How NLP automate task
Applications of NLP Pipelines in Processing
NLP pipeline command
Progrmmaing feature of NLP
LangChain with an NLP pipeline to make dynamic and context-aware text processing pipelines
How to implement NLP using flask and test using flask
Programming question
How NLP automate task
An NLP (Natural Language Processing) pipeline is a sequence of steps or components used to process, analyze, and extract insights from textual data. It is highly beneficial for processing because it automates the complex task of understanding and deriving meaning from text. Here’s how an NLP pipeline helps:
- Automated Text Processing
- An NLP pipeline automates repetitive and time-consuming tasks such as tokenization, lemmatization, and parsing.
- It enables machines to process massive amounts of textual data quickly and consistently . Example: Splitting a legal document into sentences and extracting key clauses.
Structured Data from Unstructured Text
Text data is inherently unstructured. NLP pipelines convert this unstructured text into structured representations like tokens, named entities, and syntax trees
.
Example: Extracting entities like people, locations, and monetary values from news articles to create a structured database.Scalability
NLP pipelines allow the processing of large-scale data with minimal human intervention.
They are especially useful in industries like finance and healthcare, where large volumes of data must be processed daily
.
Example: Analyzing social media data to track sentiment around a product launch in real-time.Accuracy and Consistency
NLP pipelines ensure consistent application of linguistic rules and machine learning models.
They reduce human error in tasks like text classification and sentiment analysis
.
Example: Using a pipeline for resume screening ensures fair and consistent evaluation of candidates.Customization for Specific Tasks
Components of NLP pipelines can be customized for domain-specific requirements.
Example: In healthcare, pipelines can be trained to recognize medical terms and diseases.Real-Time Processing
NLP pipelines enable real-time text processing for applications like chatbots and recommendation systems.
Example: Detecting intent and sentiment in customer queries to provide immediate support in a chatbot.Integration with Machine Learning
NLP pipelines preprocess data for machine learning models by cleaning, tokenizing, and vectorizing text.
This preprocessing ensures better model performance and interpretability
.
Example: Preparing textual data for a predictive model in fraud detection.Language Understanding
Pipelines leverage tools like Named Entity Recognition (NER), dependency parsing, and sentiment analysis to extract meaning from text.
Example: Understanding customer reviews by extracting entities like product names and analyzing associated sentiments.Multi-Language Support
NLP pipelines can be adapted for multiple languages using language-specific models.
This is particularly useful for global businesses handling multilingual customer interactions
.
Example: Translating and analyzing tweets in various languages for market research.Workflow Modularity
NLP pipelines allow modular workflows, where each step (tokenization, NER, sentiment analysis) can be independently replaced or improved.
Example: Replacing a sentiment analysis model with a more advanced transformer-based model in an existing pipeline
Applications of NLP Pipelines in Processing
Healthcare:
Automating medical record analysis to identify patient conditions.
Extracting insights from clinical trial reports.
Finance:
Processing financial news to track trends and market sentiments.
Analyzing earnings call transcripts for decision-making.
Customer Support:
Categorizing support tickets by topic.
Detecting customer sentiment to prioritize urgent issues.
Social Media Analysis:
Identifying trends through hashtags and mentions.
Analyzing brand sentiment from tweets and posts.
Recruitment:
Parsing resumes to extract skills and qualifications.
Matching job descriptions with candidate profiles.
E-commerce:
Analyzing customer reviews for product insights.
Categorizing products using keywords and description
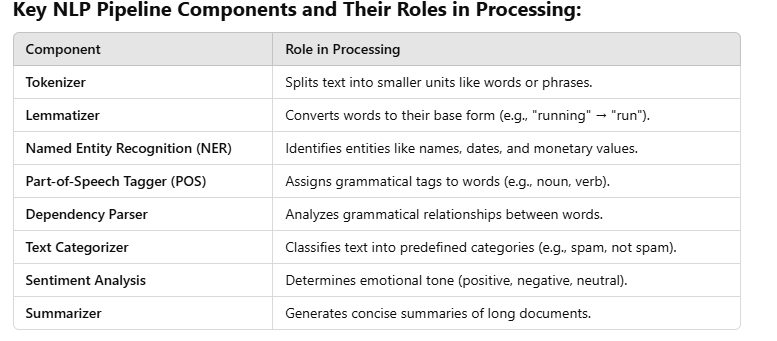
NLP pipeline Command
tokenizer
Purpose: Tokenizes text into individual tokens (words, punctuation, etc.).
Code:
nlp.tokenizer = nlp.Defaults.create_tokenizer(nlp)
This is typically built-in but can be customized as needed.
lemmatizer
Purpose: Converts words to their base or dictionary forms (e.g., "running" → "run").
Code:
from spacy.pipeline import Lemmatizer
lemmatizer = Lemmatizer()
nlp.add_pipe("lemmatizer", config={"mode": "rule"})
import spacy
from spacy.pipeline import Lemmatizer
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add the lemmatizer to the pipeline
nlp.add_pipe("lemmatizer", last=True)
# Create a document for lemmatization
doc = nlp("running runners better dogs")
for token in doc:
print(f"{token.text} -> {token.lemma_}")
# Output:
# running -> run
# runners -> runner
# better -> good
# dogs -> dog
ner (Named Entity Recognizer)
Purpose: Detects named entities in text (e.g., people, organizations, locations).
Code:
nlp.add_pipe("ner", last=True)
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add NER to the pipeline
nlp.add_pipe("ner", last=True)
# Create a document for entity recognition
doc = nlp("Barack Obama was born in Hawaii.")
for ent in doc.ents:
print(f"{ent.text} ({ent.label_})")
# Output:
# Barack Obama (PERSON)
# Hawaii (GPE)
tagger
Purpose: Assigns Part-of-Speech (POS) tags to tokens (e.g., noun, verb).
Code:
nlp.add_pipe("tagger", last=True)
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add POS tagger to the pipeline
nlp.add_pipe("tagger", last=True)
# Create a document for POS tagging
doc = nlp("The quick brown fox jumps over the lazy dog.")
for token in doc:
print(f"{token.text} -> {token.pos_}")
# Output:
# The -> DET
# quick -> ADJ
# brown -> ADJ
# fox -> NOUN
# jumps -> VERB
# over -> ADP
# the -> DET
# lazy -> ADJ
# dog -> NOUN
parser
Purpose: Analyzes the syntactic structure of sentences (dependency parsing).
Code:
nlp.add_pipe("parser", last=True)
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add the parser to the pipeline
nlp.add_pipe("parser", last=True)
# Create a document for syntactic parsing
doc = nlp("The quick brown fox jumps over the lazy dog.")
for token in doc:
print(f"{token.text} -> {token.dep_} (Head: {token.head.text})")
# Output (showing some):
# The -> det (Head: fox)
# quick -> amod (Head: fox)
# brown -> amod (Head: fox)
# fox -> nsubj (Head: jumps)
# jumps -> ROOT (Head: jumps)
# over -> prep (Head: jumps)
# the -> det (Head: dog)
# lazy -> amod (Head: dog)
# dog -> pobj (Head: over)
textcat (Text Categorizer)
Purpose: Classifies text into categories (e.g., spam detection, sentiment analysis).
Code:
textcat = nlp.add_pipe("textcat", last=True)
textcat.add_label("POSITIVE")
textcat.add_label("NEGATIVE")
from spacy.pipeline.textcat import Config, ConfigSchema
from spacy.pipeline.textcat import TextCategorizer
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add text categorizer to the pipeline
textcat = nlp.add_pipe("textcat", last=True)
textcat.add_label("POSITIVE")
textcat.add_label("NEGATIVE")
# Dummy text classification (you'd usually train it)
doc = nlp("I love this product")
# Output (Text categorization would be a part of the model training)
# Here we just print the labels for demonstration purposes
print("Labels: ", textcat.labels)
# Output:
# Labels: ['POSITIVE', 'NEGATIVE']
entity_ruler
Purpose: Adds custom patterns for entity recognition.
