How to select element By NAME to search or send key
How to select all anchor element of cards using class by xpath By NAME and store in list using for loop,list comprehension,lambda 3 method to iterate them to scrape individual product details
How to get url inside for loop using driver.get
How page should be loaded fully using time.sleep methods
How to get first li tag that is inside ul and that is inside class
How to select word or string that is before particular symbol
How to select word or string that is after particular symbol
how to select first word from given string
How to concatnate the url
How to take specific tr or td inside specific table class and tr class
How element is not present then handle it using exception handling
How to handle element click intercept exception
How to select particular span tag using xpath
How to select anchor tag within particular div using xpath
How to select strong tag within particular div using xpath
1.Write a python program to search for a smartphone(e.g.: Oneplus Nord, pixel 4A, etc.) on www.flipkart.com
and scrape following details for all the search results displayed on 1st page. Details to be scraped: “Brand
Name”, “Smartphone name”, “Colour”, “RAM”, “Storage(ROM)”, “Primary Camera”,
“Secondary Camera”, “Display Size”, “Battery Capacity”, “Price”, “Product URL”. Incase if any of the
details is missing then replace it by “- “. Save your results in a dataframe and CSV
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException,ElementClickInterceptedException
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get('https://www.flipkart.com/')
Step 5: Find the Search Input Element Oneplus Nord by sending S Keys to the Input Element and then submit button
How to select element By NAME to search or send key
search_bar = driver.find_element(By.NAME,'q')
search_bar.send_keys('oneplus nord')
search_bar.submit()
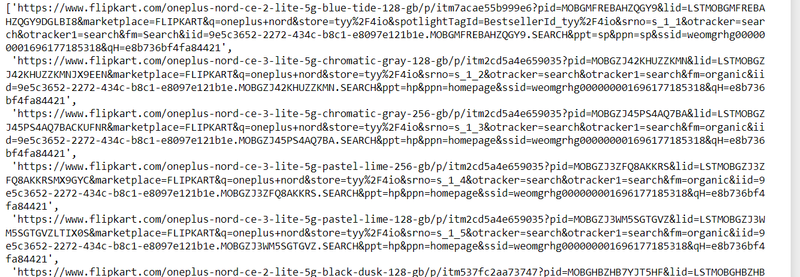
step 6: store all url in list to itereate them using for loop
How to select all anchor element of cards using class by xpath By NAME and store in list using for loop,list comprehension,lambda 3 method to iterate them to scrape individual product details
heading = driver.find_elements(By.XPATH, '//div[@class="_2kHMtA"]/a')
url=[]
for element in heading:
text = element.get_attribute('href')
url.append(text)
url
===========or======================
heading = driver.find_elements(By.XPATH, '//div[@class="_2kHMtA"]/a')
# Extract the href attributes from the pagination links and store them in a list
pagination_urls = [element.get_attribute("href") for element in heading ]
===========or=======
Assuming you've already initialized your WebDriver 'driver'
# Find all elements matching the XPath
heading_elements = driver.find_elements(By.XPATH, '//div[@class="_2kHMtA"]/a')
# Use map with a lambda function to extract 'href' attributes and convert them to a list
url = list(map(lambda element: element.get_attribute('href'), heading_elements))
output
step7:scrape detail of each product by iterating url
How to get url inside for loop using driver.get
How page should be loaded fully using time.sleep methods
How to get first li tag that is inside ul and that is inside class
How to select word or string that is before particular symbol
How to select word or string that is after particular symbol
how to select first word from given string
import time
brands=[]
phone_name=[]
colours=[]
rams=[]
full_storage=[]
Primary_camera=[]
Sec_camera=[]
Display_sizes=[]
Battery_capacity=[]
Prices=[]
Product_url=[]
for i in url:
driver.get(i)
time.sleep(5)
try:
brand = driver.find_element(By.CLASS_NAME,'B_NuCI')
