In YOLO (You Only Look Once), additional convolutional layers are often added to the model to increase its performance in terms of object detection accuracy and the ability to capture more complex patterns in the input images. YOLO is known for its speed and efficiency, and the network architecture plays a crucial role in achieving a balance between speed and accuracy.
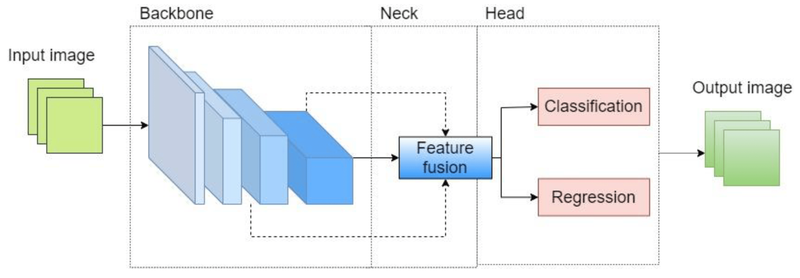
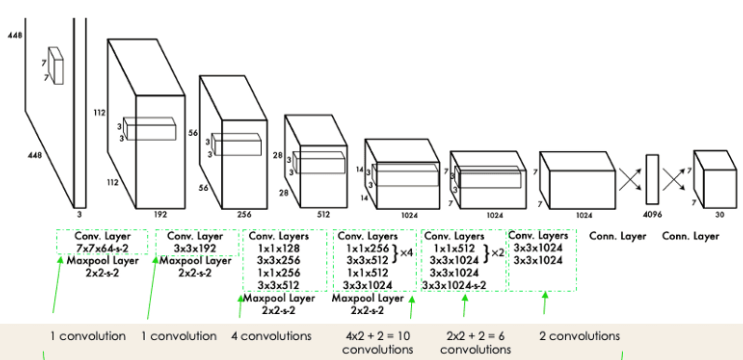
Here are a few reasons why additional convolutional layers might be used to improve YOLO's performance:
Hierarchical Feature Learning:
Additional convolutional layers allow the model to learn hierarchical features from the input images. As you go deeper into the network, the features become more abstract and representative of higher-level patterns in the data. This hierarchical feature learning helps in capturing complex structures and relationships within objects.
Increased Receptive Field:
Adding more convolutional layers increases the receptive field of the network. The receptive field refers to the area of the input image that influences the activation of a particular unit in the network. A larger receptive field enables the model to consider more contextual information, which is beneficial for accurately localizing objects and understanding their spatial relationships.
Better Object Localization:
Object detection involves not only classifying objects but also accurately localizing their bounding boxes. Additional convolutional layers help in refining the spatial information, leading to better object localization. This is crucial for accurate detection, especially in cases where objects are small or closely packed.
Improved Feature Representation:
Deeper networks with additional layers can learn more discriminative feature representations. This is important for distinguishing between different object classes and handling variations in object appearance, pose, and lighting conditions.
Capacity to Learn Complex Patterns:
Object detection tasks often involve recognizing objects in various poses, scales, and orientations. More convolutional layers provide the model with the capacity to learn complex patterns and variations, making it more robust to different scenarios.
Performance on Diverse Datasets:
Adding more layers can improve the model's performance on diverse datasets with a wide range of object classes and variations. This is important for the generalization capability of the model across different scenes and object categories.
It's worth noting that while deeper networks may lead to improved performance, they also come with increased computational requirements. Therefore, the design of a YOLO-based architecture involves a trade-off between model complexity, inference speed, and accuracy, depending on the specific requirements of the application. Different versions of YOLO, such as YOLOv3 and YOLOv4, have introduced architectural improvements to strike this balance effectively.

Top comments (0)