The components of a Large Language Model (LLM) are the different parts that work together to enable the model to understand, process, and generate human-like text. Each component has a unique role, and together, they create a system capable of language comprehension and generation. Let’s go over each main component of an LLM
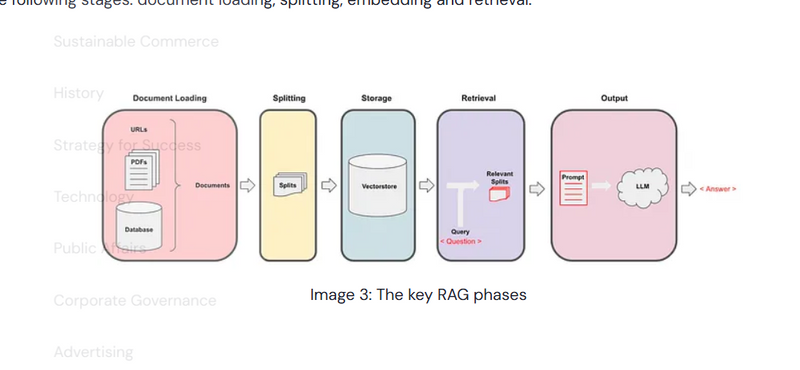
Step 1: Load (Data Ingestion)
Goal: Load data from various sources and prepare it for further processing.

Explanation: In LangChain, the ingestion process involves loading data from different sources, which could be text files, tables, images, JSON, or URLs. LangChain offers several data loaders to handle these different formats.
Basic Example in LangChain:
from langchain.document_loaders import TextLoader
# Example: Loading text data
loader = TextLoader('your_data_file.txt')
documents = loader.load()
Data Loading for Other Formats:
CSV: CSVLoader in LangChain.
PDF: PyMuPDFLoader or PDFMinerLoader.
URLs: UnstructuredURLLoader.
Images: This requires an OCR library such as Pytesseract to convert image content to text before loading.
This process is known as data ingestion because it is the initial step where data is taken in and prepped.
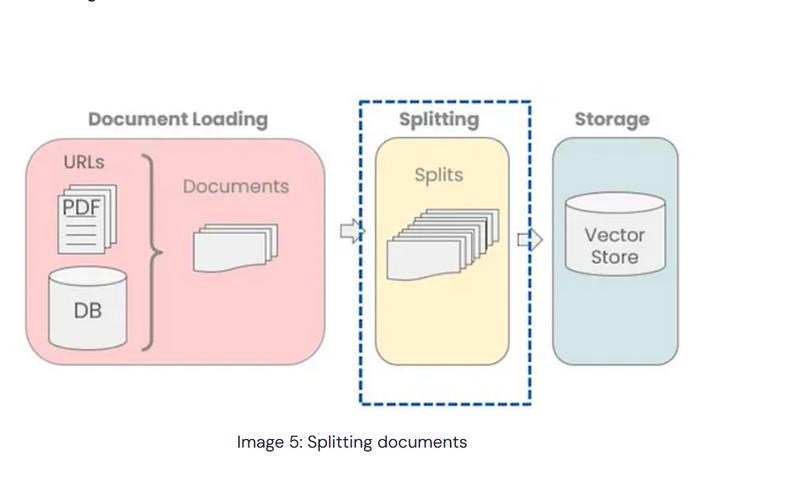
Step 2: Split (Data Transformation)
Goal: Split data into smaller, meaningful chunks.
Explanation: Data often needs to be split into chunks that are the right size for language models to process, especially for embedding and semantic similarity. LangChain provides text splitters for this purpose.
Using a Text Splitter in LangChain:
from langchain.text_splitter import CharacterTextSplitter
# Example: Splitting text into chunks
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
Why Split? Splitting helps transform large blocks of text into smaller chunksso each piece can be processed, embedded, and stored more effectively.
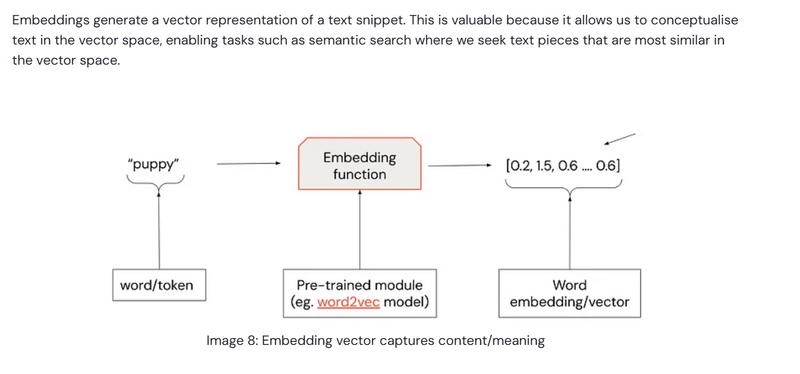
Step 3: Embed (Text to Vector Transformation)
Goal: Convert text chunks into vector representations.
Explanation: Once text is split, it needs to be embedded into a vector format, which allows for efficient similarity search. LangChain supports various embedding models (e.g., OpenAI, Ollama, Hugging Face).
