Challenges faced by Deep Neural Networks
Key Components of ResNet Architecture
Variants of ResNet
pros and cons of residual architecture
Challenges faced by Deep Neural Networks
Vanishing/Exploding Gradient Problem:
As the number of layers in the neural network increases the gradients of the loss function with respect to the weight may become extrememly small during backpropogation. This makes it difficult for the latter layers to learn any meaningful pattern as the updates of the weights are almost negligible to have an impact.
Conversely in some cases the gradients can become very large during backpropogation leading to unstability in the training process by causing the weights to be updated by large amount, making the optimization process difficult to control.
Degradation Problem in Neural Network:
The degradation problem in neural networks refers to the phenomenon where, as the depth of a neural network increases ,the performance of the network on the training data saturates and then starts to degrade. The degradation problem is particularly problematic because it goes against the intuition that deeper networks are more able to extract intricate and abstract features.We can see it as twofold problem
o Performance Plateau: As the number of layers in the neural network increases the training error tends to saturate and stops improving.It means that the additional layers are not having any significant benefit on the reduction of training error.
o Accuracy Degradation: After the addition of more layers surprisingly the error on the validation set starts increasing and the performance on the unseen data becomes poor.
Key Components of ResNet Architecture
1-Residual Block:
Residual blocks are the main components of Residual Neural network In a classical neural network the input is transformed by a set of convolutional layers then it is passed to the activation function. In a residual network the input to the block is added to the output of
the block creating a residual connection.The output of the residual block H(x) can be represented by:
H(x) = F(x) + x
F(x) represents the residual mapping learned by the network .The presence of identity term x allows the gradient to flow more easily .
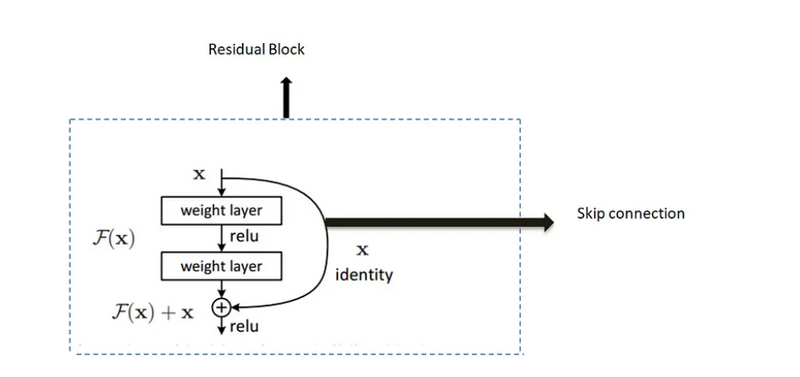
2- Skip Connection:
Skip connection helps in forming the residual blocks.Skip connection consists of the input of the residual block that is bypassed over the convolutional layer and added to the output of the residual block.
3- Stacked layers:
ResNet architectures are formed by stacking multiple residual blocks together.Using these multiple residual blocks together resnet architecture can be built very deep.Versions of ResNet with 50,101,152 layers were introduced.
4-Global Average Pooling(GAP)
Resnet architectures typically utilises Global average Pooling as the final layer before the fully connected layer .GAP reduces spatial dimensions to a single value per feature map providing a compact representation of the entire feature map.
A Look into the 34 layered Residual Neural Network
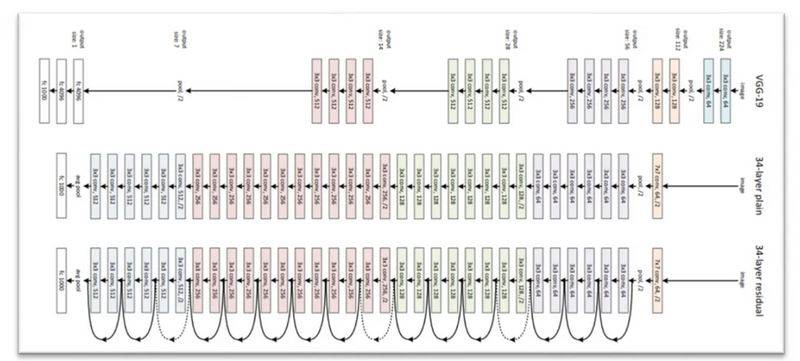
In this diagram we can see the VGC-19 ,34 layer plain network and 34 layered residual network.
In this residual network there are total 16 residual blocks.
