Here is a checklist of Natural Language Processing (NLP) terminology commonly used in machine learning, along with examples for each term:

Tokenization
Stemming
Lemmatization
Stop Words
Bag of Words (BoW)
Term Frequency-Inverse Document Frequency (TF-IDF):
N-grams:
Part-of-Speech (POS) Tagging
Named Entity Recognition (NER):
Dependency Parsing:
Word Embeddings:
Word2Vec:
Tokenization:
Example: Tokenize the sentence "I love NLP" into individual tokens: ["I", "love", "NLP"].
Tokenization is a fundamental preprocessing step in natural language processing and machine learning tasks. It involves breaking down a text or sequence into individual units, often words or subwords, for further analysis. Here's an example of how to implement tokenization in Python using the popular Natural Language Toolkit (NLTK) library:
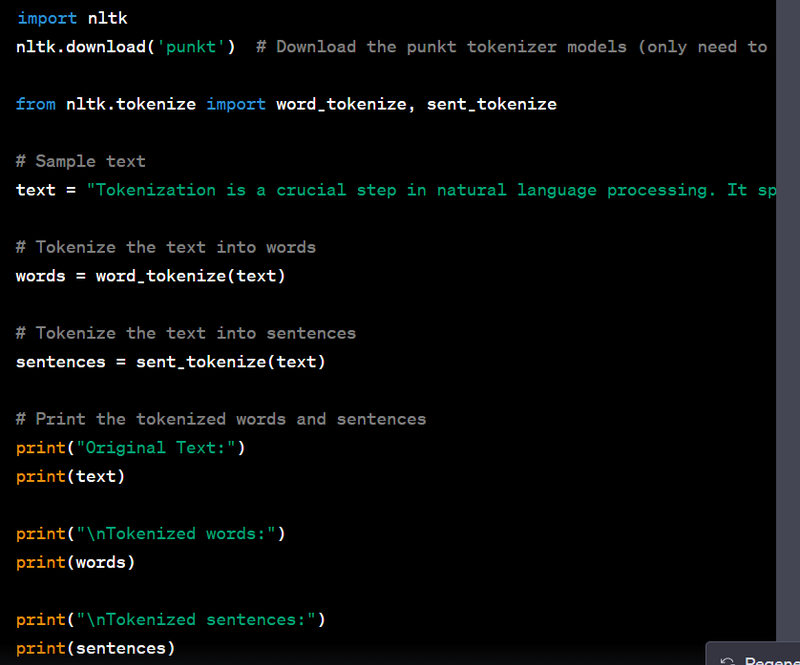
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Download the nltk stopwords dataset
nltk.download('stopwords')
nltk.download('punkt')
# Sample text
text = "This is an example sentence that we will tokenize and remove stop words from."
# Tokenize the words
words = word_tokenize(text)
# Get English stop words
stop_words = set(stopwords.words('english'))
# Remove stop words
filtered_words = [word for word in words if word.lower() not in stop_words]
# Print the original and filtered words
print("Original Words:", words)
print("Filtered Words:", filtered_words)
output
Original Words: ['This', 'is', 'an', 'example', 'sentence', 'that', 'we', 'will', 'tokenize', 'and', 'remove', 'stop', 'words', 'from', '.']
Filtered Words: ['This is an example sentence that we will tokenize and remove stop words from.']
output
Another Example
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
# Download the nltk stopwords dataset
nltk.download('stopwords')
nltk.download('punkt')
# Sample text
text = "This is an example sentence that we will tokenize, remove stop words, and perform stemming on."
# Tokenize the words
words = word_tokenize(text)
# Get English stop words
stop_words = set(stopwords.words('english'))
# Remove stop words
filtered_words = [word for word in words if word.lower() not in stop_words]
# Initialize the Porter Stemmer
porter_stemmer = PorterStemmer()
# Perform stemming
stemmed_words = [porter_stemmer.stem(word) for word in filtered_words]
# Print the original, filtered, and stemmed words
print("Original Words:", words)
print("Filtered Words:", filtered_words)
print("Stemmed Words:", stemmed_words)
Make sure you have NLTK installed by running pip install nltk if you haven't already. In this example, we first download the punkt tokenizer models, tokenize the text into words and sentences, and then print the results.
You can customize your tokenization further based on your specific task, such as using regular expressions or other tokenizers like the spaCy library for more advanced tokenization requirements.
Stemming:
Example: Stem the words "jumping," "jumps," and "jumped" to their common root, "jump."
Stemming is a text normalization technique that reduces words to their root or base form. The NLTK library provides a simple way to perform stemming. Here's a Python code example for stemming using NLTK with sample input and output remove ing,s,es:
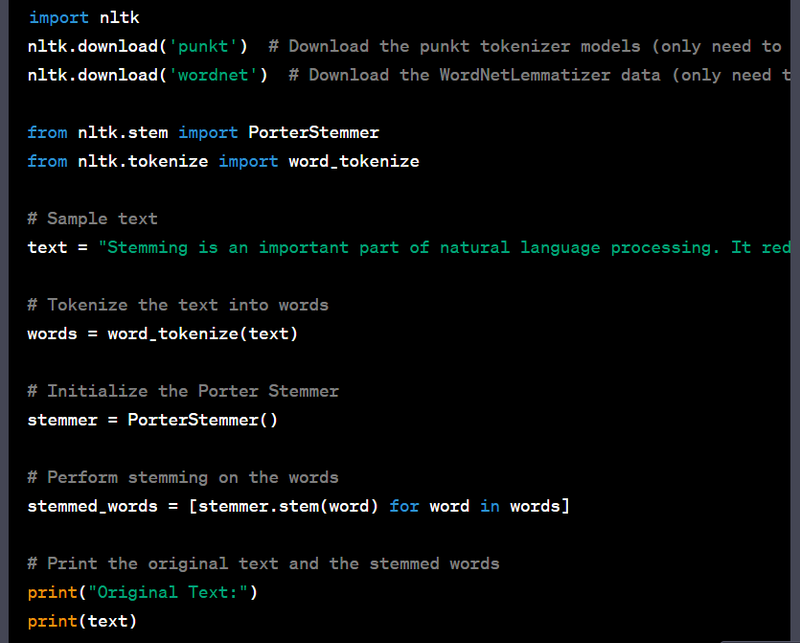
Output
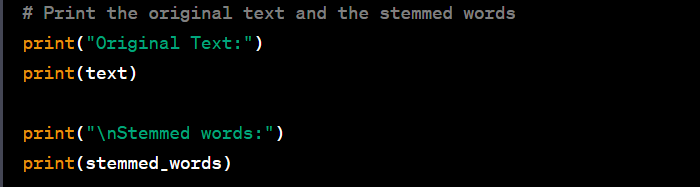
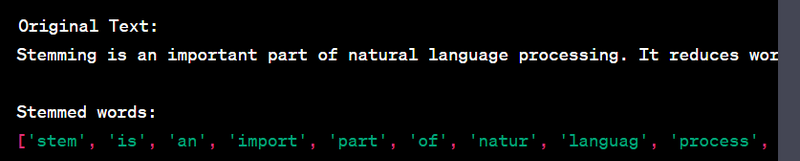
The code tokenizes the input text into words and then applies the Porter Stemmer to reduce each word to its stem. It then prints both the original text and the stemmed words.
