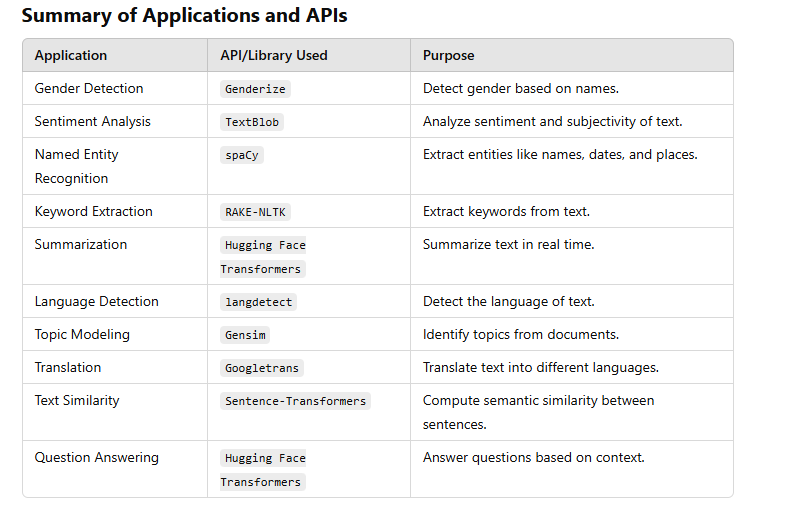
Gender Detection Using Genderize
Application: Detect gender based on names in real time.
from genderize import Genderize
def detect_gender(name):
gender = Genderize().get([name])
return gender[0]['gender'] if gender else None
# Test the function
name = "Alice"
print(f"Detected Gender: {detect_gender(name)}")
=================or================================
import spacy
from genderize import Genderize # Install via pip install genderize
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
def gender_detector(doc):
detected_gender = None
# Detect names using SpaCy's NER
for ent in doc.ents:
if ent.label_ == "PERSON": # Detect named entities labeled as PERSON
try:
# Use Genderize API to infer gender
gender_data = Genderize().get([ent.text])
detected_gender = gender_data[0]['gender']
break # Detect gender from the first name found
except Exception as e:
print(f"Error fetching gender: {e}")
continue
doc._.gender = detected_gender
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("gender", default=None)
# Add the component to the pipeline
nlp.add_pipe(gender_detector, last=True)
# Test the pipeline
text = "John went to the park with Sarah."
doc = nlp(text)
print(f"Detected Gender: {doc._.gender}")
Sentiment Analysis Using TextBlob
Application: Perform sentiment analysis on text in real time.
from textblob import TextBlob
def analyze_sentiment(text):
sentiment = TextBlob(text).sentiment
return {"polarity": sentiment.polarity, "subjectivity": sentiment.subjectivity}
# Test the function
text = "I love programming with Python!"
print(f"Sentiment: {analyze_sentiment(text)}")
Named Entity Recognition Using spaCy
Application: Extract named entities like people, organizations, or dates.
import spacy
nlp = spacy.load("en_core_web_sm")
def extract_entities(text):
doc = nlp(text)
return [(ent.text, ent.label_) for ent in doc.ents]
# Test the function
text = "Google was founded by Larry Page and Sergey Brin in 1998."
print(f"Entities: {extract_entities(text)}")
Keyword Extraction Using RAKE-NLTK
Application: Extract key phrases from text for summarization or SEO.
from rake_nltk import Rake
def extract_keywords(text):
rake = Rake()
rake.extract_keywords_from_text(text)
return rake.get_ranked_phrases()
# Test the function
text = "Python is a popular programming language for data science and web development."
print(f"Keywords: {extract_keywords(text)}")
Summarization Using Hugging Face Transformers
Application: Summarize text in real time using a transformer model.
from transformers import pipeline
summarizer = pipeline("summarization")
def summarize_text(text):
return summarizer(text, max_length=50, min_length=25, do_sample=False)
# Test the function
text = "Python is a versatile language used for web development, data science, and machine learning. It's simple syntax makes it easy for beginners."
print(f"Summary: {summarize_text(text)}")
Language Detection Using langdetect
Application: Detect the language of a given text.
from langdetect import detect
def detect_language(text):
return detect(text)
# Test the function
text = "Bonjour tout le monde!"
print(f"Language: {detect_language(text)}")
Topic Modeling Using Gensim
Application: Identify topics from a collection of text documents.
from gensim.corpora.dictionary import Dictionary
from gensim.models import LdaModel
def topic_modeling(docs, num_topics=2):
dictionary = Dictionary(docs)
corpus = [dictionary.doc2bow(doc) for doc in docs]
lda = LdaModel(corpus, num_topics=num_topics, id2word=dictionary, passes=10)
return lda.print_topics()
# Test the function
docs = [["python", "machine", "learning"], ["java", "software", "development"]]
print(f"Topics: {topic_modeling(docs)}")
Translation Using Googletrans
Application: Translate text into different languages in real time.
from googletrans import Translator
def translate_text(text, target_language="fr"):
translator = Translator()
return translator.translate(text, dest=target_language).text
# Test the function
text = "Hello, how are you?"
print(f"Translated Text: {translate_text(text, 'es')}")
Text Similarity Using Sentence-Transformers
Application: Compute semantic similarity between sentences.
