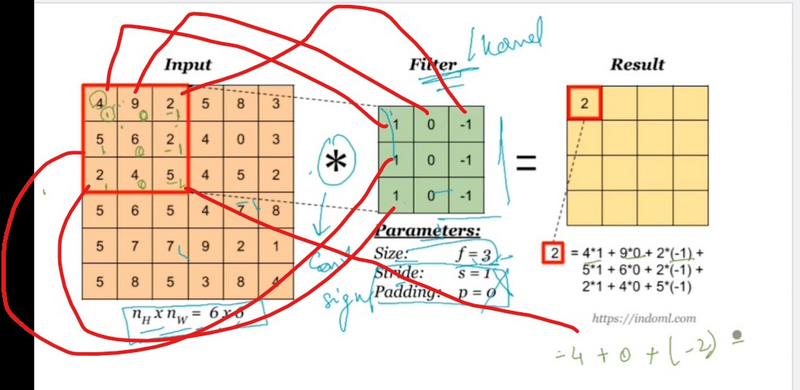
1. Input Data:
Consider a 3D image with dimensions (height, width, channels) or (H, W, C). Each channel represents a different feature or aspect of the input data.
2. Convolutional Filter:
The convolutional filter is also 3D with dimensions (filter_height, filter_width, input_channels, output_channels) or (FH, FW, C_in, C_out). The filter slides across the input volume to perform convolution.
3. Convolution Operation:
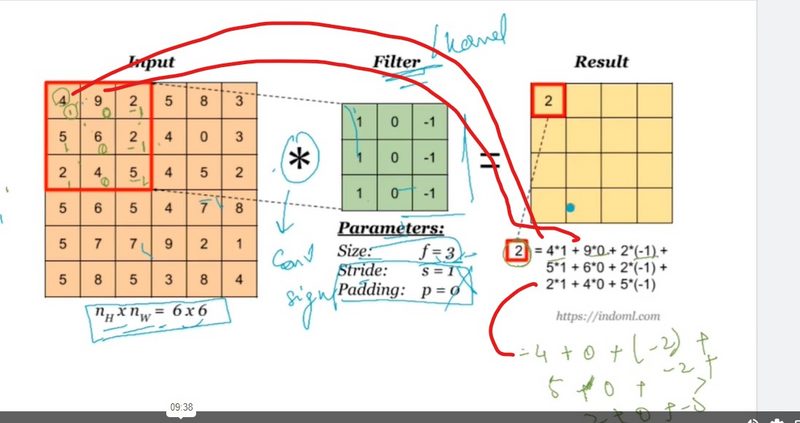
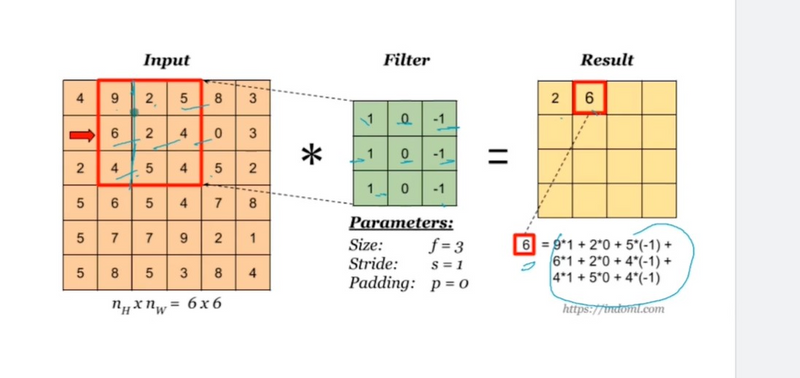
The convolution operation is performed by sliding the filter across the input image along the height, width, and depth dimensions.
At each position, the filter is element-wise multiplied with the corresponding region of the input volume, and the results are summed to obtain a single value in the output feature map.
4. Stride:
Similar to 2D convolution, a stride can be applied along the height, width, and depth dimensions, determining how much the filter moves at each step.
5. Bias and Activation:
A bias term is added to the result of each convolution, and an activation function (e.g., ReLU) is applied to introduce non-linearity.
Mathematical Representation:
The 3D convolution operation can be represented mathematically as follows

from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv3D
model = Sequential()
model.add(Conv3D(32, kernel_size=(3, 3, 3), input_shape=(64, 64, 64, 3), activation='relu'))

Top comments (0)