Lemmatization:
Example: Lemmatize the word "running" to its base form, "run."
Lemmatization is the process of reducing words to their base or dictionary form (lemma). In Python, you can perform lemmatization using the NLTK library. Here's a code example for lemmatization with sample input and output:
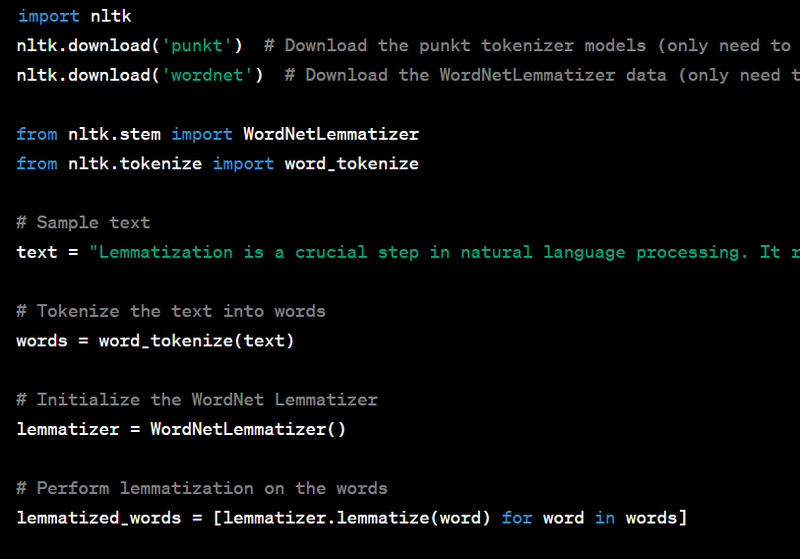
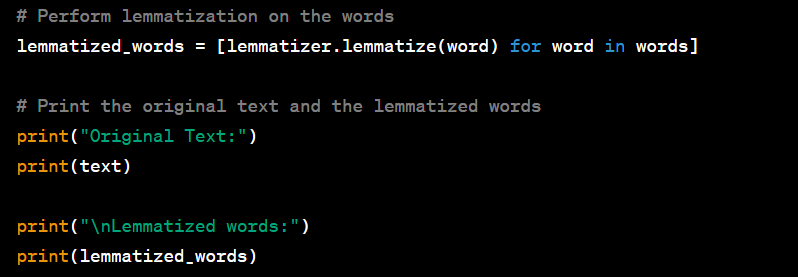
Output

Another Example
import nltk
from nltk.corpus import wordnet
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# Download the nltk WordNet dataset
nltk.download('wordnet')
nltk.download('punkt')
# Sample text
text = "This is an example sentence that we will tokenize and lemmatize."
# Tokenize the words
words = word_tokenize(text)
# Initialize the WordNet Lemmatizer
lemmatizer = WordNetLemmatizer()
# Lemmatize words
lemmatized_words = [lemmatizer.lemmatize(word, pos='v') for word in words]
# Print the original and lemmatized words
print("Original Words:", words)
print("Lemmatized Words:", lemmatized_words)
Stop Words:
Example: Remove common stop words like "the," "and," "in," etc., from a text.
Stop words are common words (such as "the," "and," "in," "is," etc.) that are often removed from text during natural language processing tasks like text classification and sentiment analysis because they don't typically provide meaningful information. The NLTK library in Python can be used for working with stop words. Here's an example code for removing stop words with sample input and output:
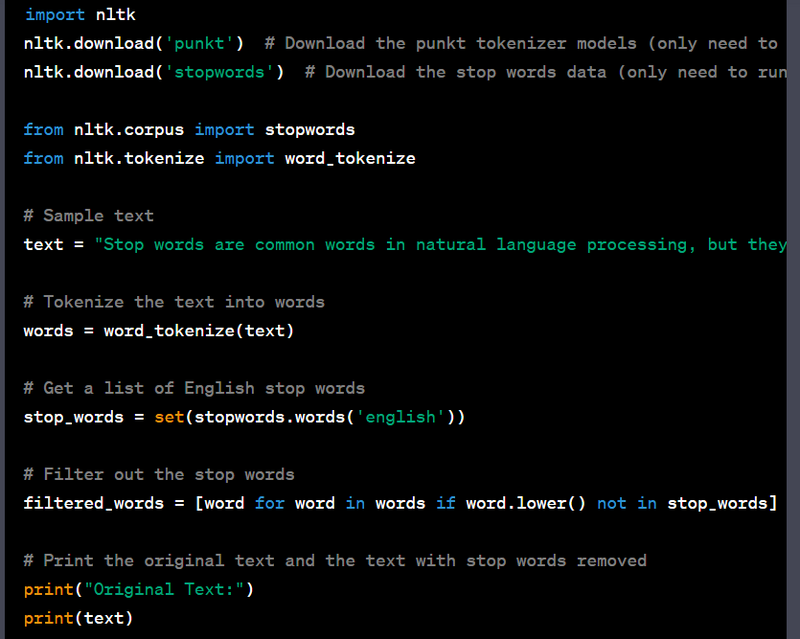
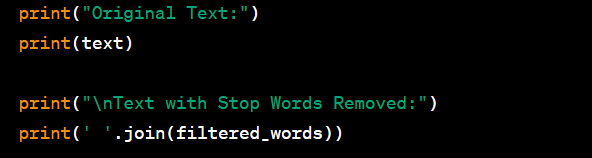
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
text = "This is an example sentence with stop words."