brand_text = brand.text
brands.append(brand_text)
ram = driver.find_element(By.XPATH, '//div[@class="_2418kt"]/ul/li[1]')
ram_text = ram.text
ram_info = ram_text.split('|')[0].strip()
rams.append(ram_info)
rom = driver.find_element(By.XPATH, '//div[@class="_2418kt"]/ul/li[1]')
rom_text = rom.text
rom_info = rom_text.split('|')[1].strip()
full_storage.append(rom_info)
phone = driver.find_element(By.CLASS_NAME, 'B_NuCI')
phone_text = phone.text
# Split the text by spaces and get the first word
first_word = brand_text.split()[0]
phone_name.append(first_word)
colour = driver.find_element(By.XPATH, '//table[@class="_14cfVK"]/tbody/tr[4]/td[2]/ul/li')
color_text = colour.text
colours.append(color_text)
pri_camera = driver.find_element(By.XPATH, '//div[@class="_2418kt"]/ul/li[3]')
camera = pri_camera.text
Primary_camera.append(camera)
display = driver.find_element(By.XPATH, '//div[@class="_2418kt"]/ul/li[2]')
display_screen = display.text
Display_sizes.append(display_screen)
battrey_capacity = driver.find_element(By.XPATH, '//div[@class="_2418kt"]/ul/li[4]')
batt_capacity = battrey_capacity.text
Battery_capacity.append(batt_capacity)
price = driver.find_element(By.XPATH, '//div[@class="_25b18c"]/div[1]')
prices=price.text
Prices.append(price.text)
current_url = driver.current_url
Product_url.append(current_url)
# Perform actions on the element if needed
# For example, to get the text inside the element:
except NoSuchElementException:
break
brands
output
['OnePlus Nord CE 2 Lite 5G (Blue Tide, 128 GB) (6 GB RAM)',
'OnePlus Nord CE 3 Lite 5G (Chromatic Gray, 128 GB) (8 GB RAM)',
'OnePlus Nord CE 3 Lite 5G (Chromatic Gray, 256 GB) (8 GB RAM)',
'OnePlus Nord CE 3 Lite 5G (Pastel Lime, 256 GB) (8 GB RAM)',
'OnePlus Nord CE 3 Lite 5G (Pastel Lime, 128 GB) (8 GB RAM)',
'OnePlus Nord CE 2 Lite 5G (Black Dusk, 128 GB) (6 GB RAM)',
'OnePlus Nord CE3 5G (Aqua Surge, 256 GB) (12 GB RAM)',
'OnePlus Nord CE3 5G (Aqua Surge, 128 GB) (8 GB RAM)',
'OnePlus Nord CE3 5G (Grey Shimmer, 128 GB) (8 GB RAM)',
'OnePlus Nord 3 5G (Misty Green, 128 GB) (8 GB RAM)',
'OnePlus Nord 2T 5G (Gray Shadow, 128 GB) (8 GB RAM)',
'OnePlus Nord CE3 5G (Grey Shimmer, 256 GB) (12 GB RAM)',
'OnePlus Nord 2T 5G (Jade Fog, 128 GB) (8 GB RAM)',
'OnePlus Nord 3 5G (Misty Green, 256 GB) (16 GB RAM)',
'OnePlus Nord 3 5G (Tempest Gray, 128 GB) (8 GB RAM)',
'OnePlus Nord CE 2 5G (Bahama Blue, 128 GB) (8 GB RAM)',
'OnePlus Nord 3 5G (Tempest Gray, 256 GB) (16 GB RAM)',
'OnePlus Nord CE 5G (Charcoal Ink, 128 GB) (6 GB RAM)',
'OnePlus Nord 2T 5G (Jade Fog, 256 GB) (12 GB RAM)',
'OnePlus Nord 2T 5G (Gray Shadow, 128 GB) (8 GB RAM)',
'OnePlus Nord 2 5G (Blue Haze, 256 GB) (12 GB RAM)',
'OnePlus Nord 2T 5G (Gray Shadow, 128 GB) (8 GB RAM)',
'OnePlus Nord (Blue Marble, 128 GB) (8 GB RAM)',
'OnePlus Nord (Gray Onyx, 64 GB) (6 GB RAM)']
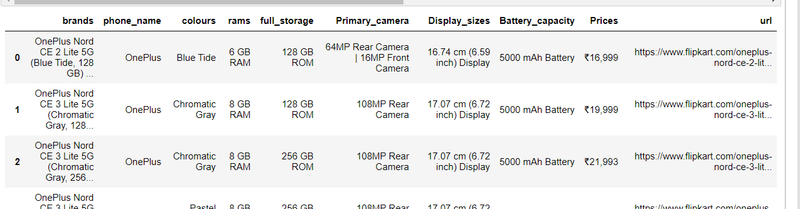
step8: make dataframe of each product
import pandas as pd
df= pd.DataFrame({'brands':brands,'phone_name':phone_name,'colours':colours,'rams':rams,'full_storage':full_storage,'Primary_camera':Primary_camera,'Display_sizes':Display_sizes,'Battery_capacity':Battery_capacity,'Prices':Prices,'url':Product_url})
df
======================================================
Another Example
Write a program to scrap all the available details of best gaming laptops from digit.in.
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
How to concatnate the url
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
step 3: store all url in list to itereate them using for loop
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
output

