The metric_score function in machine learning serves the purpose of evaluating the performance of a classifier on either the training or test dataset. It provides insights into how well the model is performing by computing and printing various evaluation metrics. Let's discuss the use of the metric_score function in the context of machine learning prediction:
Purpose and Components
:
Classifier Evaluation:
The primary use of metric_score is to evaluate the performance of a classifier, which is passed as the clf parameter.
Training Mode (train=True):
- When train is set to True, the function assumes it's in training mode.
- The classifier is fitted on the training data (clf.fit(x_train, y_train)).
- Predictions are made on the training set (y_pred_train = clf.predict(x_train)).
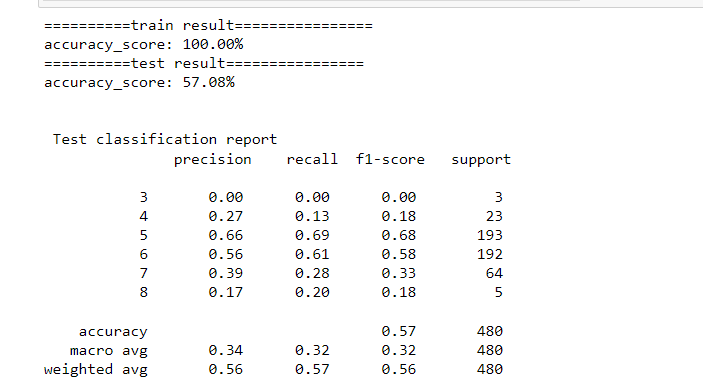
Accuracy score on the training set is printed
.
Testing Mode (train=False):When train is set to False, the function assumes it's in testing mode.
Predictions are made on the test set (y_pred_test = clf.predict(x_test)).
Accuracy score on the test set is printed.
The classification report for the test set is printed, including precision, recall, and F1-score
.
Importance of metric_score:
Model Assessment:
metric_score provides a quick and concise way to assess the performance of a classifier. The accuracy score and classification report offer a comprehensive view of the model's capabilities.
Comparison of Models:
It allows for the comparison of different models by using the same evaluation criteria. This is crucial for selecting the best-performing model for a given task.
Debugging and Optimization:
During the development phase, the function aids in debugging by revealing how well the model is learning from the training data and generalizing to unseen data.
Informing Decision-Making:
The function outputs metrics that are useful for decision-making, such as whether the model is performing well enough for deployment or if further optimization is required.
User-Friendly Output:
The printed output is user-friendly and provides a quick summary of the model's performance. It includes accuracy scores and classification reports that are easy to interpret.
def metric_score(clf, x_train, x_test, y_train, y_test, train=True):
if train:
clf.fit(x_train, y_train) # Ensure that the classifier is fitted
y_pred_train = clf.predict(x_train)
print("==========train result================")
print(f"accuracy_score: {accuracy_score(y_train, y_pred_train) * 100:.2f}%")
# Other metrics or actions for training data
else:
y_pred_test = clf.predict(x_test)
print("==========test result================")
print(f"accuracy_score: {accuracy_score(y_test, y_pred_test) * 100:.2f}%")
print("\n \n Test classification report \n", classification_report(y_test, y_pred_test, digits=2))
Explanation
Function Signature:
def metric_score(clf, x_train, x_test, y_train, y_test, train=True):
The function is defined with the name metric_score and takes six parameters:
- clf: The classifier (e.g., a scikit-learn classifier object).
- x_train: Features of the training set.
- x_test: Features of the test set.
- y_train: Labels of the training set.
- y_test: Labels of the test set.
- train: A boolean flag indicating whether to evaluate on the training set (True) or test set (False). The default is True . Train/Test Split:
if train:
clf.fit(x_train, y_train) # Ensure that the classifier is fitted
y_pred_train = clf.predict(x_train)
print("==========train result================")
print(f"accuracy_score: {accuracy_score(y_train, y_pred_train) * 100:.2f}%")
# Other metrics or actions for training data
else:
y_pred_test = clf.predict(x_test)
print("==========test result================")
print(f"accuracy_score: {accuracy_score(y_test, y_pred_test) * 100:.2f}%")
print("\n \n Test classification report \n", classification_report(y_test, y_pred_test, digits=2))
If train is True, the function assumes it's in the training mode:
- It fits the classifier on the training data (clf.fit(x_train, y_train)).
- It makes predictions on the training set (y_pred_train = clf.predict(x_train)).
- It prints the accuracy score for the training set.
It can include additional metrics or actions for the training data
.
If train is False, the function assumes it's in the testing mode:It makes predictions on the test set (y_pred_test = clf.predict(x_test)).
It prints the accuracy score for the test set.
It prints the classification report for the test set, which includes precision, recall, and F1-score
.
Printing Results:
The function prints the results, including accuracy scores and any additional information based on the mode (training or testing).
Check Output
clf=DecisionTreeClassifier()
metric_score(clf,x_train, x_test, y_train, y_test,train=True)
metric_score(clf,x_train, x_test, y_train, y_test,train=False)

Top comments (0)