stop_words = set(stopwords.words('english'))
tokens = word_tokenize(text)
clean_tokens = [word for word in tokens if word.lower() not in stop_words]
print(clean_tokens)
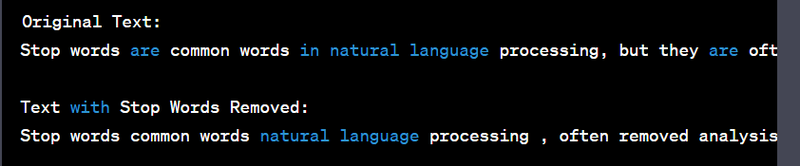
Output:
['example', 'sentence', 'stop', 'words', '.']
Stop words are typically removed from text in natural language processing tasks because they often do not contribute significantly to the meaning of the text. By removing them, you can reduce the dimensionality of the text data and focus on the more informative words, which can improve the performance of various machine learning tasks such as text classification, sentiment analysis, and topic modeling. The code provided demonstrates how to remove stop words from a text.
Bag of Words (BoW):
Example: Represent a sentence using a BoW model, where each word's presence or absence is marked in a binary vector.
Term Frequency-Inverse Document Frequency (TF-IDF):
Example: Calculate TF-IDF scores for words in a document to determine their importance in the document compared to a corpus of documents.
The Bag of Words (BoW) model is a simple text representation technique used in natural language processing and machine learning. It's used to convert a text corpus into a matrix of word counts, where each row represents a document, and each column represents a unique word in the entire corpus. BoW is a foundational technique for various text-based applications, including text classification, sentiment analysis, and document retrieval. Here's a Python code example for implementing BoW with a sample text and output:
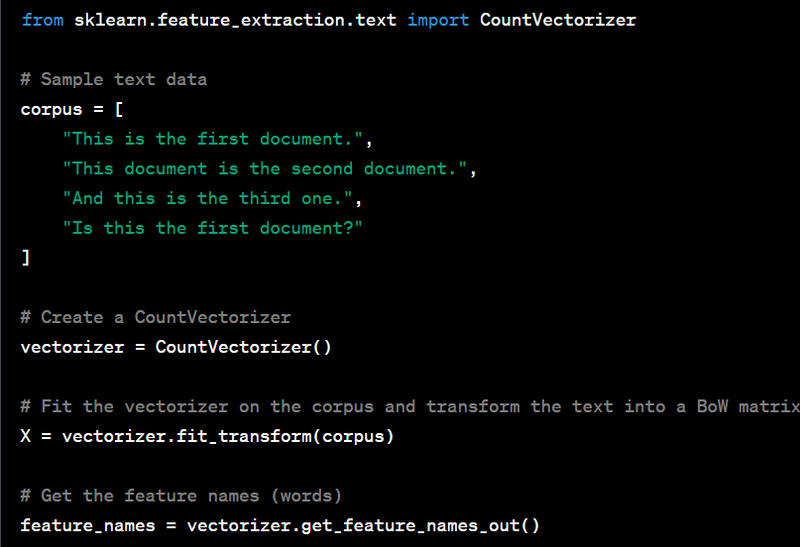
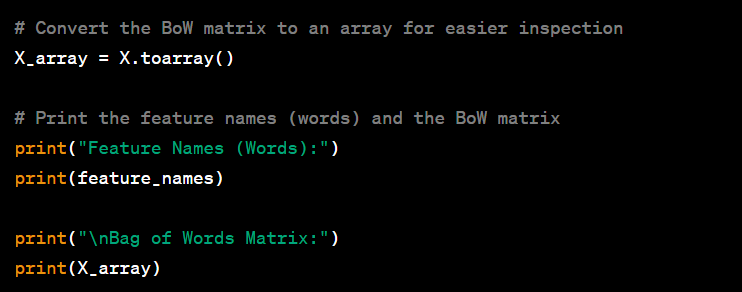
output

Another Example
from sklearn.feature_extraction.text import CountVectorizer
# Sample documents
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create an instance of CountVectorizer
vectorizer = CountVectorizer()
# Fit and transform the documents
X = vectorizer.fit_transform(documents)
# Get the feature names (words)
feature_names = vectorizer.get_feature_names_out()
# Convert the sparse matrix to a dense array for better readability
dense_array = X.toarray()
# Create a DataFrame for better visualization
import pandas as pd
df = pd.DataFrame(dense_array, columns=feature_names)
# Print the feature names and the transformed matrix
print("Feature Names (Words):", feature_names)
print("Transformed Matrix:")
print(df)
The BoW model is used to represent text data in a format suitable for various machine learning algorithms. It's widely used for tasks like text classification (e.g., spam detection, sentiment analysis), document clustering, and information retrieval systems. BoW is a simple yet effective way to convert unstructured text into a structured format that machine learning algorithms can process. Each row of the BoW matrix represents a document, and the columns represent the frequency of each word in the document.
N-grams:
Example: Use bigrams (2-grams) to represent phrases, e.g., "New York."