step4:collect each product detail seprately
driver=webdriver.Chrome()
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
brand_laptop = []
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = element = driver.find_element(By.CLASS_NAME, 'floatleft')
brand_laptop.append(element.text)
except NoSuchElementException:
brand_laptop.append("not present")
brand_laptop
output
['HP Omen 17-Ck2008TX 13th Gen Core I7-13700HX',
'MSI GT77 Titan 12UHS-054IN 12th Gen Core I9-12900HX',
'Lenovo Legion 5i Pro 12th Gen Core I7-12700H (82RF00E1IN)',
'ASUS ROG Strix Scar 18 G834JZ-N5041WS 13th Gen Core I9-13980HX',
'Acer Predator Helios Neo 16 13th Gen Core I7-13700HX (PHN16-71)',
'ASUS ROG Zephyrus G14 Ryzen 9-6900HS (GA402RJZ-L4136WS)',
'MSI Cyborg 15 12th Gen Core I7-12650H (A12VF-205IN)']
driver=webdriver.Chrome()
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
brands = []
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
os = []
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = driver.find_element(By.XPATH, '//table[@class="woocommerce-product-attributes shop_attributes"]/tbody[1]/tr[1]/td[1]')
os.append(element.text)
except NoSuchElementException:
os.append("not present")
os
output