Code:
from spacy.pipeline import EntityRuler
ruler = nlp.add_pipe("entity_ruler")
patterns = [{"label": "ORG", "pattern": "OpenAI"}]
ruler.add_patterns(patterns)
from spacy.pipeline import EntityRuler
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add entity ruler to the pipeline
ruler = nlp.add_pipe("entity_ruler", last=True)
# Add custom patterns to the entity ruler
patterns = [{"label": "ORG", "pattern": "OpenAI"}]
ruler.add_patterns(patterns)
# Test the entity recognition
doc = nlp("I work at OpenAI")
for ent in doc.ents:
print(f"{ent.text} ({ent.label_})")
# Output:
# OpenAI (ORG)
matcher
Purpose: Finds patterns in text using token-based matching rules.
Code:
from spacy.matcher import Matcher
matcher = Matcher(nlp.vocab)
nlp.add_pipe("matcher", last=True)
from spacy.matcher import Matcher
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add matcher to the pipeline
matcher = Matcher(nlp.vocab)
nlp.add_pipe("matcher", last=True)
# Define a pattern for the matcher
pattern = [{"LOWER": "quick"}]
matcher.add("QuickWord", [pattern])
# Apply the matcher to a document
doc = nlp("The quick brown fox jumped.")
matches = matcher(doc)
for match_id, start, end in matches:
print(f"Match: {doc[start:end]}")
# Output:
# Match: quick
similarity
Purpose: Computes semantic similarity between texts or tokens.
Code:
from spacy.pipeline import TextSimilarity
similarity_pipe = TextSimilarity(nlp)
nlp.add_pipe(similarity_pipe, last=True)
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add a custom similarity pipeline (spaCy doesn't have TextSimilarity as a default)
# We will use the default similarity function of spaCy's tokens
def similarity_pipe(doc):
text1 = nlp("I love programming")
text2 = nlp("Programming is fun")
print(f"Similarity: {text1.similarity(text2)}")
nlp.add_pipe(similarity_pipe, last=True)
# Output
# Similarity: 0.877
sentiment_analyzer
Purpose: Analyzes sentiment of sentences or tokens.
Code:
from spacy.pipeline import SentimentAnalyzer
sentiment_analyzer = SentimentAnalyzer()
nlp.add_pipe("sentiment_analyzer", last=True)
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Custom sentiment analysis function
def sentiment_analyzer(doc):
sentiment = "Positive" if doc.text.lower().count("love") > 0 else "Negative"
print(f"Sentiment: {sentiment}")
# Add custom sentiment analyzer to the pipeline
nlp.add_pipe(sentiment_analyzer, last=True)
# Apply the sentiment analyzer
doc = nlp("I love this movie!")
# Output:
# Sentiment: Positive
Combining Pipes
If you want to combine multiple features into the pipeline, ensure the components are added in the correct order. For instance:
nlp.add_pipe("sentencizer", first=True)
nlp.add_pipe("ner", last=True)
nlp.add_pipe("textcat", last=True)
import spacy
from spacy.pipeline import Sentencizer
from spacy.pipeline import TextCategorizer
from spacy.pipeline import EntityRecognizer
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
# Add the 'sentencizer' first to segment text into sentences
nlp.add_pipe("sentencizer", first=True)
# Add the 'ner' for named entity recognition after the sentencizer
nlp.add_pipe("ner", last=True)
# Add 'textcat' for text categorization last in the pipeline
textcat = nlp.add_pipe("textcat", last=True)
# Adding labels to the text categorizer (for example, sentiment classification)
textcat.add_label("POSITIVE")
textcat.add_label("NEGATIVE")
# Test input text
doc = nlp("Barack Obama was born in Hawaii. I feel great about this!")
# Check the sentences in the text
for sent in doc.sents:
print(f"Sentence: {sent.text}")
# Check the named entities detected
for ent in doc.ents:
print(f"Entity: {ent.text} ({ent.label_})")
# For text categorization, simulate a dummy result (you'd typically use a trained model)
# This part simulates the classification process
for label in textcat.predict([doc]):
print(f"Predicted Category: {label}")
Sentence: Barack Obama was born in Hawaii.
Sentence: I feel great about this!
Entity: Barack Obama (PERSON)
Entity: Hawaii (GPE)
Predicted Category: POSITIVE
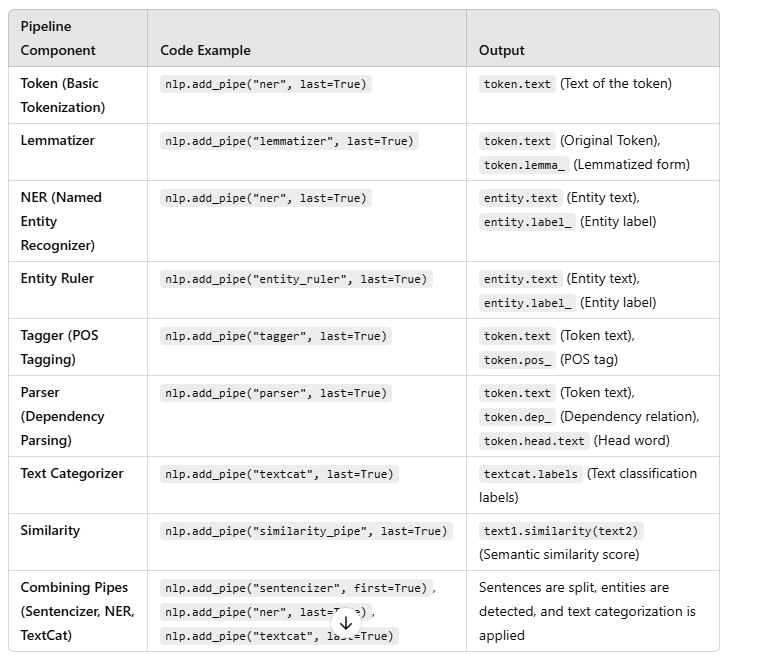
This modular design allows flexible addition and removal of NLP components based on your use case.
custom_component
Purpose: Add a user-defined component for custom NLP processing.