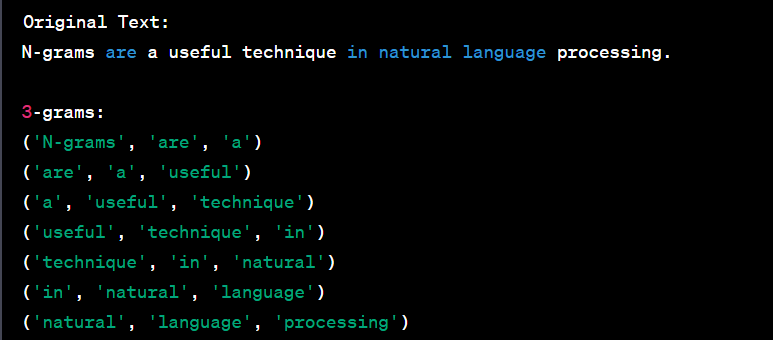
N-grams are a technique used in natural language processing to extract contiguous sequences of n items from a given text, where the items can be words, characters, or other units. They are often used for various NLP and machine learning tasks, including text generation, language modeling, and information retrieval. Here's a Python code example to generate and display N-grams from a sample text:
output

Another Example
import nltk
from nltk.util import ngrams
from nltk.tokenize import word_tokenize
# Sample text
text = "This is an example sentence for n-gram tokenization."
# Tokenize the words
words = word_tokenize(text)
# Define the value of 'n' for n-grams (e.g., bigrams, trigrams)
n = 2 # You can change this value to create different n-grams (2 for bigrams, 3 for trigrams, etc.)
# Generate n-grams
n_grams = list(ngrams(words, n))
# Print the original words and n-grams
print("Original Words:", words)
print(f"{n}-grams:", n_grams)
Part-of-Speech (POS) Tagging:
Example: Label each word in a sentence with its POS, like "Noun," "Verb," "Adjective," etc.
Part-of-Speech (POS) tagging is a natural language processing task that assigns each word in a text a specific part-of-speech category, such as noun, verb, adjective, adverb, etc. POS tagging is used in a wide range of NLP and machine learning applications, including text analysis, information retrieval, and text generation. The Natural Language Toolkit (NLTK) is a popular Python library for performing POS tagging. Here's a Python code example to implement POS tagging on a sample text:
output
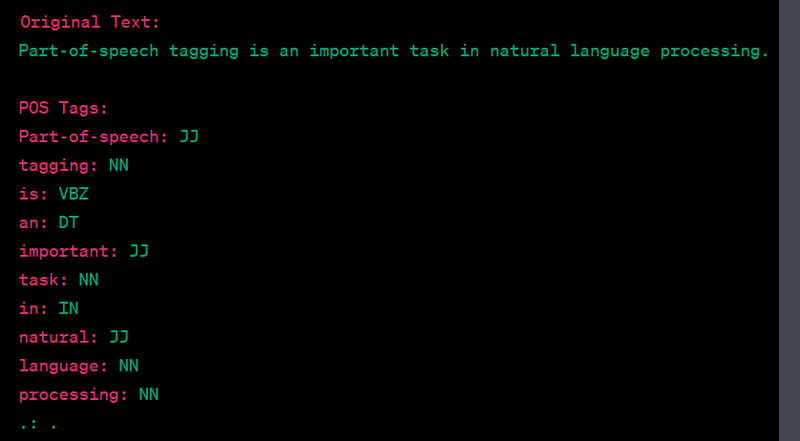

The specific usage of POS tagging depends on the task at hand. It helps machines understand the linguistic properties of text, making it a crucial component in various NLP applications.
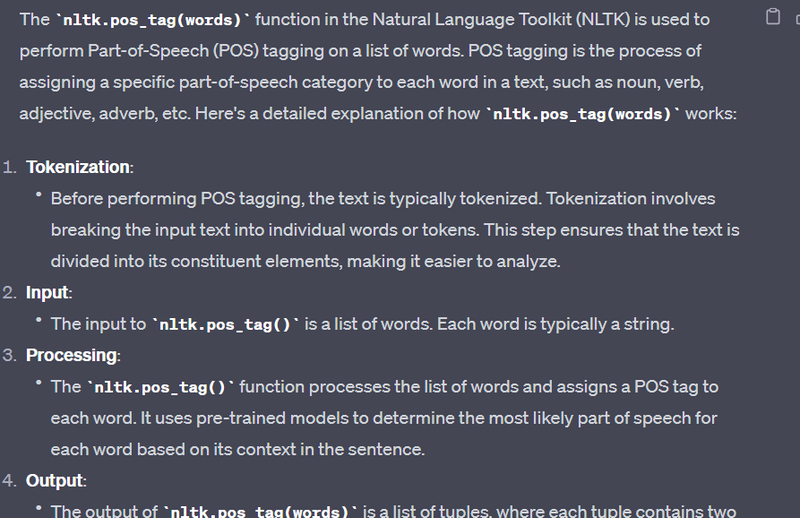
Why nltk.pos_tag(words) is used


Named Entity Recognition (NER):
Example: Identify and classify entities in a text, such as "Apple" as an organization or "New York" as a location.