Example of Text Embedding:
from langchain.embeddings import OpenAIEmbeddings
# Initialize the embedding model (in this case, OpenAI)
embeddings = OpenAIEmbeddings()
vectors = embeddings.embed_documents([chunk.page_content for chunk in chunks])
Supported Embedding Techniques:
OpenAI: Use OpenAI’s API for high-quality embeddings.
Ollama: Similar to OpenAI but often more customizable.
Hugging Face: Access a range of open-source models.
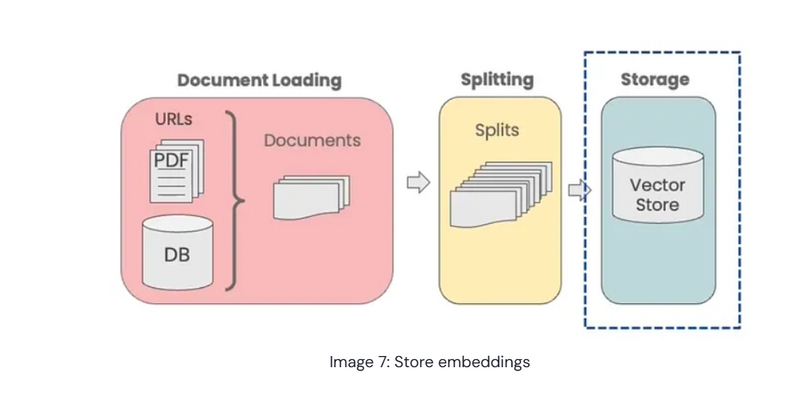
Step 4: Store (Vector Storage)
Goal: Store the vector embeddings for later querying.
Explanation: After embedding the text, you need a way to store and retrieve these embeddings efficiently. This is typically done with vector databases (e.g., FAISS, Qdrant, Pinecone). LangChain provides integration with several options.
Example of Vector Storage in LangChain (Using FAISS):
from langchain.vectorstores import FAISS
# Store vectors in FAISS vector store
vector_store = FAISS.from_documents(chunks, embeddings)
vector_store.save_local("faiss_index")
Other Vector Stores:
Pinecone: Hosted, managed vector database.
ASTRA DS: Good for scalable, cloud-based applications.
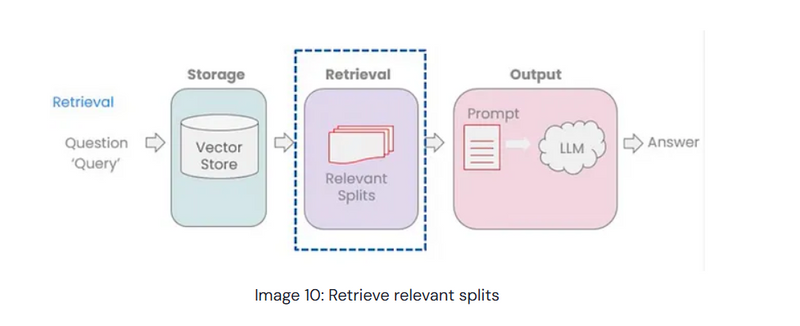
Querying from Vector Store for Context Information
Goal: Retrieve vectors from the store based on similarity search for contextual relevance.
Example of Querying:
# Assume 'query' is your input text
query_vector = embeddings.embed_query("your query text")
results = vector_store.similarity_search(query_vector, k=5) # Top 5 results
Explanation of Results: The result provides the most contextually similar chunks based on semantic similarity, allowing the system to retrieve relevant information for a Large Language Model (LLM) to process in response to a query.
Retrieval
A retriever is an interface that provides documents based on an unstructured query. It utilises search methods implemented by a vector store, including similarity search and maximum marginal relevance (MMR), to query texts in the vector store and retrieve relevant documents. The retriever serves as a lightweight wrapper around the vector store class, adhering to the retriever interface.
retrieval-augmented-generation
SUMMARY
FLOW
load==split==embed==store
data ingestion(documentloading)--->data transformer(splitting)--->embedding(convert to vector form)---->store(vectordatabase)
TYPES of data sources
data ingestion/document loading===========>text files, tables, images, JSON, or URLs,csv,excel,pdf
TextLoader('speech.txt').load||CSVLoader ||PyMuPDFLoader or PDFMinerLoader||UnstructuredURLLoader
DATA TRANSFORMER AND SYNTAX
Split (Data Transformation)========>transform large blocks of text into smaller chunks ,convert into list of collection,flattened list format,userfriendly json/nestedjson format
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50) ||chunks = text_splitter.split_documents(documents)
EMBED DOCUMENT
Embed (Text to Vector Transformation)=======>for efficient similarity search(OpenAI, Ollama, Hugging Face)
vectors = OpenAIEmbeddings().embed_documents([chunk.page_content for chunk in chunks])
STORE
Store (Vector Storage/vector database)======>Store the vector embeddings for later querying.(FAISS, Qdrant, Pinecone)
FAISS.from_documents(chunks, embeddings).save_local("faiss_index")
RETRIVAL
Retrival====>
embeddings.embed_query("your query text")
vector_store.similarity_search(query_vector, k=5) # Top 5 results

Top comments (0)