In the context of object detection, Region-based Convolutional Neural Networks (R-CNN) and its variants (Fast R-CNN, Faster R-CNN, etc.) have been influential architectures. The role of Convolutional Neural Networks (CNNs) within these architectures is crucial for feature extraction and object localization. Let's break down the key steps of the R-CNN architecture and understand the role of CNNs:
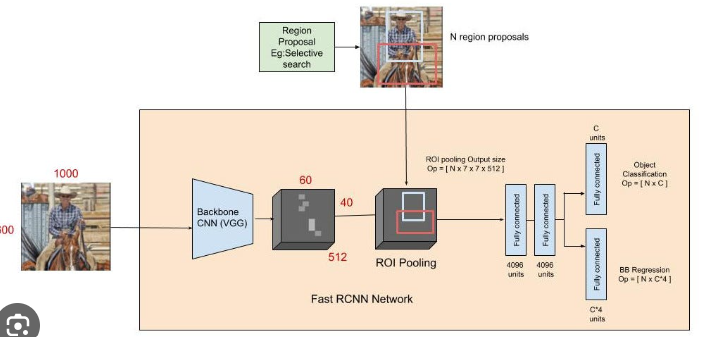
Input Image:
The process begins with an input image containing objects that need to be detected.
Region Proposal:
In the initial R-CNN, region proposals are generated using an external method like Selective Search. Later improvements, such as Faster R-CNN, integrated the region proposal network (RPN) directly into the model for end-to-end training.
Region of Interest (RoI) Pooling:
Once the region proposals are obtained, RoI pooling is applied. This step involves extracting fixed-size feature maps from each region proposal, regardless of the region's size or aspect ratio. This allows for consistent feature extraction.
Feature Extraction with CNN:
The CNN plays a pivotal role in feature extraction. The RoI-pooled region proposals are passed through the CNN, which is typically a pre-trained network (e.g., a variant of VGG, ResNet, or similar architectures).
The CNN transforms the input RoI into a fixed-size feature vector. This vector captures hierarchical and abstract features of the region, including patterns, textures, and spatial relationships.
Classification and Regression Heads:
The feature vector is then fed into two parallel fully connected (dense) layers:
Classification Head: This head predicts the probability distribution over different classes, determining the likelihood of the region proposal belonging to each class.
Regression Head: This head predicts adjustments (offsets) to the bounding box coordinates, refining the position of the bounding box.
Output:
The final output includes the predicted class probabilities and refined bounding box coordinates for each region proposal.
Role of CNN in R-CNN Architecture:
Feature Extraction:
CNNs excel at learning hierarchical features from images. The layers of a pre-trained CNN act as feature extractors, capturing low-level features like edges and textures in early layers and more abstract, high-level features in deeper layers.
Transfer Learning:
Pre-training CNNs on large datasets (e.g., ImageNet) enables them to learn general features that can be transferred to other tasks with limited labeled data, such as object detection.
Localization and Discrimination:
The features extracted by the CNN play a crucial role in both localizing objects (bounding box regression) and discriminating between different object classes (classification).
End-to-End Training:
In modern architectures like Faster R-CNN, the entire model, including the CNN and the region proposal network, is trained end-to-end. This joint training allows the model to learn not only from classification and regression losses but also from the proposal generation process.
Adaptation to Object Variability:
The hierarchical features extracted by the CNN contribute to the model's ability to adapt to variations in object appearance, scale, orientation, and other factors.
In summary, the CNN in the R-CNN architecture serves as a powerful feature extractor, enabling the model to understand and discriminate between different objects in an image while also localizing them accurately. The pre-trained CNN leverages transfer learning to benefit from knowledge gained on large-scale image datasets, making it effective for object detection tasks even with limited annotated data.

Top comments (0)