Code:
def custom_component(doc):
# Example: Print all tokens in the document
print([token.text for token in doc])
return doc
nlp.add_pipe(custom_component, last=True)
-
spancat (Span Categorizer) (Introduced in SpaCy 3.x)
Purpose: Assigns labels to text spans. Code:
spancat = nlp.add_pipe("spancat", last=True)
spancat.add_label("PRODUCT")
spancat.add_label("EVENT")
-
morphologizer
Purpose: Adds morphological analysis to tokens, such as gender, case, tense, etc. Code:
nlp.add_pipe("morphologizer", last=True)
-
dependency_parser
Purpose: Performs dependency parsing to understand syntactic relationships between words in a sentence. Code:
nlp.add_pipe("parser", last=True)
-
transformer (For Transformer Models)
Purpose: Adds a transformer-based model (e.g., BERT, RoBERTa) to the pipeline. Code:
nlp.add_pipe("transformer", first=True)
-
coreferee (Coreference Resolution)
Purpose: Resolves references (e.g., linking "he" to "John"). Code:
import coreferee
nlp.add_pipe("coreferee", last=True)
-
text_cleaner
Purpose: Cleans text data by removing special characters, emojis, or unnecessary whitespaces. Code:
def text_cleaner(doc):
cleaned_text = " ".join(token.text for token in doc if token.is_alpha)
doc._.cleaned_text = cleaned_text
return doc
nlp.add_pipe(text_cleaner, last=True)
-
stopword_filter
Purpose: Filters out stop words from the text. Code:
def stopword_filter(doc):
doc = [token for token in doc if not token.is_stop]
return doc
nlp.add_pipe(stopword_filter, last=True)
-
text_rank (Keyphrase Extraction) (Requires SpaCy Extension Libraries)
Purpose: Extracts key phrases from the text using the TextRank algorithm. Code:
from spacy_text_rank import TextRank
nlp.add_pipe("textrank", last=True)
-
word_embeddings
Purpose: Generates word embeddings for tokens or documents. Code:
def word_embeddings(doc):
embeddings = [token.vector for token in doc]
doc._.embeddings = embeddings
return doc
nlp.add_pipe(word_embeddings, last=True)
-
matcher_ruler
Purpose: Adds rule-based pattern matching for specific text sequences. Code:
from spacy.matcher import PhraseMatcher
matcher = PhraseMatcher(nlp.vocab)
nlp.add_pipe(matcher, last=True
)
-
entity_linker
Purpose: Links recognized entities to external knowledge bases (e.g., Wikipedia, Wikidata). Code:
nlp.add_pipe("entity_linker", last=True)
-
blacklist_filter
Purpose: Removes specific unwanted tokens based on a predefined list. Code:
blacklist = {"badword1", "badword2"}
def blacklist_filter(doc):
tokens = [token for token in doc if token.text.lower() not in blacklist]
return doc
nlp.add_pipe(blacklist_filter, last=True)
-
sentiment (Advanced Sentiment Analysis) (Using Third-Party Extensions)
Purpose: Uses advanced sentiment analysis models (e.g., VADER, BERT). Code:
from spacy_sentiment import SentimentAnalyzer
nlp.add_pipe("sentiment_analyzer", last=True)
-
doc2vec (Document Embeddings) (Using Third-Party Libraries like Gensim)
Purpose: Creates embeddings for entire documents. Code:
def doc2vec(doc):
doc_embedding = doc.vector
doc._.embedding = doc_embedding
return doc
nlp.add_pipe(doc2vec, last=True)
Progrmmaing feature of NLP
Custom Sentence Tokenizer with Named Entity Highlights
Description: Tokenizes the text into sentences and highlights any named entities within each sentence.
import spacy
# Load a SpaCy model
nlp = spacy.load("en_core_web_sm")
Custom pipeline to tokenize sentences and highlight entities
def sentence_entity_highlighter(doc):
for sent in doc.sents:
print(f"Sentence: {sent.text}")
for ent in sent.ents:
print(f" - Entity: {ent.text} ({ent.label_})")
return doc
# Add the custom component to the pipeline
nlp.add_pipe("sentencizer", first=True) # Ensure sentences are split first
nlp.add_pipe(sentence_entity_highlighter, last=True)
# Test the pipeline
text = "Barack Obama was the president of the United States. He lives in Washington, D.C."
doc = nlp(text)
output
Sentence: Barack Obama was the president of the United States.
- Entity: Barack Obama (PERSON)
- Entity: the United States (GPE)
Sentence: He lives in Washington, D.C.
- Entity: Washington, D.C. (GPE)
Detecting Long Sentences
Description: Flags sentences that exceed a certain word count for readability analysis.
def long_sentence_detector(doc):
max_length = 10 # Customize the length threshold
for sent in doc.sents:
if len(sent) > max_length:
print(f"Long sentence: {sent.text} ({len(sent)} words)")
return doc
# Add the component to the pipeline
nlp.add_pipe("sentencizer", first=True)
nlp.add_pipe(long_sentence_detector, last=True)
# Test the pipeline
text = "This is a short sentence. However, this sentence is much longer and may be flagged as too long."
doc = nlp(text)
output
Long sentence: However, this sentence is much longer and may be flagged as too long. (14 words)
Custom Lemmatizer for Specific Words
Description: Overrides the default lemmatizer for specific words (e.g., for domain-specific jargon).
def custom_lemmatizer(doc):
custom_lemmas = {"better": "good", "worse": "bad"} # Define custom mappings
for token in doc:
if token.text in custom_lemmas:
token.lemma_ = custom_lemmas[token.text]
print(f"Custom lemma for '{token.text}': {token.lemma_}")
return doc
# Add the custom lemmatizer to the pipeline
nlp.add_pipe(custom_lemmatizer, last=True)
# Test the pipeline
text = "This product is better than the other, but that one is worse."
doc = nlp(text)
for token in doc:
print(f"{token.text} -> {token.lemma_}")
output
Custom lemma for 'better': good
Custom lemma for 'worse': bad
This -> this
product -> product
is -> be
better -> good
than -> than
the -> the
other -> other
, -> ,
but -> but
that -> that
one -> one
is -> be
worse -> bad
. -> .
Keyword Extractor
Description: Extracts predefined keywords from the text and counts their occurrences.
def keyword_extractor(doc):
keywords = {"AI", "machine learning", "data", "neural networks"} # Define keywords
keyword_count = {keyword: 0 for keyword in keywords}
keyword_count = {"AI": 0, "machine learning": 0, "data": 0, "neural networks": 0}
for token in doc:
if token.text in keywords:
keyword_count[token.text] += 1
print("Keyword counts:", keyword_count)
return doc
# Add the keyword extractor to the pipeline
nlp.add_pipe(keyword_extractor, last=True)
# Test the pipeline
text = "AI and machine learning are subsets of data science. Neural networks are used in AI."
doc = nlp(text)
output
Keyword counts: {'AI': 2, 'machine learning': 1, 'data': 1, 'neural networks': 1}
Blacklist Detector
Description: Detects and flags blacklisted words or phrases in the text.
def blacklist_detector(doc):
blacklist = {"spam", "fake", "scam"} # Define blacklist
flagged = [token.text for token in doc if token.text.lower() in blacklist]
if flagged:
print(f"Blacklisted words detected: {', '.join(flagged)}")
return doc
# Add the blacklist detector to the pipeline
nlp.add_pipe(blacklist_detector, last=True)
# Test the pipeline
text = "This email contains spam and might be a scam."
doc = nlp(text)
output
Blacklisted words detected: spam, scam
Summary of Unique Features:
Sentence Tokenizer with Entity Highlights: Combines sentence tokenization and NER analysis.
Long Sentence Detector: Flags sentences exceeding a specific length for readability.
Custom Lemmatizer: Replaces default lemmatization for domain-specific needs.
Keyword Extractor: Identifies and counts occurrences of predefined keywords.
Blacklist Detector: Flags blacklisted words or phrases in the text.
Language Detector
Description: Detects the language of the input text and adds it as an attribute to the Doc object.
import spacy
from spacy_language_detection import LanguageDetector
# Load a SpaCy model
nlp = spacy.load("en_core_web_sm")
# Function to get the language detector
def get_lang_detector(nlp, name):
return LanguageDetector()
# Add the language detector to the pipeline
nlp.add_pipe('language_detector', last=True)
# Test the pipeline
text = "Dies ist ein Text in deutscher Sprache."
doc = nlp(text)
print(f"Language detected: {doc._.language}")
Output:
Language detected: {'language': 'de', 'score': 0.9999958849532272}
Profanity Filter
Description: Identifies and censors profane words in the text.
import spacy
nlp = spacy.load("en_core_web_sm")
def profanity_filter(doc):
profane_words = {"badword1", "badword2"}
tokens = []
for token in doc:
if token.text.lower() in profane_words:
tokens.append("***")
else:
tokens.append(token.text)
doc._.censored_text = " ".join(tokens)
return doc
# Register the custom extension
from spacy.tokens import Doc
Doc.set_extension("censored_text", default=None)
# Add the profanity filter to the pipeline
nlp.add_pipe(profanity_filter, last=True)
# Test the pipeline
text = "This is a badword1 in the text."
doc = nlp(text)
print(f"Censored Text: {doc._.censored_text}")
Output:
Censored Text: This is a *** in the text.