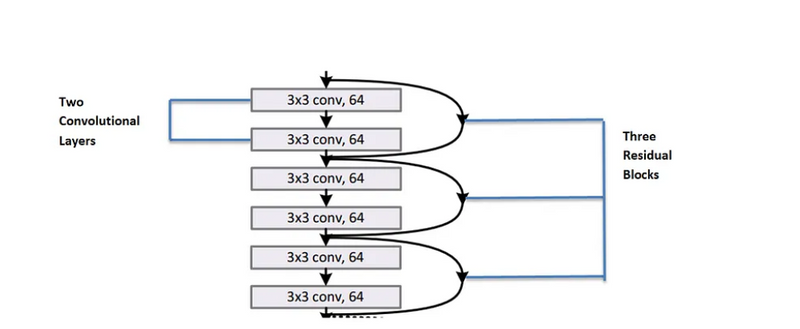
· The first set consists of 3 residual blocks. Each residual block consists of 2 convolution layers where each convolution layer consists of 64 filters of size 3x3 and a skip connection which performs identity mapping.
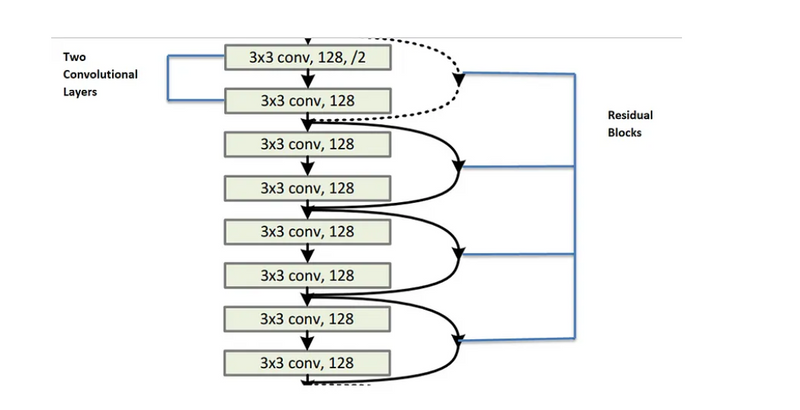
· Second set consists of 4 residual blocks. Each residual block contains 2 convolutional layers where each layer consists of 128 kernels of of size 3x3 and a skip connection .
· Dotted line skip connections represents the connections when the dimension are increased then it has to match the dimension of the output of convolutional layers.
When the dimensions increase (dotted line shortcuts ), we consider two options:
The first is that the shortcut still performs identity mapping, with extra zero entries padded for increasing dimensions. The second is that the projection shortcut is used to match dimensions (done by 1×1 convolutions). For both options, when the shortcuts go across feature maps of two sizes, they are performed with a stride of 2.
· Third set consists of 6 residual blocks where each residual blocks contains two convolutional layers . Each convolution layer has 256 filters of size 3x3.
· The fourth set consists of 3 residual blocks where each residual blocks consists of 2 convolutional layers .Each convolutional layer contains 512 filters of 3x3 each.
· After that the feature map is passed through average pooling layer and then it is passes through dense layer containing 1000 neurons to classify 1000 classes.
Comparing The Performance of Plain Networks with residual networks
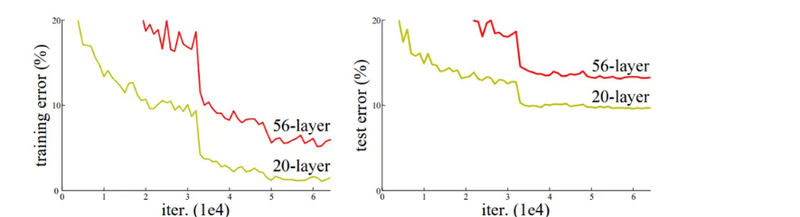
Above figure shows the training error and test error on CIFAR-10 with 20 layer and 56 layer plain network. We can observe from above that as we are increasing the number of layers both training and test error of 56 layered network are higher than the 20 layered network.
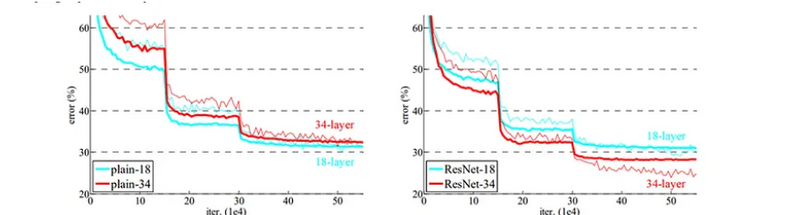
Above figure shows the training on Imagenet .Thick curves denotes validation error and thin curve denotes training error.Left figure is for plain network of 18 layers and 34 layers.
