Objective of an object detection models is to
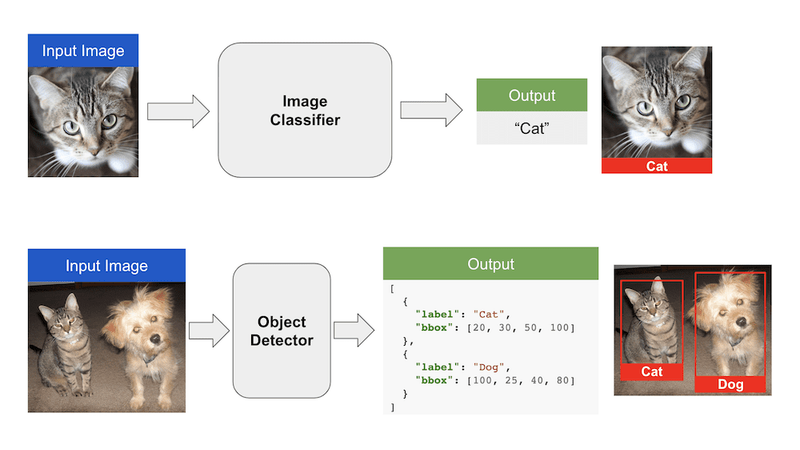
Classification: Identify if an object is present in the image and the class of the object
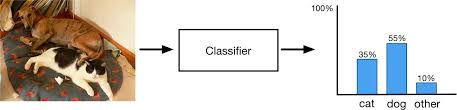
Localization: Predict the co-ordinates of the bounding box around the object when an object is present in the image. Here we compare the co-ordinates of ground truth and predicted bounding boxes
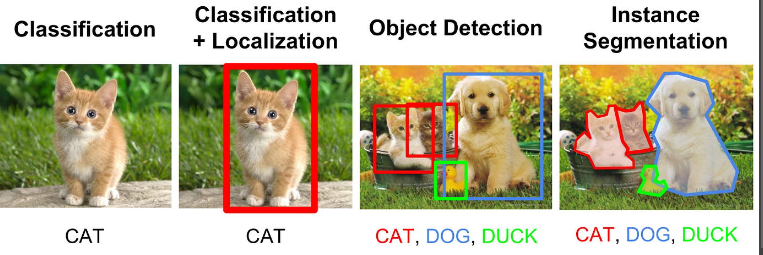
The primary objective of object detection models is to identify and locate objects within an image or a video frame. These models aim to provide not only information about the presence of objects but also their spatial extent through bounding boxes. The objectives of object detection models can vary based on the application, but generally, they revolve around improving accuracy, robustness, and efficiency in recognizing and localizing objects. Here are some common objectives of object detection models with examples:
Accurate Object Localization:
Objective: Precisely locate objects in an image by predicting accurate bounding box coordinates.
Example: In autonomous driving, a vehicle detection system should accurately identify the positions of other vehicles, pedestrians, and obstacles on the road.
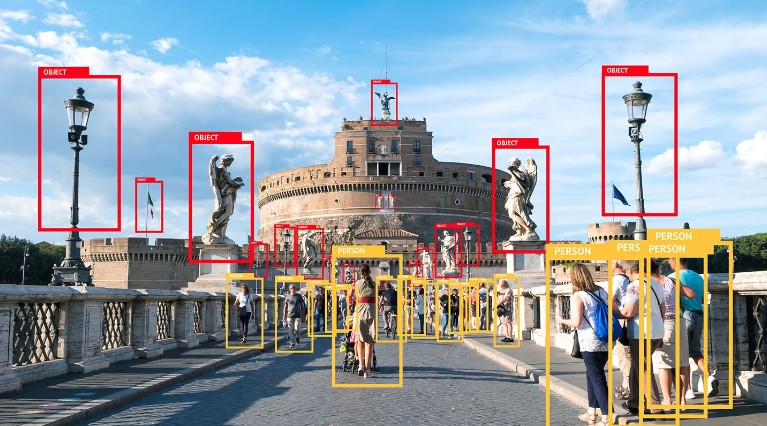
Multi-Object Detection:
Objective: Detect multiple objects of different classes within the same image.
Example: In retail surveillance, an object detection model should identify and label various items on store shelves simultaneously.

Real-time Object Detection:
Objective: Achieve low inference time to enable real-time processing.
Example: Real-time video analysis for security surveillance, where the model needs to detect and track objects as they move through the camera's field of view.
Robustness to Scale and Orientation:
Objective: Ensure the model can detect objects of various sizes and orientations.
Example: A satellite image analysis system that needs to identify buildings, vehicles, and other structures regardless of their scale and orientation.
Semantic Segmentation and Instance Segmentation:
Objective: Distinguish between different object instances and segment each object at the pixel level.
Example: Medical imaging, where a model should not only detect tumors but also segment each tumor instance from the surrounding tissue.
Few-shot Object Detection:
Objective: Train the model to detect objects with very few annotated examples.
Example: In situations where obtaining a large labeled dataset is challenging, such as rare species identification in wildlife monitoring.
Object Detection in Cluttered Scenes:
Objective: Detect objects accurately even in scenes with a high degree of occlusion and clutter.
Example: Warehouse inventory management, where objects may be stacked, partially obscured, or placed close together.
Generalization Across Domains:
Objective: Train the model to generalize well across different environments and scenarios.
Example: Object detection for a drone, where the model should be capable of identifying objects in diverse landscapes and lighting conditions.
Fine-grained Object Detection:
Objective: Detect objects within categories that have subtle visual differences.
Example: Identifying species of birds or breeds of dogs within a larger category.
Human-Object Interaction Detection:
Objective: Not just detecting objects but understanding interactions between objects and humans.
Example: Video surveillance in public spaces where the model needs to identify interactions, such as people leaving bags unattended.

Top comments (0)