Web scraping is the process of extracting data from websites. It typically involves sending an HTTP request to a web page, downloading the HTML content of the page, and then parsing and extracting the desired information from the HTML. Below is a step-by-step example of how web scraping works in Python using the requests and BeautifulSoup libraries.

We'll scrape a simple example website with a list of books and their prices.
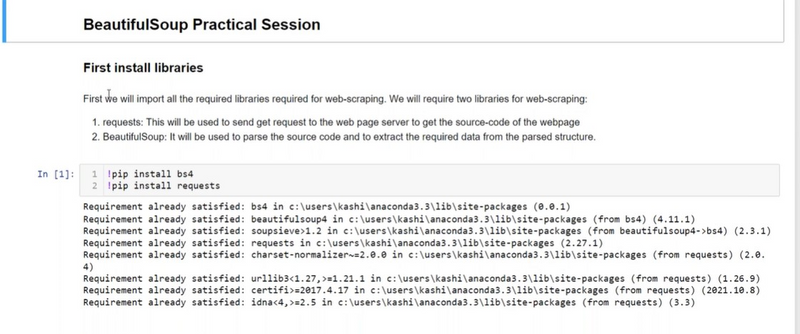
Step 1: Import Libraries
First, you need to import the necessary libraries. In this example, we'll use the requests library to fetch the web page's HTML content and BeautifulSoup for parsing the HTML.
import requests
from bs4 import BeautifulSoup

Step 2: Send an HTTP Request
You need to send an HTTP GET request to the URL of the web page you want to scrape. In this example, we'll use a sample URL.
url = "https://example.com/books" # Replace with the actual URL
response = requests.get(url)

Step 3: Check the Response
Check if the HTTP request was successful (status code 200). If it was not successful, handle the error appropriately.
if response.status_code == 200:
# Proceed with parsing the HTML content
else:
print("Failed to retrieve the web page. Status code:", response.status_code)
Step 4: Parse HTML Content
Use BeautifulSoup to parse the HTML content of the web page.
soup = BeautifulSoup(response.text, 'html.parser')
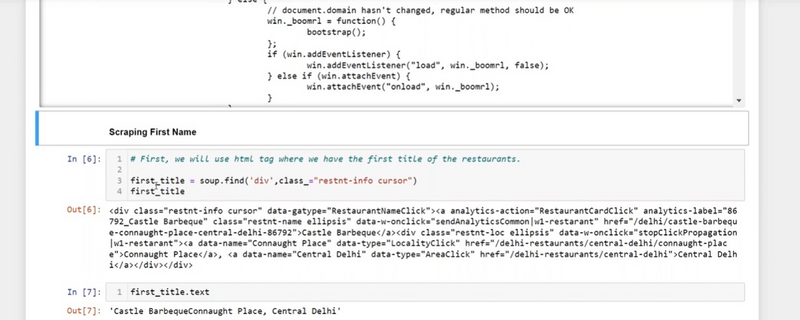
Step 5: Find and Extract Data
Now, you can use BeautifulSoup to find and extract specific data from the HTML content. You need to identify the HTML elements and their attributes that contain the data you want to scrape.
In our example, we'll extract the book titles and their corresponding prices.
# Find all the book title elements (modify this based on the website's structure)
book_titles = soup.find_all('h2', class_='book-title')
# Find all the price elements (modify this based on the website's structure)
prices = soup.find_all('span', class_='price')
# Iterate through the found elements and print the data
for title, price in zip(book_titles, prices):
print("Title:", title.text)
print("Price:", price.text)
print()
Step 6: Output or Store Data
You can choose to output the scraped data to the console, save it to a file, or store it in a database, depending on your project's requirements.
Step 7: Handle Pagination and Iteration
If the website has multiple pages of data, you may need to implement pagination and iterate through multiple pages to scrape all the desired data.
This example demonstrates the basic steps involved in web scraping using Python and BeautifulSoup. Keep in mind that web scraping should always be done responsibly and within the legal boundaries of a website's terms of service.

Top comments (0)