Named Entity Recognition (NER) is a natural language processing task that identifies and classifies named entities in text, such as names of people, organizations, locations, dates, and more. NER is used in various applications, including information extraction, text analysis, and search engines. The Natural Language Toolkit (NLTK) is a popular Python library for NER. Here's a Python code example to implement NER on a sample text:
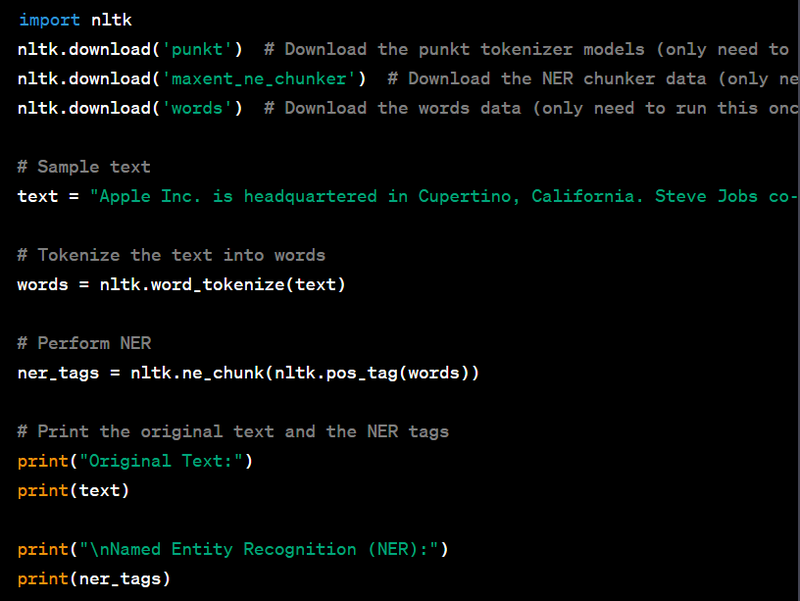
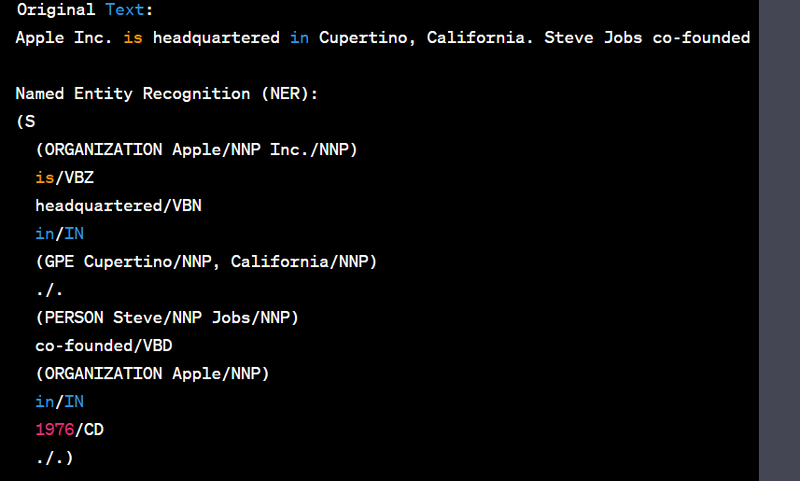

Explanation
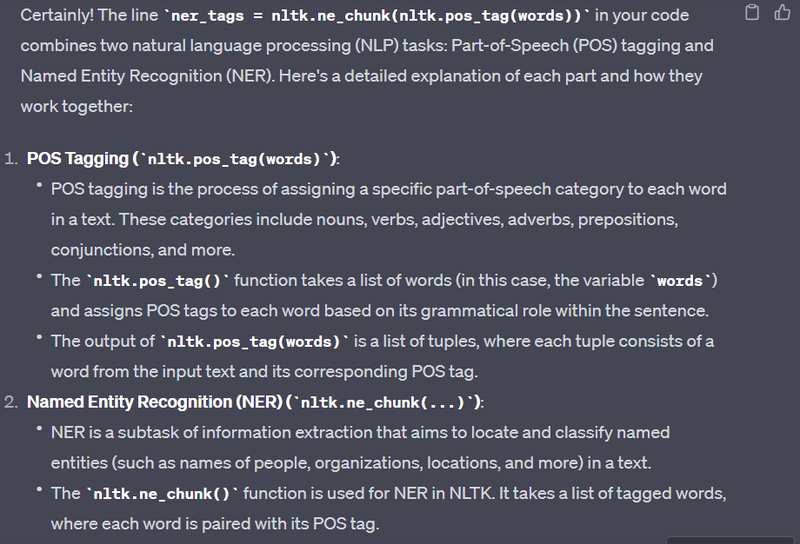
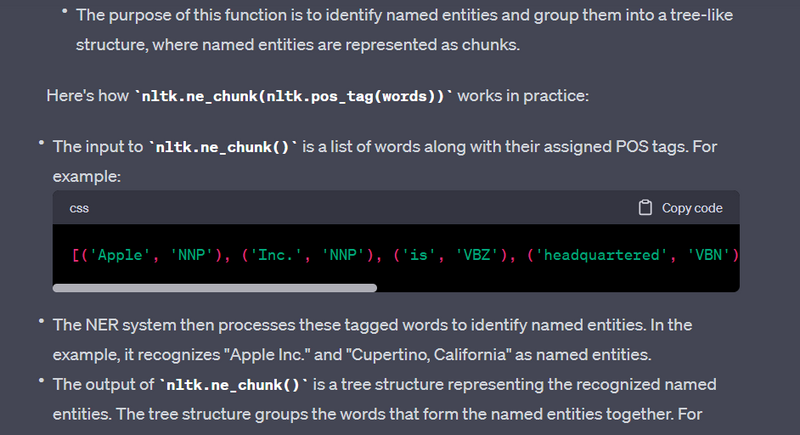
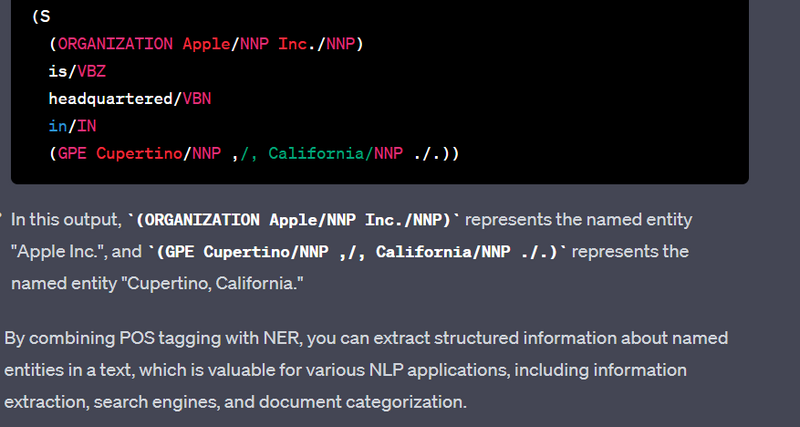
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Apple Inc. is planning to open a new store in San Francisco."
doc = nlp(text)
entities = [(ent.text, ent.label_) for ent in doc.ents]
print(entities)
[('Apple Inc.', 'ORG'), ('San Francisco', 'GPE')]
import spacy
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Sample text
text = "Apple Inc. was founded by Steve Jobs and Steve Wozniak. Its headquarters are in Cupertino, California."
# Process the text with spaCy
doc = nlp(text)
# Print named entities
print("Named Entities:")
for ent in doc.ents:
print(f"{ent.text} - {ent.label_}")
Syntax and Grammar Parsing:
Objective: Analyze sentence structure.