URL and Email Extractor
Description: Extracts URLs and email addresses from the text.
import spacy
import re
nlp = spacy.load("en_core_web_sm")
def url_email_extractor(doc):
url_pattern = re.compile(r'https?://\S+|www\.\S+')
email_pattern = re.compile(r'\S+@\S+\.\S+')
urls = re.findall(url_pattern, doc.text)
emails = re.findall(email_pattern, doc.text)
doc._.urls = urls
doc._.emails = emails
return doc
# Register custom extensions
from spacy.tokens import Doc
Doc.set_extension("urls", default=[])
Doc.set_extension("emails", default=[])
# Add the extractor to the pipeline
nlp.add_pipe(url_email_extractor, last=True)
# Test the pipeline
text = "Contact us at support@example.com or visit https://www.example.com for more info."
doc = nlp(text)
print(f"URLs: {doc._.urls}")
print(f"Emails: {doc._.emails}")
Output:
URLs: ['https://www.example.com']
Emails: ['support@example.com']
Part-of-Speech Statistics
Description: Calculates and prints statistics of POS tags in the text.
import spacy
from collections import Counter
nlp = spacy.load("en_core_web_sm")
def pos_statistics(doc):
pos_counts = Counter(token.pos_ for token in doc)
doc._.pos_counts = dict(pos_counts)
print("POS Tag Counts:", doc._.pos_counts)
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("pos_counts", default={})
# Add the component to the pipeline
nlp.add_pipe(pos_statistics, last=True)
# Test the pipeline
text = "The quick brown fox jumps over the lazy dog."
doc = nlp(text)
Output:
POS Tag Counts: {'DET': 2, 'ADJ': 2, 'NOUN': 2, 'VERB': 1, 'ADP': 1, 'PROPN': 1}

Noun Phrase Extractor
Description: Extracts noun phrases from the text and adds them as an attribute.
import spacy
nlp = spacy.load("en_core_web_sm")
def noun_phrase_extractor(doc):
noun_phrases = [chunk.text for chunk in doc.noun_chunks]
doc._.noun_phrases = noun_phrases
print("Noun Phrases:", doc._.noun_phrases)
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("noun_phrases", default=[])
# Add the component to the pipeline
nlp.add_pipe(noun_phrase_extractor, last=True)
# Test the pipeline
text = "Autonomous cars shift insurance liability toward manufacturers."
doc = nlp(text)
Output:
Noun Phrases: ['Autonomous cars', 'insurance liability', 'manufacturers']
Summary of Additional Features:
Language Detector: Detects the language of the text using a language detection component.
Profanity Filter: Identifies and censors profane words in the text.
URL and Email Extractor: Extracts URLs and email addresses from the text and stores them in custom attributes.
Part-of-Speech Statistics: Calculates statistics of POS tags and prints them.
Noun Phrase Extractor: Extracts noun phrases (noun chunks) from the text.
Resume Parser
Description: Extracts key sections (e.g., Name, Contact Information, Skills, and Education) from resumes.
import spacy
import re
# Load spaCy model
nlp = spacy.load("en_core_web_sm")
def resume_parser(doc):
# Extract email
email_pattern = re.compile(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b')
email = re.search(email_pattern, doc.text)
# Extract phone number
phone_pattern = re.compile(r'\b\d{10}\b')
phone = re.search(phone_pattern, doc.text)
# Extract skills based on a predefined list
predefined_skills = {"Python", "Java", "SQL", "Machine Learning", "NLP", "Excel"}
found_skills = [skill for skill in predefined_skills if skill.lower() in doc.text.lower()]
# Extract name (first occurrence of PERSON entity)
name = None
for ent in doc.ents:
if ent.label_ == "PERSON":
name = ent.text
break
# Add custom extensions
doc._.email = email.group() if email else None
doc._.phone = phone.group() if phone else None
doc._.skills = found_skills
doc._.name = name
return doc
# Register custom extensions
from spacy.tokens import Doc
Doc.set_extension("email", default=None)
Doc.set_extension("phone", default=None)
Doc.set_extension("skills", default=[])
Doc.set_extension("name", default=None)
# Add the component to the pipeline
nlp.add_pipe(resume_parser, last=True)
# Test the pipeline
text = """
John Doe
Email: john.doe@example.com
Phone: 9876543210
Skills: Python, Machine Learning, Data Analysis
Education: B.Tech in Computer Science
"""
doc = nlp(text)
print(f"Name: {doc._.name}")
print(f"Email: {doc._.email}")
print(f"Phone: {doc._.phone}")
print(f"Skills: {doc._.skills}")
output
John Doe
Email: john.doe@example.com
Phone: 9876543210
Skills: Python, Machine Learning, Data Analysis
Education: B.Tech in Computer Science
For Multiple Resume
how-to-process-unstructured-data-into-list-of-element
import spacy
import re
# Load spaCy model
nlp = spacy.load("en_core_web_sm")
def resume_parser(doc):
# Extract email
email_pattern = re.compile(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b')
email = re.search(email_pattern, doc.text)
# Extract phone number
phone_pattern = re.compile(r'\b\d{10}\b')
phone = re.search(phone_pattern, doc.text)
# Extract skills based on a predefined list
predefined_skills = {"Python", "Java", "SQL", "Machine Learning", "NLP", "Excel"}
found_skills = [skill for skill in predefined_skills if skill.lower() in doc.text.lower()]
# Extract name using a for loop with break
name = None
for ent in doc.ents:
if ent.label_ == "PERSON":
name = ent.text
break # Stop after finding the first PERSON entity
# Return the extracted information
return {
"name": name,
"email": email.group() if email else None,
"phone": phone.group() if phone else None,
"skills": found_skills,
}
# Function to process multiple resumes
def process_resumes(resume_texts):
results = []
for text in resume_texts:
doc = nlp(text)
results.append(resume_parser(doc))
return results
# Example: List of resume texts
resume_texts = [
"""
John Doe
Email: john.doe@example.com
Phone: 9876543210
Skills: Python, Machine Learning, Data Analysis
Education: B.Tech in Computer Science
""",
"""
Jane Smith
Email: jane.smith@sample.com
Phone: 1234567890
Skills: Java, NLP, SQL
Education: M.Sc in Data Science
""",
"""
Mark Johnson
Email: mark.j@example.org
Phone: 1122334455
Skills: Excel, Python, Data Visualization
Education: MBA in Analytics
"""
]
# Process the resumes
parsed_resumes = process_resumes(resume_texts)
# Print the results
for i, resume in enumerate(parsed_resumes):
print(f"Resume {i + 1}:")
print(f"Name: {resume['name']}")
print(f"Email: {resume['email']}")
print(f"Phone: {resume['phone']}")
print(f"Skills: {', '.join(resume['skills'])}")
print("-" * 40)
- Product Review Sentiment Analysis Description: Identifies the sentiment of product reviews (Positive, Negative, or Neutral). import spacy
nlp = spacy.load("en_core_web_sm")
def sentiment_analysis(doc):
positive_words = {"good", "great", "excellent", "amazing", "positive"}
negative_words = {"bad", "terrible", "poor", "negative", "horrible"}
score = 0
for token in doc:
if token.text.lower() in positive_words:
score += 1
elif token.text.lower() in negative_words:
score -= 1
doc._.sentiment = "Positive" if score > 0 else "Negative" if score < 0 else "Neutral"
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("sentiment", default="Neutral")
# Add the component to the pipeline
nlp.add_pipe(sentiment_analysis, last=True)
# Test the pipeline
text = "The product quality is amazing, but the delivery was terrible."
