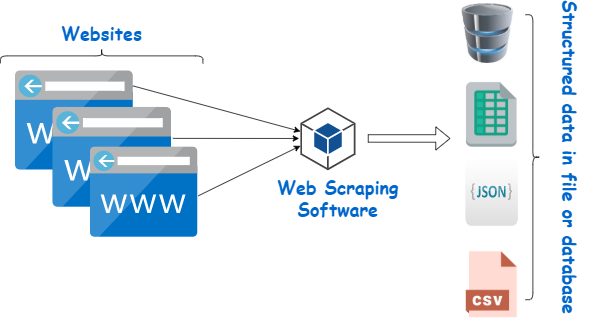
Web scraping is the process of extracting data from websites. Python is a popular programming language for web scraping due to its powerful libraries and frameworks for handling web-related tasks. In this explanation, I'll provide a basic example of web scraping using Python and the BeautifulSoup library. Please note that web scraping should always be done responsibly and within the legal boundaries of a website's terms of service.


Is Webscrapping is legal

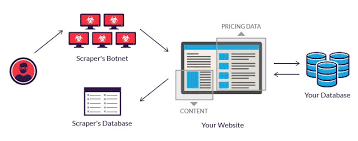
The legality of web scraping varies depending on several factors, including the website being scraped, the purpose of the scraping, and the jurisdiction in which you operate. Here are some key considerations:
Website Terms of Service: Many websites have terms of service or terms of use agreements that explicitly state whether web scraping is allowed or prohibited. You should always review a website's terms of service to determine if scraping is permitted. Violating these terms could lead to legal action.
Publicly Accessible Data: If the data you are scraping is publicly accessible without the need for authentication or bypassing security measures, it may be more likely to be considered legally obtainable. However, this doesn't guarantee that scraping is allowed, as website owners can still take legal action if they believe scraping is harmful or violates their terms of service.
Respect for Robots.txt: Some websites use a robots.txt file to communicate with web crawlers and scrapers about which parts of their site can be crawled and scraped and which should be excluded. It's generally a good practice to respect the directives in a website's robots.txt file. Ignoring it could lead to ethical and legal issues.
Purpose of Scraping: The purpose of web scraping matters. Scraping for personal use or research may be viewed differently than scraping for commercial purposes or to compete with a website's services. Commercial use of scraped data may be more likely to lead to legal challenges.
Copyright and Data Ownership: Web scraping should not involve copying or distributing copyrighted content without permission. Additionally, data that is protected by intellectual property rights or trade secrets should not be scraped for unauthorized use.
Privacy Concerns: Be cautious when scraping websites that contain personal or sensitive user data. Violating privacy laws by scraping such data without consent can lead to legal consequences.
Jurisdiction: Laws regarding web scraping vary by country and jurisdiction. What may be legal in one place may not be in another. It's important to understand the legal framework in your jurisdiction.
Fair Use and Transformative Use: In some cases, web scraping may be considered "fair use" if it meets certain criteria, such as being transformative in nature or for the purpose of commentary, research, or education. However, fair use is a complex legal concept, and it may not provide a blanket defense.
Real Time Application of Webscrapping
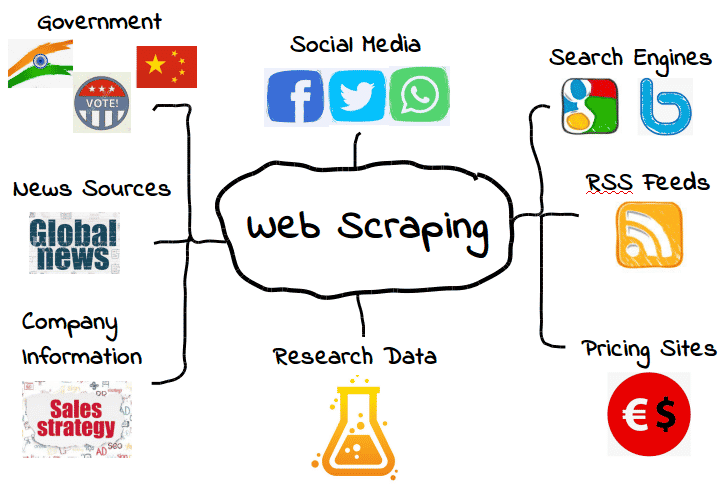
Web scraping has a wide range of real-time applications across various industries and domains. Here is a list of real-time applications of web scraping:
Price Comparison and Tracking:
Monitoring and comparing prices of products on e-commerce websites in real-time.
Tracking fluctuations in stock prices and financial data from various sources.
Market Research:
Gathering real-time data on market trends, consumer reviews, and sentiment analysis.
Collecting data on competitors' prices, products, and strategies.
News and Content Aggregation:
Aggregating news articles, blog posts, and updates from multiple sources in real-time.
Creating custom news feeds and dashboards for personalized content.
Weather and Environmental Data:
Retrieving real-time weather forecasts, temperature, humidity, and air quality data from weather websites.
Monitoring environmental factors such as pollution levels and natural disaster alerts.
Social Media Analytics:
Analyzing social media platforms for real-time sentiment analysis and trends.
Tracking mentions of brands, products, or keywords on social media.
Job Market Analysis:
Scraping job listings from job boards and company websites for real-time job market analysis.
Tracking demand for specific skills and job opportunities.
Travel and Flight Information:
Fetching real-time flight schedules, prices, and availability from airline and travel agency websites.
Tracking hotel room prices and availability for travel planning.
Sports Data and Scores:
Collecting live sports scores, statistics, and updates from sports websites.
Analyzing player performance and team rankings in real-time.
Real Estate Market Analysis:
Gathering data on property listings, prices, and market trends from real estate websites.
Identifying investment opportunities and comparing property values.
Healthcare and Medical Research:
Extracting medical research papers, clinical trial data, and healthcare statistics for real-time analysis.
Monitoring disease outbreaks and health-related news.
Government and Public Data:
Accessing public datasets and government reports for real-time information on demographics, economics, and public policies.
Tracking government announcements and regulatory changes.
Cryptocurrency and Financial Markets:
Collecting real-time data on cryptocurrency prices, trading volumes, and market capitalization.
Analyzing financial market data for investment decisions.
Monitoring Competitor Activities:
Tracking changes in competitor websites, pricing strategies, and product offerings.
Staying informed about industry developments.
Content Extraction for Search Engines:
Indexing and extracting content from websites to improve search engine results.
Keeping search engine databases up-to-date.
Social Listening and Brand Management:
Monitoring social media platforms for mentions of brands and products in real-time.
Responding to customer feedback and managing brand reputation.
E-commerce Inventory Management:
Keeping track of product availability and stock levels on e-commerce websites.
Automatically updating inventory and pricing on your own e-commerce platform.
These are just a few examples of how web scraping can be applied in real-time to gather valuable data and insights. However, it's essential to be mindful of legal and ethical considerations when scraping websites and to respect their terms of service and robots.txt files.

Top comments (0)