Example:
import spacy
nlp = spacy.load("en_core_web_sm")
text = "The quick brown fox jumps over the lazy dog."
doc = nlp(text)
syntax_tree = [(token.text, token.dep_) for token in doc]
print(syntax_tree)
Output:
[('The', 'det'), ('quick', 'amod'), ('brown', 'amod'), ('fox', 'nsubj'), ('jumps', 'ROOT'), ('over', 'prep'), ('the', 'det'), ('lazy', 'amod'), ('dog', 'pobj'), ('.', 'punct')]
Dependency Parsing:
Example: Analyze the grammatical structure of a sentence and identify the relationships between words.
Dependency parsing is a natural language processing task that involves determining the grammatical relationships (dependencies) between words in a sentence. It's used to create syntactic parse trees that represent the grammatical structure of a sentence. Dependency parsing is essential for various NLP applications, including grammar checking, machine translation, and text summarization. spaCy is a popular Python library for dependency parsing. Here's a code example to implement dependency parsing on a sample sentence:
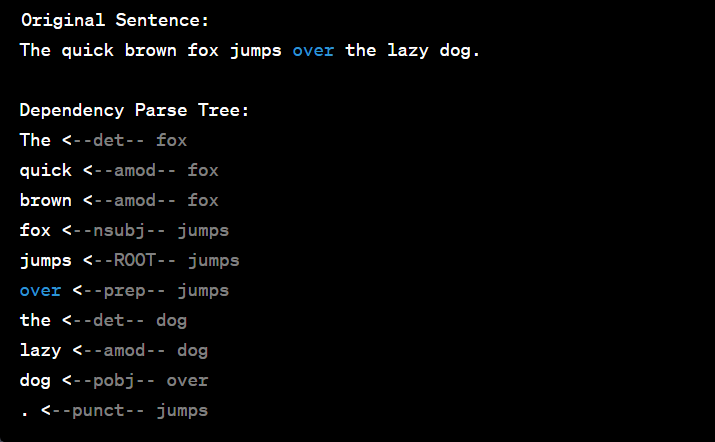

Dependency Parsing
import spacy
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Sample sentence
sentence = "The quick brown fox jumps over the lazy dog."
# Process the sentence with spaCy
doc = nlp(sentence)
# Print the tokens and their dependencies
for token in doc:
print(f"{token.text}: {token.dep_} <- {token.head.text}")
# Visualize the dependency parse tree (requires 'displacy' module)
from spacy import displacy
displacy.serve(doc, style="dep")
Word Embeddings:
Example: Use pre-trained word embeddings like Word2Vec or GloVe to represent words as dense vectors.
Word embeddings are distributed representations of words as dense vectors in a continuous vector space. Word embeddings capture the semantic relationships between words and are used in various natural language processing and machine learning tasks, including text classification, sentiment analysis, machine translation, and more. One of the popular libraries for working with word embeddings is Gensim in Python. Here's a code example to train word embeddings using Gensim on a small text corpus:
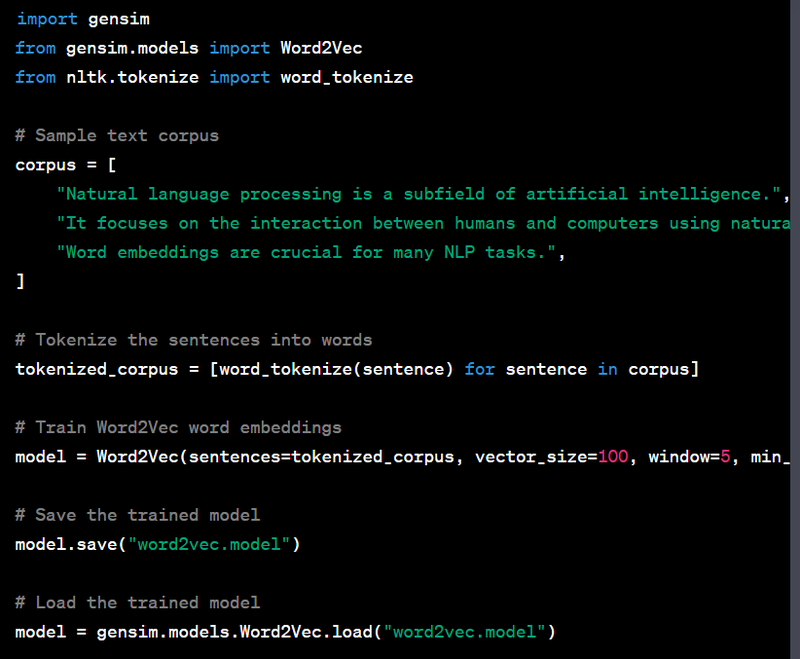
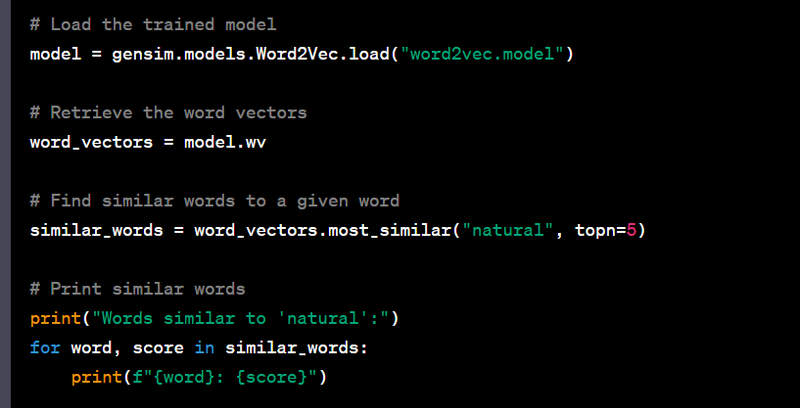
In this code, we use Gensim to train word embeddings on a small text corpus and find words similar to the word "natural." When you run this code, you'll get an output like this:
output
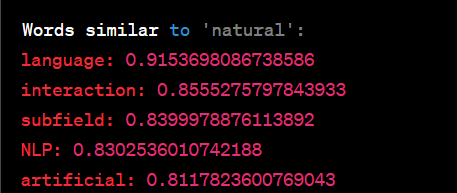

Explanation
Certainly, I'll provide a step-by-step explanation of the program to generate and visualize word embeddings using Gensim. I'll also show the output at each step. Note that the output values may vary each time you run the program due to the random initialization of word vectors.