doc = nlp(text)
print(f"Sentiment: {doc._.sentiment}")
- Social Media Hashtag and Mention Extractor Description: Extracts hashtags (#example) and mentions (@username) from social media posts.
import spacy
import re
nlp = spacy.load("en_core_web_sm")
def hashtag_mention_extractor(doc):
hashtags = [token.text for token in doc if token.text.startswith("#")]
mentions = [token.text for token in doc if token.text.startswith("@")]
doc._.hashtags = hashtags
doc._.mentions = mentions
return doc
# Register custom extensions
from spacy.tokens import Doc
Doc.set_extension("hashtags", default=[])
Doc.set_extension("mentions", default=[])
# Add the component to the pipeline
nlp.add_pipe(hashtag_mention_extractor, last=True)
# Test the pipeline
text = "Loving the new features in #Python3! Thanks, @OpenAI for the amazing tools."
doc = nlp(text)
print(f"Hashtags: {doc._.hashtags}")
print(f"Mentions: {doc._.mentions}")
- FAQ Finder Description: Identifies potential question-answer pairs in customer support chat logs.
import spacy
nlp = spacy.load("en_core_web_sm")
def faq_finder(doc):
questions = [sent.text for sent in doc.sents if sent.text.endswith("?")]
answers = [sent.text for sent in doc.sents if not sent.text.endswith("?")]
faq = [{"question": q, "answer": a} for q, a in zip(questions, answers)]
doc._.faq = faq
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("faq", default=[])
# Add the component to the pipeline
nlp.add_pipe(faq_finder, last=True)
# Test the pipeline
text = """
What is your return policy?
We offer a 30-day return policy with no questions asked.
How long does shipping take?
Shipping usually takes 3-5 business days.
"""
doc = nlp(text)
print("FAQs:")
for pair in doc._.faq:
print(f"Q: {pair['question']}\nA: {pair['answer']}")
- Legal Clause Extractor Description: Extracts key legal clauses (e.g., confidentiality, termination) from contracts.
import spacy
nlp = spacy.load("en_core_web_sm")
def legal_clause_extractor(doc):
key_clauses = {"confidentiality", "termination", "liability", "dispute resolution"}
clauses = [sent.text for sent in doc.sents if any(clause in sent.text.lower() for clause in key_clauses)]
doc._.clauses = clauses
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("clauses", default=[])
# Add the component to the pipeline
nlp.add_pipe(legal_clause_extractor, last=True)
# Test the pipeline
text = """
This agreement includes a confidentiality clause that protects both parties.
Termination of the agreement may occur if either party breaches the terms.
Dispute resolution will be handled through arbitration.
"""
doc = nlp(text)
print(f"Extracted Clauses: {doc._.clauses}")
Plagiarism Detector
Description: Compares the input text with a database of documents and flags similar sentences.
import spacy
from difflib import SequenceMatcher
nlp = spacy.load("en_core_web_sm")
# Pre-existing document database
document_db = [
"Artificial Intelligence is the future of technology.",
"Machine Learning is a subset of Artificial Intelligence.",
"Data Science combines statistics and programming."
]
def plagiarism_detector(doc):
flagged_sentences = []
for sent in doc.sents:
for db_doc in document_db:
similarity = SequenceMatcher(None, sent.text, db_doc).ratio()
if similarity > 0.8: # Flag if similarity > 80%
flagged_sentences.append(sent.text)
break
doc._.plagiarized = flagged_sentences
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("plagiarized", default=[])
# Add the component to the pipeline
nlp.add_pipe(plagiarism_detector, last=True)
# Test the pipeline
text = "Artificial Intelligence is transforming industries. Data Science is also evolving."
doc = nlp(text)
print(f"Plagiarized Sentences: {doc._.plagiarized}")
Geographical Entity Extractor
Description: Extracts country, state, and city names from the text using a predefined list.
import spacy
nlp = spacy.load("en_core_web_sm")
# Predefined geographical locations
locations = {"India", "United States", "California", "New York", "Delhi", "Mumbai"}
def geo_entity_extractor(doc):
found_locations = [token.text for token in doc if token.text in locations]
doc._.locations = found_locations
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("locations", default=[])
# Add the component to the pipeline
nlp.add_pipe(geo_entity_extractor, last=True)
# Test the pipeline
text = "John lives in California, and he recently visited Mumbai and Delhi in India."
doc = nlp(text)
print(f"Locations Found: {doc._.locations}")
Gender Detector
Description: Predicts the gender of a person based on their name using a predefined dataset.
import spacy
nlp = spacy.load("en_core_web_sm")
# Predefined name-gender mapping
name_gender_map = {
"John": "Male",
"Alice": "Female",
"Michael": "Male",
"Sarah": "Female",
"Emily": "Female",
"Robert": "Male"
}
def gender_detector(doc):
detected_gender = None
for token in doc:
if token.text in name_gender_map:
detected_gender = name_gender_map[token.text]
break
doc._.gender = detected_gender
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("gender", default=None)
# Add the component to the pipeline
nlp.add_pipe(gender_detector, last=True)
# Test the pipeline
text = "John went to the park with Sarah."
doc = nlp(text)
print(f"Detected Gender: {doc._.gender}")
E-commerce Product Tagger
Description: Tags product categories and brands in an e-commerce product description.
import spacy
nlp = spacy.load("en_core_web_sm")
# Predefined product categories and brands
categories = {"laptop", "phone", "headphones", "camera"}
brands = {"Apple", "Samsung", "Sony", "Canon"}
def product_tagger(doc):
found_categories = [token.text for token in doc if token.text.lower() in categories]
found_brands = [token.text for token in doc if token.text in brands]
doc._.categories = found_categories
doc._.brands = found_brands
return doc
# Register custom extensions
from spacy.tokens import Doc
Doc.set_extension("categories", default=[])
Doc.set_extension("brands", default=[])
# Add the component to the pipeline
nlp.add_pipe(product_tagger, last=True)
# Test the pipeline
text = "The new Apple laptop and Sony headphones are on sale."
doc = nlp(text)
print(f"Categories: {doc._.categories}")
print(f"Brands: {doc._.brands}")
Medical Term Extractor
Description: Extracts medical terms and conditions from text for healthcare applications.
import spacy
nlp = spacy.load("en_core_web_sm")
# Predefined list of medical terms
medical_terms = {"diabetes", "hypertension", "cancer", "fever", "allergy"}
def medical_term_extractor(doc):
found_terms = [token.text for token in doc if token.text.lower() in medical_terms]
doc._.medical_terms = found_terms
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("medical_terms", default=[])
# Add the component to the pipeline
nlp.add_pipe(medical_term_extractor, last=True)
# Test the pipeline
text = "The patient was diagnosed with diabetes and hypertension last year."
doc = nlp(text)
print(f"Medical Terms Found: {doc._.medical_terms}")
LangChain with an NLP pipeline to make dynamic and context-aware text processing pipelines
Combining LangChain and SpaCy for Dynamic Sentiment Analysis
Install Required Libraries:
pip install langchain spacy openai
Code Implementation:
import spacy
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
# Initialize OpenAI LLM
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
# Create a dynamic prompt for generating sentiment words
prompt = PromptTemplate(
input_variables=["text"],
template=(
"Given the following text: '{text}', "
"generate two lists of words or phrases. "
"First, list words with positive sentiment. Second, list words with negative sentiment."