How to take specific tr or td inside specific table class and tr class
launch_date = []
driver=webdriver.Chrome()
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
brands = []
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = driver.find_element(By.XPATH, '//table[@class="woocommerce-product-attributes shop_attributes"]/tbody[1]/tr[2]/td[1]')
launch_date.append(element.text)
except NoSuchElementException:
launch_date.append("not present")
launch_date
output

modal_name = []
driver=webdriver.Chrome()
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
brands = []
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = driver.find_element(By.XPATH, '//table[@class="woocommerce-product-attributes shop_attributes"]/tbody[1]/tr[3]/td[1]')
modal_name.append(element.text)
except NoSuchElementException:
modal_name.append("not present")
modal_name
output

display_size = []
driver=webdriver.Chrome()
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
brands = []
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
for el in urls:
driver.get(el)
time.sleep(5)
try:
element =driver.find_element(By.XPATH, '//tr[@class="attribute_row attribute_row_display"]/td[1]/table[1]/tbody[1]/tr[1]/td[1]')
display_size.append(element.text)
except NoSuchElementException:
display_size.append("not present")
display_size
connectivity = []
driver=webdriver.Chrome()
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
brands = []
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = driver.find_element(By.XPATH, '//tr[@class="attribute_row attribute_row_connectivity"]/td[1]/table[1]/tbody[1]/tr[1]/td[1]')
connectivity.append(element.text)
except NoSuchElementException:
connectivity.append("not present")
connectivity
included_ram = []
driver=webdriver.Chrome()
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
brands = []
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = driver.find_element(By.XPATH, '//tr[@class="attribute_row attribute_row_memory"]/td[1]/table[1]/tbody[1]/tr[1]/td[1]')
included_ram.append(element.text)
except NoSuchElementException:
included_ram.append("not present")
included_ram
speed_ram = []
driver=webdriver.Chrome()
base_url = 'https://www.digit.in/'
path = 'top-products/best-gaming-laptops-40.html'
url = base_url + path
driver.get(url)
brands = []
first_element = driver.find_elements(By.XPATH, '//*[@class="font130 mt0 mb10 mobilesblockdisplay "]/a')
urls = []
for el in first_element:
text = el.get_attribute('href')
urls.append(text)
urls
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = driver.find_element(By.XPATH, '//tr[@class="attribute_row attribute_row_memory"]/td[1]/table[1]/tbody[1]/tr[2]/td[1]')
speed_ram.append(element.text)
except NoSuchElementException:
speed_ram.append("not present")
speed_ram
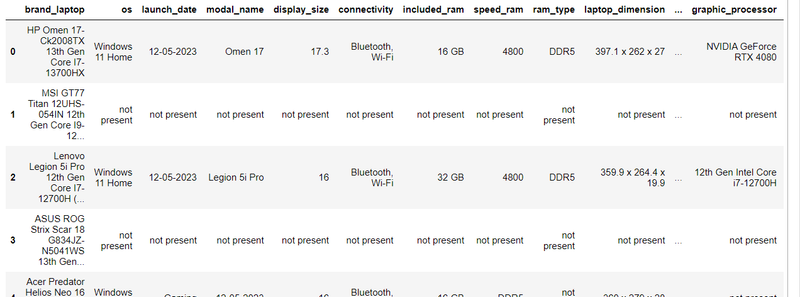
step5: make data frame
import pandas as pd
df= pd.DataFrame({'brand_laptop':brand_laptop,'os':os,'launch_date':launch_date,'modal_name':modal_name,'display_size':display_size,'connectivity':connectivity,'included_ram':included_ram,'speed_ram':speed_ram,'ram_type':ram_type,'laptop_dimension':laptop_dimension,
'laptop_weight':laptop_weight,'boost_clock_speed':boost_clock_speed,'cache_l3':cache_l3,'clock_speed':clock_speed,'core':core,'graphic_processor':graphic_processor,'processor_modal_name':processor_modal_name,'storage_drive_capacity':storage_drive_capacity,'storage_drive_type':storage_drive_type,
'battrey_type':battrey_type,'power_supply':power_supply,'cpu_memory_type':cpu_memory_type,'gpu_memory_amount':gpu_memory_amount,'resolution':resolution,'refresh_rate':refresh_rate})
df
==================================================
Write a python program to scrape a data for all available Hostels from https://www.hostelworld.com/ in
“London” location. You have to scrape hostel name, distance from city centre, ratings, total reviews, overall
reviews, privates from price, dorms from price, facilities and property description
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException,ElementClickInterceptedException
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get("https://www.hostelworld.com/")
step4:click london cards
How to select anchor tag within particular div using xpath
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import ElementClickInterceptedException
# Assuming you've already initialized your WebDriver 'driver'
wait = WebDriverWait(driver, 20)
try:
wait = WebDriverWait(driver, 10)
card = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@class="mosaic"]/div[1]/a')))
cards = driver.find_element(By.XPATH, '//*[@class="mosaic"]/div[1]/a')
cards.click()
except ElementClickInterceptedException as e:
# Handle the ElementClickInterceptedException here
print("ElementClickInterceptedException:", e)
step5:scrape the hostel_name
element = driver.find_elements(By.XPATH, '//*[@class="property-name"]/span')
hostel_name=[]
for element in element:
elements=element.text
hostel_name.append(elements)
hostel_name
output

step6:scrape the distance
element = driver.find_elements(By.XPATH, '//*[@class="property-distance"]/span[2]')
distance=[]
for element in element:
elements=element.text
distance.append(elements)
distance
output

step7:scrape the rating
How to select particular span tag using xpath
element = driver.find_elements(By.XPATH, '//*[@class="rating-score"]/span[1]')
rating=[]
for element in element:
elements=element.text
rating.append(elements)
rating
output

step8:scrape the total_review
element = driver.find_elements(By.XPATH, '//*[@class="review"]/span[1]')
total_review=[]
for element in element:
elements=element.text
total_review.append(elements)
total_review
output

