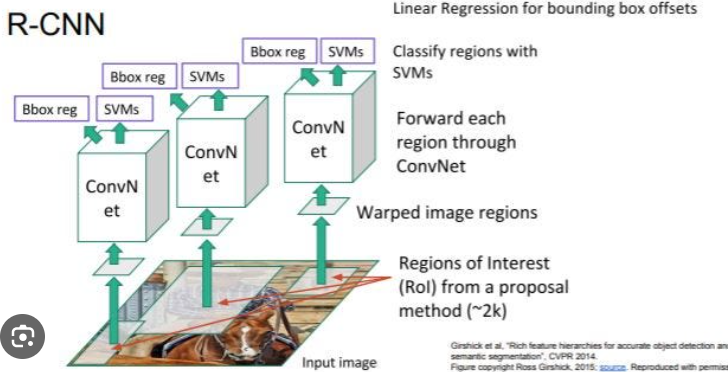
In the context of the Region-based Convolutional Neural Network (R-CNN) architecture for object detection, Support Vector Machines (SVMs) have been used as classifiers for object detection. Specifically, SVMs are applied in the final stage of the R-CNN pipeline to classify the proposed regions into different object classes. Here's a breakdown of the role of SVMs in the R-CNN architecture:
Region Proposal:
The R-CNN pipeline starts with the generation of region proposals. In the original R-CNN, external methods like Selective Search were used to propose candidate regions in the image that might contain objects.
Feature Extraction with CNN:
After obtaining region proposals, each region is passed through a Convolutional Neural Network (CNN). The CNN extracts feature representations from the proposed regions, transforming them into fixed-size feature vectors.
SVM Classification:
The feature vectors extracted by the CNN for each region proposal are then used as input to a Support Vector Machine (SVM) classifier. The SVM is trained to classify each region into one of the predefined object classes or background.
Bounding Box Regression:
In addition to classification, another branch of the system uses regression to refine the bounding box coordinates of the proposed regions. This helps improve the localization accuracy.
Output:
The final output includes the class label predicted by the SVM for each region proposal, along with the refined bounding box coordinates.
Role of SVMs in R-CNN
Discriminative Classification:
SVMs serve as discriminative classifiers, making decisions about the object class for each region proposal based on the features extracted by the CNN. This helps distinguish between different object categories.
Handling Imbalanced Data:
SVMs are robust to imbalanced datasets, which is common in object detection tasks where the number of background regions (regions not containing any objects) far exceeds the number of regions containing objects.
Binary Classification:
Typically, multiple SVM classifiers are trained, each specialized for binary classification (e.g., one SVM for "person" vs. "not person," another for "car" vs. "not car," and so on). This binary classification setup is common in multi-class object detection.
End-to-End Training:
While SVMs are used as classifiers, it's important to note that the R-CNN system is trained end-to-end. This means that both the CNN and the SVMs are jointly optimized during the training process, allowing the model to learn features that are effective for discrimination.
Flexible Architecture:
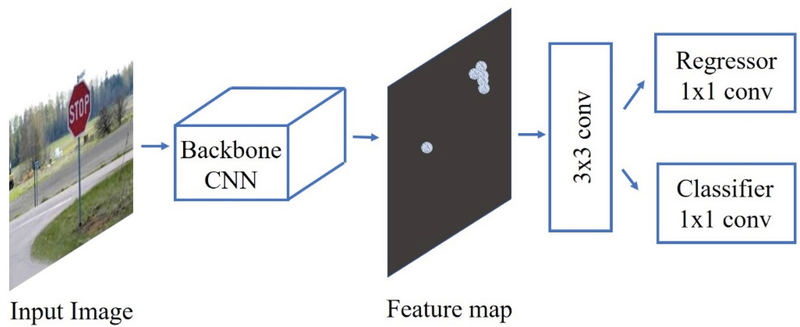
The R-CNN architecture is flexible and allows for different choices of classifiers. In addition to SVMs, subsequent versions of R-CNN, such as Fast R-CNN and Faster R-CNN, replaced the SVM with a softmax layer for classification in an effort to simplify the training pipeline and enable faster end-to-end training.

Top comments (0)