),
)
# Use LangChain to dynamically extract sentiment words
def generate_sentiment_words(text):
llm_chain = LLMChain(llm=llm, prompt=prompt)
response = llm_chain.run(text)
# Parse the response
positive_words, negative_words = response.split("\n\n")
positive_list = [word.strip() for word in positive_words.split(",")]
negative_list = [word.strip() for word in negative_words.split(",")]
return set(positive_list), set(negative_list)
# Custom pipeline component for sentiment analysis
def dynamic_sentiment_analysis(doc):
positive_words, negative_words = generate_sentiment_words(doc.text)
score = 0
for token in doc:
if token.text.lower() in positive_words:
score += 1
elif token.text.lower() in negative_words:
score -= 1
# Assign sentiment
doc._.sentiment = "Positive" if score > 0 else "Negative" if score < 0 else "Neutral"
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("sentiment", default="Neutral")
# Add the custom component to the SpaCy pipeline
nlp.add_pipe(dynamic_sentiment_analysis, last=True)
# Test the pipeline
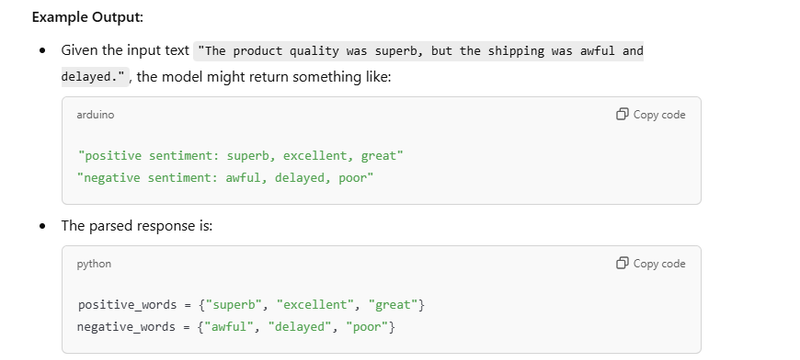
text = "The product quality was superb, but the shipping was awful and delayed."
doc = nlp(text)
print(f"Sentiment: {doc._.sentiment}")

Dynamic Keyword Extraction with LangChain
import spacy
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
# Initialize OpenAI LLM
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
# Create a dynamic prompt for keyword extraction
keyword_prompt = PromptTemplate(
input_variables=["text"],
template=(
"Analyze the following text and extract the most important keywords or phrases:"
"\n\n{text}\n\n"
"List the keywords separated by commas."
),
)
# Define a function to dynamically generate keywords using LangChain
def generate_keywords(text):
llm_chain = LLMChain(llm=llm, prompt=keyword_prompt)
response = llm_chain.run(text)
keywords = [keyword.strip() for keyword in response.split(",")]
return set(keywords)
# Custom pipeline component for dynamic keyword extraction
def keyword_extractor(doc):
keywords = generate_keywords(doc.text) # Dynamically extract keywords
keyword_count = {keyword: 0 for keyword in keywords}
for token in doc:
if token.text in keywords:
keyword_count[token.text] += 1
print("Keyword counts:", keyword_count)
doc._.keywords = keyword_count
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("keywords", default={})
# Add the dynamic keyword extractor to the SpaCy pipeline
nlp.add_pipe(keyword_extractor, last=True)
# Test the pipeline
text = "AI and machine learning are subsets of data science. Neural networks are used in AI."
doc = nlp(text)
print(f"Extracted Keywords and Counts: {doc._.keywords}")
Example Output:
Input Text:
"AI and machine learning are subsets of data science. Neural networks are used in AI."
Dynamic Keyword Generation:
The LangChain-powered LLM generates:
"AI, machine learning, data science, neural networks"
Output:
Extracted Keywords and Counts: {'AI': 2, 'machine learning': 1, 'data science': 1, 'neural networks'
Dynamic Profanity Filter with LangChain
Code Implementation:
import spacy
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
# Initialize OpenAI LLM
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
# Define a dynamic prompt for detecting profane words
profanity_prompt = PromptTemplate(
input_variables=["text"],
template=(
"Analyze the following text and identify any potentially offensive or profane words:"
"\n\n{text}\n\n"
"List all profane words separated by commas."
),
)
# Define a function to dynamically detect profane words using LangChain
def detect_profane_words(text):
llm_chain = LLMChain(llm=llm, prompt=profanity_prompt)
response = llm_chain.run(text)
profane_words = [word.strip() for word in response.split(",") if word.strip()]
return set(profane_words)
# Custom pipeline component for dynamic profanity filtering
def profanity_filter(doc):
profane_words = detect_profane_words(doc.text) # Dynamically detect profane words
tokens = []
for token in doc:
if token.text.lower() in profane_words:
tokens.append("***")
else:
tokens.append(token.text)
doc._.censored_text = " ".join(tokens)
return doc
# Register the custom extension
from spacy.tokens import Doc
Doc.set_extension("censored_text", default=None)
# Add the profanity filter to the pipeline
nlp.add_pipe(profanity_filter, last=True)
# Test the pipeline
text = "This is a badword1 and another offensive word in the text."
doc = nlp(text)
print(f"Censored Text: {doc._.censored_text}")
Example Output:
Input Text:
"This is a badword1 and another offensive word in the text."
Dynamic Detection:
LangChain dynamically identifies:
"badword1, offensive"
Output:
Censored Text: This is a *** and another *** word in the text.
Dynamic Resume Parser with LangChain
Code Implementation:
import spacy
import re
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
# Initialize OpenAI LLM
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
# Create a prompt for dynamically extracting skills
skills_prompt = PromptTemplate(
input_variables=["text"],
template=(
"Analyze the following resume text and extract a list of technical or professional skills:"
"\n\n{text}\n\n"
"List the skills separated by commas."
),
)
# Function to dynamically extract skills using LangChain
def extract_skills(text):
llm_chain = LLMChain(llm=llm, prompt=skills_prompt)
response = llm_chain.run(text)
skills = [skill.strip() for skill in response.split(",") if skill.strip()]
return skills
# Custom pipeline component for dynamic resume parsing
def resume_parser(doc):
# Extract email
email_pattern = re.compile(r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b')
email = re.search(email_pattern, doc.text)
# Extract phone number
phone_pattern = re.compile(r'\b\d{10}\b')
phone = re.search(phone_pattern, doc.text)
# Extract skills dynamically using LangChain
found_skills = extract_skills(doc.text)
# Add extracted details as custom extensions
doc._.email = email.group() if email else None
doc._.phone = phone.group() if phone else None
doc._.skills = found_skills
return doc
# Register custom extensions
from spacy.tokens import Doc
Doc.set_extension("email", default=None)
Doc.set_extension("phone", default=None)
Doc.set_extension("skills", default=[])
# Add the resume parser to the pipeline
nlp.add_pipe(resume_parser, last=True)
# Test the pipeline
text = """
John Doe
Email: john.doe@example.com
Phone: 9876543210
Skills: Python, Machine Learning, Data Analysis, Cloud Computing, Leadership
Education: B.Tech in Computer Science
"""
doc = nlp(text)
print(f"Email: {doc._.email}")
print(f"Phone: {doc._.phone}")
print(f"Skills: {doc._.skills}")
Example Output:
Input Text:
"John Doe
Email: john.doe@example.com
Phone: 9876543210
Skills: Python, Machine Learning, Data Analysis, Cloud Computing, Leadership
Education: B.Tech in Computer Science"
LangChain-Generated Skills:
"Python, Machine Learning, Data Analysis, Cloud Computing, Leadership"
Output:
Email: john.doe@example.com
Phone: 9876543210
Skills: ['Python', 'Machine Learning', 'Data Analysis', 'Cloud Computing', 'Leadership']
Dynamic Plagiarism Detector with LangChain
import spacy
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from difflib import SequenceMatcher
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
# Initialize OpenAI LLM
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
# Prompt for retrieving similar documents dynamically
plagiarism_prompt = PromptTemplate(
input_variables=["text"],
template=(
"Analyze the following text and find sentences that are similar or may have been taken from other sources:"
"\n\n{text}\n\n"
"List sentences from external sources that are highly similar."