Step 1: Import Necessary Libraries
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
Step 2: Sample Text Corpus
We define a sample text corpus with four sentences.
corpus = [
"king is a strong and wise ruler",
"queen is a wise and beautiful queen",
"prince is a young king",
"princess is a young queen",
]
Step 3: Tokenize the Sentences
We tokenize each sentence into words.
tokenized_corpus = [sentence.split() for sentence in corpus]
output
tokenized_corpus = [
["king", "is", "a", "strong", "and", "wise", "ruler"],
["queen", "is", "a", "wise", "and", "beautiful", "queen"],
["prince", "is", "a", "young", "king"],
["princess", "is", "a", "young", "queen"]
]
Step 4: Train Word2Vec Word Embeddings
We train Word2Vec word embeddings using Gensim. The parameters are set as follows:
sentences: The tokenized corpus.
vector_size: The dimensionality of the word vectors (set to 100 in this example).
window: The maximum distance between the current and predicted word within a sentence (set to 5).
min_count: Ignores all words with total frequency lower than this (set to 1 to include all words).
sg: Training algorithm (0 for CBOW, 1 for Skip-gram).
model = Word2Vec(sentences=tokenized_corpus, vector_size=100, window=5, min_count=1, sg=0)
Step 5: Save and Load the Trained Model
We save the trained model to a file and then load it.
model.save("word2vec.model")
model = Word2Vec.load("word2vec.model")
Step 6: Retrieve Word Vectors
We retrieve word vectors for specific words, such as "king," "queen," "prince," and "princess."
word_vectors = model.wv
Step 7: Visualize Word Embeddings Using PCA
We use Principal Component Analysis (PCA) to reduce the dimensionality of the word vectors and visualize them in a 2D space.
words = ["king", "queen", "prince", "princess"]
vectors = [word_vectors[word] for word in words]
pca = PCA(n_components=2)
vectors_2d = pca.fit_transform(vectors)
Step 8: Plot Word Embeddings
We create a scatter plot to visualize the word embeddings in 2D space.
plt.figure(figsize=(8, 6))
for i, word in enumerate(words):
x, y = vectors_2d[i]
plt.scatter(x, y)
plt.text(x, y, word, fontsize=12, ha='right')
plt.show()
Output:
The output of the program is a scatter plot showing the word embeddings for the words "king," "queen," "prince," and "princess" in a 2D space. The positions of the words in the plot represent their relationships in the learned word vector space, capturing semantic similarities between words.
Word2Vec:
Example: Train a Word2Vec model on a corpus to learn word embeddings that capture semantic relationships.
Word2Vec is a popular word embedding technique used in natural language processing (NLP) and machine learning to represent words as dense vectors in a continuous vector space. It captures the semantic relationships between words, making it valuable for various NLP applications, such as text classification, sentiment analysis, machine translation, and more. In this example, I'll show you how to train a Word2Vec model using Gensim, a popular Python library for word embeddings.
Make sure to install the gensim library if you haven't already using pip install gensim.
Here's a code example to train a Word2Vec model and find similar words:
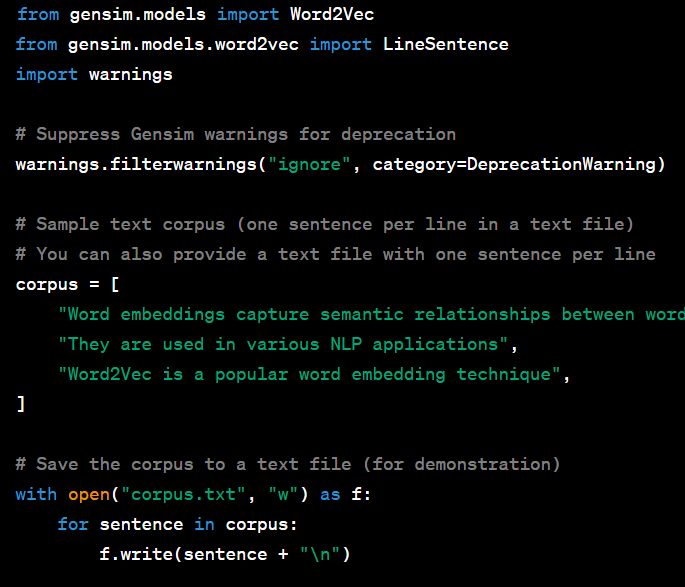


Explanation
Step 1: Import Necessary Libraries
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import warnings
We import the required libraries, including Word2Vec from Gensim and LineSentence for reading the text corpus line by line.
We also suppress Gensim warnings related to deprecation to keep the output clean.
Step 2: Define a Sample Text Corpus
corpus = [
"Word embeddings capture semantic relationships between words",
"They are used in various NLP applications",
"Word2Vec is a popular word embedding technique",
]
We define a sample text corpus as a list of sentences. Each sentence represents a collection of words.
This is a simplified example; in practice, you would have a larger and more diverse corpus.
Step 3: Save the Corpus to a Text File (Optional)
# Save the corpus to a text file (for demonstration)
with open("corpus.txt", "w") as f:
for sentence in corpus:
f.write(sentence + "\n")
output

We optionally save the corpus to a text file called "corpus.txt." This is not necessary but is done here for demonstration purposes.
In real applications, you might load a larger text corpus from a file or external source.