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('all-MiniLM-L6-v2')
def compute_similarity(sentence1, sentence2):
embeddings = model.encode([sentence1, sentence2])
similarity = util.cos_sim(embeddings[0], embeddings[1])
return similarity.item()
# Test the function
s1 = "I love programming."
s2 = "Programming is my passion."
print(f"Similarity: {compute_similarity(s1, s2)}")
Question Answering Using Hugging Face Transformers
Application: Answer questions based on a given context.
from transformers import pipeline
qa_pipeline = pipeline("question-answering")
def answer_question(question, context):
result = qa_pipeline(question=question, context=context)
return result["answer"]
# Test the function
context = "Python is a programming language that supports multiple programming paradigms, including structured, object-oriented, and functional programming."
question = "What paradigms does Python support?"
print(f"Answer: {answer_question(question, context)}")
Advanced API and libraries
Named Entity Recognition Using AllenNLP
Application: Extract detailed entities like organizations, products, and locations using AllenNLP's pre-trained models.
from allennlp.predictors.predictor import Predictor
import allennlp_models.tagging
predictor = Predictor.from_path("https://storage.googleapis.com/allennlp-public-models/ner-elmo.2021-02-12.tar.gz")
def extract_entities_allennlp(text):
result = predictor.predict(sentence=text)
return list(zip(result['words'], result['tags']))
# Test the function
text = "Microsoft was founded by Bill Gates in 1975."
print(f"Entities: {extract_entities_allennlp(text)}")
Spell Check Using SymSpell
Application: Detect and correct spelling errors in real time.
from symspellpy import SymSpell, Verbosity
sym_spell = SymSpell(max_dictionary_edit_distance=2)
sym_spell.load_dictionary("frequency_dictionary_en_82_765.txt", term_index=0, count_index=1)
def spell_check(word):
suggestions = sym_spell.lookup(word, Verbosity.CLOSEST, max_edit_distance=2)
return suggestions[0].term if suggestions else word
# Test the function
word = "progrmming"
print(f"Corrected Word: {spell_check(word)}")
Text Classification Using MonkeyLearn
Application: Classify text into categories such as sentiment, intent, or topic.
import requests
def classify_text_monkeylearn(text):
url = "https://api.monkeylearn.com/v3/classifiers/cl_pi3C7JiL/classify/"
headers = {"Authorization": "Token your_api_key"}
data = {"text_list": [text]}
response = requests.post(url, headers=headers, json=data)
return response.json()
# Test the function
text = "I love using Python for machine learning."
print(f"Classification: {classify_text_monkeylearn(text)}")
Text Summarization Using Sumy
Application: Generate extractive summaries for documents or articles.
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lsa import LsaSummarizer
def summarize_with_sumy(text, num_sentences=2):
parser = PlaintextParser.from_string(text, Tokenizer("english"))
summarizer = LsaSummarizer()
summary = summarizer(parser.document, num_sentences)
return " ".join([str(sentence) for sentence in summary])
# Test the function
text = "Python is a versatile language used for data science, web development, and more. It has a rich ecosystem of libraries."
print(f"Summary: {summarize_with_sumy(text)}")
Text-to-Speech Using gTTS
Application: Convert text into speech in real time.
from gtts import gTTS
def text_to_speech(text, lang="en"):
tts = gTTS(text=text, lang=lang)
tts.save("output.mp3")
return "Audio saved as output.mp3"
# Test the function
text = "Hello, welcome to the world of Python!"
print(text_to_speech(text))
Offensive Language Detection Using Perspective API
Application: Detect toxic or harmful language in text.
import requests
def detect_toxicity(text):
api_key = "your_api_key"
url = f"https://commentanalyzer.googleapis.com/v1alpha1/comments:analyze?key={api_key}"
data = {
"comment": {"text": text},
"languages": ["en"],
"requestedAttributes": {"TOXICITY": {}}
}
response = requests.post(url, json=data)
return response.json()["attributeScores"]["TOXICITY"]["summaryScore"]
# Test the function
text = "I hate you!"
print(f"Toxicity Score: {detect_toxicity(text)}")
Text Similarity Using Similarity API
Application: Compare two pieces of text for similarity.
import requests
def text_similarity(text1, text2):
api_key = "your_api_key"
url = "https://api.similarity.com/similarity"
headers = {"Authorization": f"Bearer {api_key}"}
data = {"text1": text1, "text2": text2}
response = requests.post(url, headers=headers, json=data)
return response.json()
# Test the function
text1 = "I enjoy programming."
text2 = "Programming is fun."
print(f"Similarity Score: {text_similarity(text1, text2)}")
Word Sense Disambiguation Using NLTK
Application: Disambiguate the meaning of words in context.
from nltk.corpus import wordnet
from nltk.wsd import lesk
def disambiguate_word(word, sentence):
sense = lesk(sentence.split(), word)
return sense.definition() if sense else None
# Test the function
sentence = "I went to the bank to deposit money."
word = "bank"
print(f"Sense of '{word}': {disambiguate_word(word, sentence)}")
Language Detection Using Polyglot
Application: Detect the language of a given text.
from polyglot.detect import Detector
def detect_language_polyglot(text):
detector = Detector(text)
return detector.language.name
# Test the function
text = "Hola, ¿cómo estás?"
print(f"Language: {detect_language_polyglot(text)}")
POS Tagging Using Stanza
Application: Perform Part-of-Speech tagging with a pre-trained NLP model.
import stanza
# Download and initialize the Stanza pipeline
stanza.download("en")
nlp = stanza.Pipeline("en")
def pos_tagging(text):
doc = nlp(text)
return [(word.text, word.upos) for sentence in doc.sentences for word in sentence.words]
# Test the function
text = "The quick brown fox jumps over the lazy dog."
print(f"POS Tags: {pos_tagging(text)}")

Top comments (0)