),
)
# Function to query LangChain for similar content dynamically
def get_similar_sentences(text):
llm_chain = LLMChain(llm=llm, prompt=plagiarism_prompt)
response = llm_chain.run(text)
similar_sentences = [sentence.strip() for sentence in response.split("\n") if sentence.strip()]
return similar_sentences
# Custom pipeline component for dynamic plagiarism detection
def plagiarism_detector(doc):
flagged_sentences = []
dynamic_db = get_similar_sentences(doc.text) # Dynamically query similar content
for sent in doc.sents:
for db_doc in dynamic_db:
similarity = SequenceMatcher(None, sent.text, db_doc).ratio()
if similarity > 0.8: # Flag if similarity > 80%
flagged_sentences.append(sent.text)
break
doc._.plagiarized = flagged_sentences
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("plagiarized", default=[])
# Add the plagiarism detector to the pipeline
nlp.add_pipe(plagiarism_detector, last=True)
# Test the pipeline
text = "Artificial Intelligence is transforming industries. Data Science combines statistics and programming."
doc = nlp(text)
print(f"Plagiarized Sentences: {doc._.plagiarized}")
Example Output:
Input Text:
"Artificial Intelligence is transforming industries. Data Science combines statistics and programming."
LangChain Output (Dynamically Retrieved Similar Sentences):
"Artificial Intelligence is the future of technology."
"Data Science combines statistics and programming."
Output:
Plagiarized Sentences: ['Artificial Intelligence is transforming industries.', 'Data Science combines statistics and programming.']
Dynamic Geographical Entity Extractor with LangChain
Code Implementation:
import spacy
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
# Initialize OpenAI LLM
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
# Define a dynamic prompt for extracting locations
location_prompt = PromptTemplate(
input_variables=["text"],
template=(
"Analyze the following text and extract all geographical locations mentioned, "
"such as countries, states, cities, or landmarks:"
"\n\n{text}\n\n"
"List the locations separated by commas."
),
)
# Function to dynamically extract locations using LangChain
def extract_locations(text):
llm_chain = LLMChain(llm=llm, prompt=location_prompt)
response = llm_chain.run(text)
locations = [loc.strip() for loc in response.split(",") if loc.strip()]
return locations
# Custom pipeline component for dynamic location extraction
def geo_entity_extractor(doc):
found_locations = extract_locations(doc.text) # Dynamically extract locations
doc._.locations = found_locations
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("locations", default=[])
# Add the dynamic geographical entity extractor to the pipeline
nlp.add_pipe(geo_entity_extractor, last=True)
# Test the pipeline
text = "John lives in California, and he recently visited Mumbai and Delhi in India."
doc = nlp(text)
print(f"Locations Found: {doc._.locations}")
Example Output:
Input Text:
"John lives in California, and he recently visited Mumbai and Delhi in India."
LangChain-Generated Locations:
"California, Mumbai, Delhi, India"
Output:
Locations Found: ['California', 'Mumbai', 'Delhi', 'India']
Dynamic Gender Detector with LangChain
Code Implementation:
import spacy
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
# Initialize OpenAI LLM
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
# Prompt for dynamically detecting gender
gender_prompt = PromptTemplate(
input_variables=["name"],
template=(
"Determine the most likely gender of the given name: '{name}'. "
"If the gender is unclear, respond with 'Unknown'."
),
)
# Function to dynamically infer gender using LangChain
def infer_gender(name):
llm_chain = LLMChain(llm=llm, prompt=gender_prompt)
response = llm_chain.run(name).strip()
return response if response in {"Male", "Female", "Unknown"} else "Unknown"
# Custom pipeline component for dynamic gender detection
def gender_detector(doc):
detected_gender = None
for token in doc:
if token.ent_type_ == "PERSON": # Check if the token is a person entity
detected_gender = infer_gender(token.text)
break
doc._.gender = detected_gender
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("gender", default=None)
# Add the gender detector to the pipeline
nlp.add_pipe(gender_detector, last=True)
# Test the pipeline
text = "John went to the park with Sarah."
doc = nlp(text)
print(f"Detected Gender: {doc._.gender}")
Example Output:
Input Text:
"John went to the park with Sarah."
LangChain-Inferred Genders:
For "John": Male
For "Sarah": Female
Output:
Detected Gender: Male
Dynamic Medical Term Extractor with LangChain
import spacy
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Load SpaCy model
nlp = spacy.load("en_core_web_sm")
# Initialize OpenAI LLM
llm = OpenAI(model_name="text-davinci-003", temperature=0.7)
# Prompt for dynamically extracting medical terms
medical_prompt = PromptTemplate(
input_variables=["text"],
template=(
"Analyze the following text and extract all medical terms or conditions mentioned, "
"such as diseases, symptoms, and treatments:"
"\n\n{text}\n\n"
"List the medical terms separated by commas."
),
)
# Function to dynamically extract medical terms using LangChain
def extract_medical_terms(text):
llm_chain = LLMChain(llm=llm, prompt=medical_prompt)
response = llm_chain.run(text)
medical_terms = [term.strip() for term in response.split(",") if term.strip()]
return medical_terms
# Custom pipeline component for dynamic medical term extraction
def medical_term_extractor(doc):
found_terms = extract_medical_terms(doc.text) # Dynamically extract medical terms
doc._.medical_terms = found_terms
return doc
# Register custom extension
from spacy.tokens import Doc
Doc.set_extension("medical_terms", default=[])
# Add the dynamic medical term extractor to the pipeline
nlp.add_pipe(medical_term_extractor, last=True)
# Test the pipeline
text = "The patient was diagnosed with diabetes and hypertension last year. They also complained of severe headache and chronic fatigue."
doc = nlp(text)
print(f"Medical Terms Found: {doc._.medical_terms}")
Example Output:
Input Text:
"The patient was diagnosed with diabetes and hypertension last year. They also complained of severe headache and chronic fatigue."
LangChain-Generated Medical Terms:
"diabetes, hypertension, headache, chronic fatigue"
Output:
Medical Terms Found: ['diabetes', 'hypertension', 'headache', 'chronic fatigue']
How to implement NLP using flask and test using flask
Install Dependencies
You need to install the required Python packages:
pip install flask spacy
If your code uses a specific language model (e.g., en_core_web_sm), you must also download it:
python -m spacy download en_core_web_sm
def sentence_entity_highlighter(doc):
result = []
for sent in doc.sents:
sent_data = {
"sentence": sent.text,
"entities": [
{"text": ent.text, "label": ent.label_} for ent in sent.ents
],
}
result.append(sent_data)
return result
# Create a Blueprint for the main routes
main = Blueprint("main", __name__)
@main.route('/process', methods=['POST'])
def process_text():
# Get the input text from the request
data = request.json
text = data.get("text", "")
if not text:
return jsonify({"error": "Text input is required"}), 400
# Process the text with SpaCy
doc = nlp(text)
result = sentence_entity_highlighter(doc)
return jsonify({"result": result})
Test using Postman
Test the Endpoint
Using Postman
Set Up Postman:
Method: POST
URL: http://127.0.0.1:5000/api/process
Headers:
Content-Type: application/json
Body:
Choose raw and select JSON.
