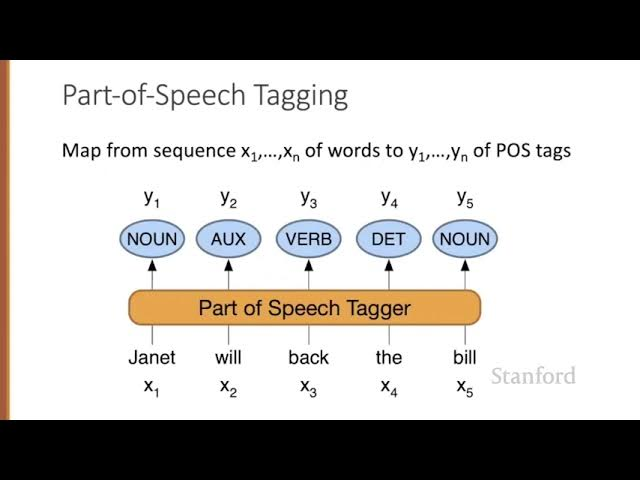
Get part of speech using POS Tagging after Tokenization
In natural language processing (NLP), part-of-speech (POS) tagging is the process of assigning a specific grammatical category or part-of-speech label to each word in a text. POS tagging is a fundamental step in NLP because it helps computers understand the syntactic and grammatical structure of text, enabling more advanced text analysis and language understanding. Here are some common parts of speech in NLP with examples:
Noun (NN):
Nouns are words that represent people, places, things, or concepts.
Examples: dog, cat, New York, love, computer
Verb (VB):
Verbs represent actions, events, or states.
Examples: run, eat, talk, is, have
Adjective (JJ):
Adjectives describe or modify nouns, providing more information about them.
Examples: beautiful, tall, red, happy
Adverb (RB):
Adverbs modify verbs, adjectives, or other adverbs, often indicating manner, time, place, or degree.
Examples: quickly, very, here, almost
Pronoun (PRP):
Pronouns are used to replace nouns to avoid repetition.
Examples: he, she, it, they, I, you
Preposition (IN):
Prepositions indicate relationships between other words in a sentence, often showing location, time, or direction.
Examples: in, on, at, with, under
Conjunction (CC):
Conjunctions connect words or phrases in a sentence.
Examples: and, but, or, because
Determiner (DT):
Determiners are used before nouns to provide information about them, such as quantity or specificity.
Examples: a, an, the, some, many
Interjection (UH):
Interjections are short exclamations or expressions used to convey strong emotions.
Examples: oh, wow, ouch, well
Numeral (CD):
Numerals represent numbers and quantities.
Examples: one, 7, fifty, third
Particle (RP):
Particles are small words that do not fit into other POS categories, often indicating modality or aspect.
Examples: up, down, out, off
Modal Verb (MD):
Modal verbs are auxiliary verbs that express necessity, possibility, or obligation.
Examples: can, could, must, should, might
Conjunction (CC):
Conjunctions connect words, phrases, or clauses in a sentence.
Examples: and, but, or, while, although
Exclamation (EX):
Exclamations are used to express strong emotions or sudden exclamatory statements.
Examples: Ouch! Oh no! Wow!
Foreign Word (FW):
Foreign words are terms borrowed from other languages or not native to the language being analyzed.
Examples: sushi, déjà vu, faux pas
These are some common POS categories used in NLP. In actual POS tagging, words in a sentence are assigned labels that fall into one of these categories. For example, in the sentence "The quick brown fox jumps over the lazy dog," you can identify nouns (fox, dog), adjectives (quick, brown, lazy), verbs (jumps), and determiners (The) through POS tagging. Understanding the POS of words is crucial for tasks like syntactic parsing, sentiment analysis, and information extraction in NLP.
In natural language processing (NLP), part-of-speech (POS) tagging is performed using pre-trained models and libraries that have learned to assign POS tags to words based on the grammatical and contextual information within a text corpus. One of the popular libraries for POS tagging is spaCy. Below is an example of how POS tagging is done in NLP using spaCy, along with a step-by-step explanation:
Install spaCy:
You need to install spaCy and download a language model. In this example, we'll use the English model "en_core_web_sm." Install spaCy and download the model using pip:
pip install spacy
python -m spacy download en_core_web_sm
Import spaCy:
Import the spaCy library and load the language model.
import spacy
# Load the English language model
nlp = spacy.load("en_core_web_sm")
Tokenization and POS Tagging:
Get part of speech using POS Tagging after Tokenization
Pass a text through spaCy to perform tokenization (splitting the text into words) and POS tagging. You can access the POS tags using the pos_ attribute of each token.
# Sample sentence for POS tagging
sentence = "The quick brown fox jumps over the lazy dog."
# Process the sentence using spaCy
doc = nlp(sentence)
# Print the words and their POS tags
for token in doc:
print(f"{token.text}: {token.pos_}")
Output:
The: DET
quick: ADJ
brown: ADJ
fox: NOUN
jumps: VERB
over: ADP
the: DET
lazy: ADJ
dog: NOUN
.: PUNCT
Explanation:
We load the English language model using spacy.load("en_core_web_sm").
We process a sample sentence ("The quick brown fox jumps over the lazy dog.") using spaCy.
The doc object contains tokenized words, and you can access their POS tags using the pos_ attribute.
The output shows each word in the sentence along with its corresponding POS tag.
This is how POS tagging is performed in NLP. It's crucial for understanding the grammatical structure of text, which is essential for various tasks, such as syntax analysis, information extraction, and sentiment analysis. SpaCy, NLTK, and other NLP libraries provide pre-trained models for POS tagging, making it easier to work with text data in different languages and domains.

Top comments (0)