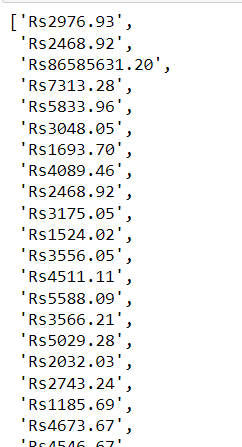
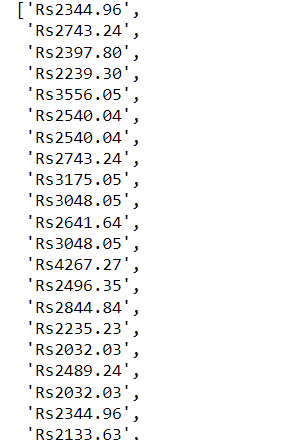
step9:scrape the private_form_price
element = driver.find_elements(By.XPATH, '//*[@class="property-accommodations"]/div/div[1]/div[2]/strong')
private_form_price=[]
for element in element:
elements=element.text
private_form_price.append(elements)
private_form_price
output
step10:scrape the dorm_form_price
How to select strong tag within particular div using xpath
element = driver.find_elements(By.XPATH, '//*[@class="property-accommodations"]/div/div[2]/div[2]/strong')
dorm_form_price=[]
for element in element:
elements=element.text
dorm_form_price.append(elements)
dorm_form_price
output
step11:scrape the desc
store all url in list and iterate using for loop to scrape detail
element = driver.find_elements(By.XPATH, '//*[@class="property-listing-cards"]/a')
urls = []
for el in element:
text = el.get_attribute('href')
urls.append(text)
urls
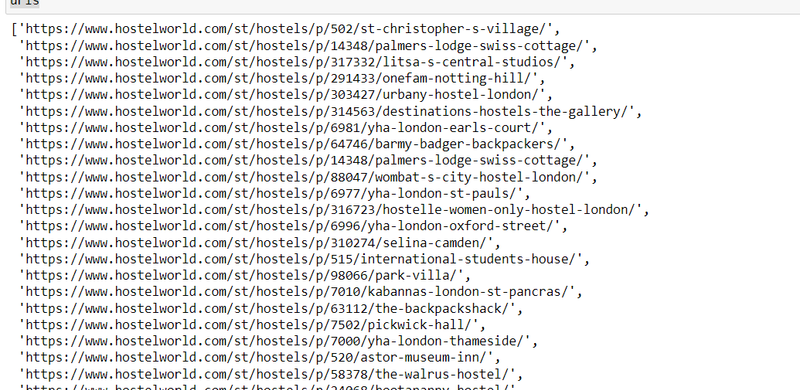
desc=[]
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = driver.find_element(By.XPATH, '//*[@class="description-body"]/div[1]')
desc.append(element.text)
except NoSuchElementException:
desc.append("not present")
desc
output

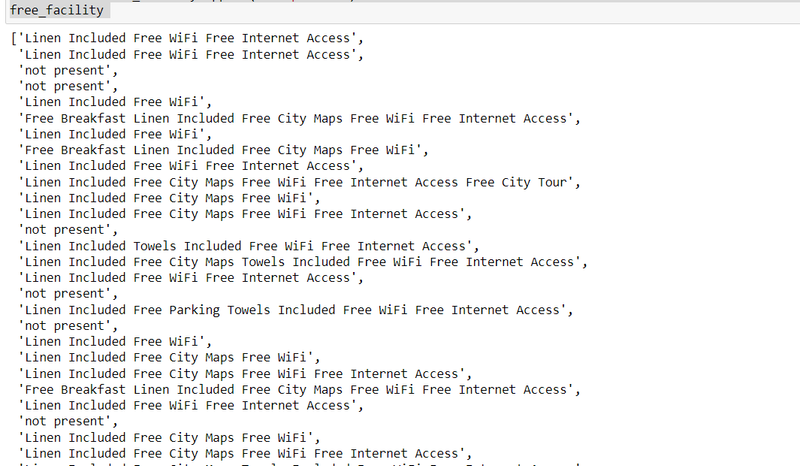
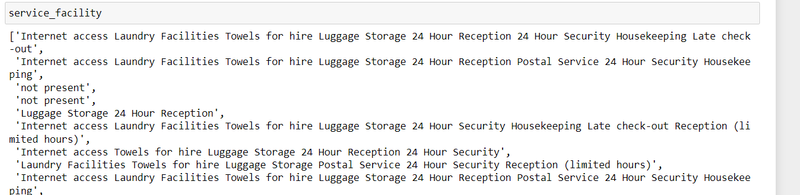
step12:scrape the facility
free_facility=[]
general_facility=[]
service_facility=[]
food_facility=[]
entertain_facility=[]
for el in urls:
driver.get(el)
time.sleep(5)
try:
element = driver.find_element(By.XPATH, '//*[@class="facility-sections"]/li[1]/ul')
general = driver.find_element(By.XPATH, '//*[@class="facility-sections"]/li[2]/ul')
service = driver.find_element(By.XPATH, '//*[@class="facility-sections"]/li[3]/ul')
food = driver.find_element(By.XPATH, '//*[@class="facility-sections"]/li[4]/ul')
entertain = driver.find_element(By.XPATH, '//*[@class="facility-sections"]/li[5]/ul')
free_facility.append(element.text)
general_facility.append(general.text)
service_facility.append(service.text)
food_facility.append(food.text)
entertain_facility.append(entertain.text)
except NoSuchElementException:
free_facility.append("not present")
general_facility.append("not present")
service_facility.append("not present")
food_facility.append("not present")
entertain_facility.append("not present")
free_facility
output


Top comments (0)