Right figure is for Residual Network for 18 layers and 34 layers.
For the plain networks the 34 layers has more training and validation error as compared to the 18 layered network.
Conversely for the Residual Network the training error and validation error are significantly less for 34 layered network as compared to 18 layered network.
Variants of ResNet
ResNeXt is an alternative model based on the original ResNet design. It uses the building block illustrated below:
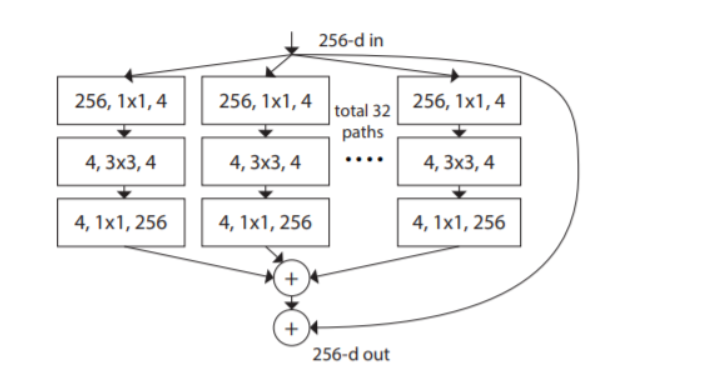
The ResNeXt model incorporates the ResNet strategy of repeating layers but introduces an extensible, simple way to implement the split, transform, and merge strategy. The building block resembles the Inception network that supports various transformations such as different 1×1 Conv, 3×3 Conv, 5×5 Conv, and MaxPooling. However, while these transformations are stacked together in the Inception model, the ResNeXt model adds and merges them.
This model adds another dimension of cardinality in the form of the independent path number. It also includes existing depth and height dimensions. The authors experimentally demonstrated the importance of the added dimension for increasing accuracy. Increased cardinality helps the network go wider or deeper, especially if the width and depth dimensions produce diminished returns for standard models.
There are three variations of the proposed ResNeXt building block:
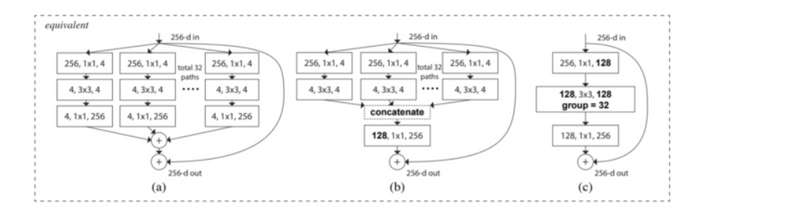
The authors of ResNeXt claim it is an easy-to-train model compared to the Inception network because it is trainable over multiple datasets. It contains a single adjustable hyperparameter, unlike Inception’s multiple hyperparameters.
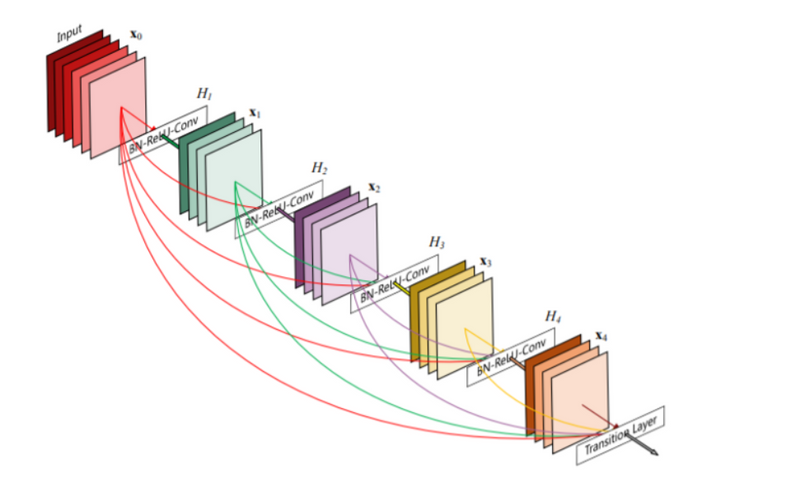
DenseNet
DenseNet is another popular ResNet variation, which attempts to resolve the issue of vanishing gradients by creating more connections. The authors of DenseNet ensured the maximum flow of information between the network layers by connecting each layer directly to all the others. This model preserves the feed-forward capabilities by allowing every layer to obtain additional inputs from its preceding layers and pass on the feature map to subsequent layers.
Here is an illustration of the model:
pros and cons of residual architecture

Cons:




Top comments (0)