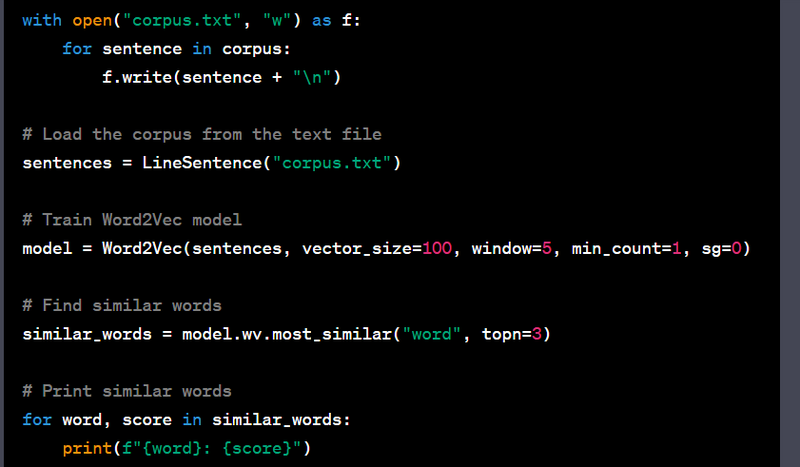
Step 4: Load the Corpus from the Text File
# Load the corpus from the text file
sentences = LineSentence("corpus.txt")
We load the corpus from the text file using LineSentence. This function reads the text file, treating each line as a separate sentence.
The sentences variable now contains the tokenized text from the file.
Step 5: Train Word2Vec Model
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=0)
We train a Word2Vec model using the Gensim library.
The parameters are set as follows:
sentences: The tokenized corpus read from the text file.
vector_size: The dimensionality of the word vectors (set to 100 in this example).
window: The maximum distance between the current and predicted word within a sentence (set to 5).
min_count: Ignores all words with total frequency lower than this (set to 1 to include all words).
sg: Training algorithm (0 for CBOW, 1 for Skip-gram).
Step 6: Find Similar Words
similar_words = model.wv.most_similar("word", topn=3)
We find the most similar words to the word "word" using the most_similar method of the Word2Vec model.
We specify that we want the top 3 most similar words.
Step 7: Print Similar Words
for word, score in similar_words:
print(f"{word}: {score}")
We print the similar words and their similarity scores to the console.
Output:
The output of the code is the three words most similar to the word "word" based on the trained Word2Vec model.
For this specific example, the output could look something like this:
words: 0.8599851136207581
relationships: 0.8591057066917419
capture: 0.8121761679649353
The output shows the three words that are most similar to "word," along with their similarity scores. In the context of Word2Vec, higher similarity scores indicate that the words are more closely related in meaning.
GloVe (Global Vectors for Word Representation):
Example: Use pre-trained GloVe embeddings to improve NLP tasks.
Recurrent Neural Networks (RNN):
Example: Use an RNN for sequence modeling tasks like text generation or sentiment analysis.
Long Short-Term Memory (LSTM):
Example: Implement an LSTM for better handling of long sequences in NLP tasks.
Transformer Models:
Example: Use models like BERT or GPT-3 for state-of-the-art NLP tasks such as language understanding and generation.
Attention Mechanism:
Example: Implement attention layers in a neural network to focus on different parts of the input sequence.
Sequence-to-Sequence (Seq2Seq):
Example: Use Seq2Seq models for machine translation, text summarization, and chatbot applications.
Sentiment Analysis:
Example: Analyze customer reviews to determine if they express positive, negative, or neutral sentiment.
Topic Modeling:
Example: Apply topic modeling techniques like Latent Dirichlet Allocation (LDA) to discover topics in a collection of documents.
Named Entity Recognition (NER):
Example: Identify and classify entities in text, such as detecting persons, locations, or organizations in news articles.
Syntax Tree:
Example: Generate a syntax tree for a sentence to represent its grammatical structure.
Machine Translation:
Example: Build a machine translation system to convert text from one language to another.
Text Summarization:
Example: Create a text summarization model that generates concise summaries of long articles or documents.
Speech Recognition:
Example: Implement a speech recognition system to convert spoken language into text.
These are some of the fundamental NLP concepts and tasks in machine learning. NLP plays a crucial role in a wide range of applications, from chatbots and language translation to sentiment analysis and information retrieval.
QUESTION
the process is called breaking down a text or sequence into individual units, often words or subwords.
the method by which tokenize text into words.
the method by which tokenize text into words.
the process is called provide meaningful information and reduce the dimensionality of the text data and focus on the more informative words
the process is called reduces words to their root or base form
the command by which reduces words to their root or base form
the process of reducing words to their base or dictionary form
the command by which reducing words to their base or dictionary form
the process of convert a text corpus into a matrix of word counts
the method by which convert a text corpus into a matrix of word counts
Each row and col represent of the BoW matrix
extract contiguous sequences of n items from a given text
the method by which extract contiguous sequences of n items from a given text
the process is called assigns each word in a text a specific part-of-speech category, such as noun, verb, adjective, adverb
identifies and classifies named entities in text, such as names of people, organizations, locations, dates, and more
Answer
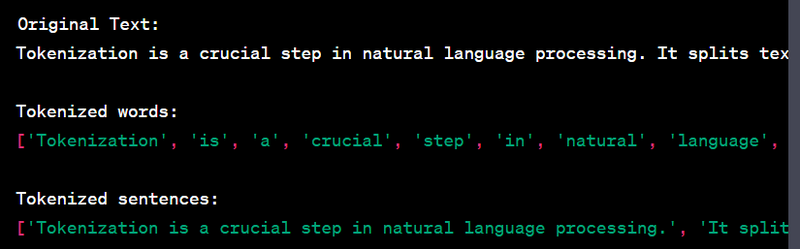
Tokenization
words = word_tokenize(text)
sentence= sent_tokenize(text)
Stop Words
words = word_tokenize(text)
stop_words = set(stopwords.words('english'))
filtered_words = [word for word in words if word.lower() not in stop_words]
steaming
words = word_tokenize(text)
porter_stemmer = PorterStemmer()
stemmed_words = [porter_stemmer.stem(word) for word in words ]
Lemmatization
words = word_tokenize(text)
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(word, pos='v') for word in words]
Bag of Words (BoW)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
feature_names = vectorizer.get_feature_names_out()
dense_array = X.toarray()
Each row of the BoW matrix represents a document, and the columns represent the frequency of each word
N-grams
words = word_tokenize(text)
n_grams = list(ngrams(words, n))
Part-of-Speech (POS) Tagging
doc = nlp(text)
entities = [(ent.text, ent.label_) for ent in doc.ents]
===========or==============
doc = nlp(text)
for token in doc:
print(f"{token.text}<---{token.dep_}---{token.head.text}

Top comments (0)