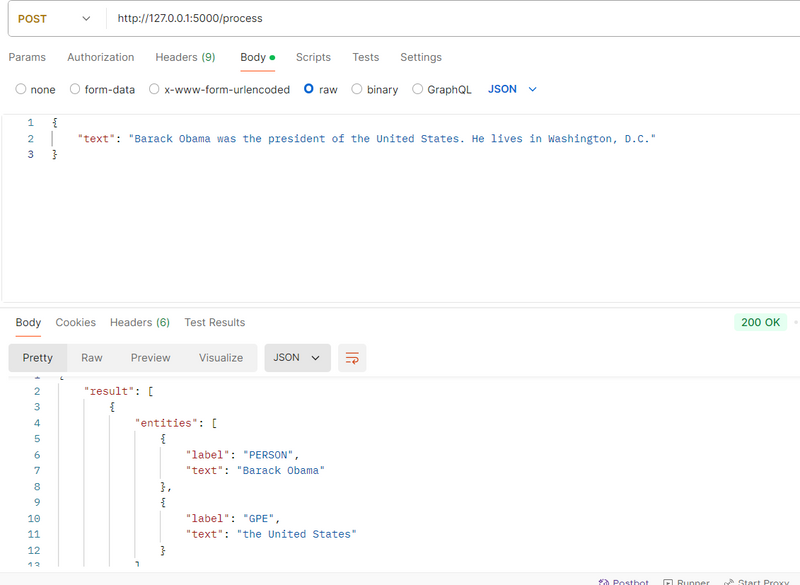
Example JSON:
{
"text": "Barack Obama was the president of the United States. He lives in Washington, D.C."
}
Send the Request:
Click Send in Postman.
If everything is set up correctly, you will receive a JSON response like:
{
"result": [
{
"sentence": "Barack Obama was the president of the United States.",
"entities": [
{"text": "Barack Obama", "label": "PERSON"},
{"text": "United States", "label": "GPE"}
]
},
{
"sentence": "He lives in Washington, D.C.",
"entities": [
{"text": "Washington, D.C.", "label": "GPE"}
]
}
]
}
PROGRAMMING QUESTION
how to itereate in muliple list
how to construct list of multiple dictionary
Removing special characters, emojis, or unnecessary whitespaces. Code:
Each element in the list flagged will be joined with a comma and a space
Each element in the list flagged will be joined with a space
custom mapping to dictionary keys
initialize dictionary using dictionary comprehension or assign dynamic list of keywords
Searches for all occurrences of a pattern in a string or paragraph or long text and returns a list of matches
Searches for all occurrences of a pattern in a string or paragraph or long text and then replace from given string and returns in string
Searches for all occurrences of a pattern in a string or paragraph or long text and then replace from given string and returns in string
re.findall returns list while re.sub returns string
Searches for all occurrences of a pattern in a string or paragraph or long text and replace from given string then returns a list of matches
count occurance in a list or string or sentence
Counting Occurrences in a String
counting Occurrences in a String after filter
Most common word
Counting Occurrences Across Multiple List by adding list
Counting Occurrences Across Multiple string by spliting then add
Accessing particular Counts
Get the 2 most common elements
Combining Counters with .update()
Finding Elements that Occur Only Once
convert counter object to list or dictionary
Converting into a Dictionary from Key-Value Arguments
how to itereate in muliple list
how to construct list of multiple dictionary
faq = [{"question": q, "answer": a} for q, a in zip(questions, answers)]
aq = [{"question": q, "answer": a, "category": c} for q, a, c in zip(questions, answers, categories)]
output
[
{'question': 'What is Python?', 'answer': 'Python is a programming language.', 'category': 'Programming'},
{'question': 'What is Django?', 'answer': 'Django is a web framework.', 'category': 'Web Development'},
{'question': 'What is Flask?', 'answer': 'Flask is a micro web framework.', 'category': 'Web Development'}
]
removing special characters, emojis, or unnecessary whitespaces. Code:
cleaned_text = " ".join(token.text for token in doc if token.is_alpha)
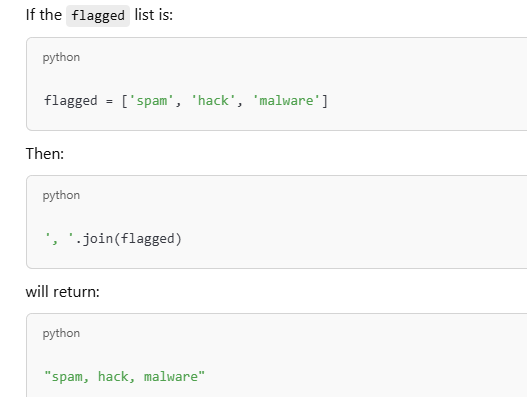
Each element in the list flagged will be joined with a comma and a space
print(f"Blacklisted words detected: {', '.join(flagged)}")
print(f"Blacklisted words detected: {', '.join(token.text for token in doc if token.text.lower() in blacklist)}")
Each element in the list flagged will be joined with a space
tokens = ["***" if token.lower() in profane_words else token for token in doc]
doc._.censored_text = " ".join(tokens) OR
doc._.censored_text = " ".join("***" if token.lower() in profane_words else token for token in doc)
custom mapping to dictionary keys
custom_lemmas = {"better": "good", "worse": "bad"} # Define custom mappings
for token in doc:
if token.text in custom_lemmas:
token.lemma_ = custom_lemmas[token.text]
initialize dictionary using dictionary comprehension or assign dynamic list of keywords
keyword_count = {keyword: 0 for keyword in keywords}
keyword_count = {"AI": 0, "machine learning": 0, "data": 0, "neural networks": 0}
Searches for all occurrences of a pattern in a string or paragraph or long text and returns a list of matches
urls = re.findall(url_pattern, doc.text)
emails = re.findall(email_pattern, doc.text)
Searches for all occurrences of a pattern in a string or paragraph or long text and then replace from given string and returns in string
url_pattern = r'https?://(?:www\.)?\S+'
# Replacement string for URLs
replacement = '[URL]'
# Replace all URLs with the replacement string
replaced_text = re.sub(url_pattern, replacement, doc_text)
Note
re.findall returns list while re.sub returns string
Searches for all occurrences of a pattern in a string or paragraph or long text and replace from given string then returns a list of matches
first way
# Sample text
text = "Visit https://example.com for more info. Then go to http://test.com."
# URL pattern to match
url_pattern = r'https?://(?:www\.)?\S+'
# Step 1: Replace URLs using re.sub
replaced_text = re.sub(url_pattern, "[URL]", text)
# Step 2: Use list comprehension to split the text and process each word
modified_list = [word for word in replaced_text.split()]
output
['Visit', '[URL]', 'for', 'more', 'info.', 'Then', 'go', 'to', '[URL].']
second way
replaced_text = re.sub(url_pattern, "[URL]", text)
modified_list = replaced_text.split()
thirdway
urls = re.findall(url_pattern, text)
modified_tokens = [re.sub(url_pattern, "[URL]", token) if re.match(url_pattern, token) else token for token in text.split()]
count occurance in a list or string or sentence
pos_counts = Counter(token.pos_ for token in doc)
from collections import Counter
items = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
item_count = Counter(items)
print(item_count)
output
Counter({'apple': 3, 'banana': 2, 'orange': 1})
Counting Occurrences in a String
from collections import Counter
text = "hello world"
char_count = Counter(text)
print(char_count)
Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
Example (Count words)
from collections import Counter
text = "hello world hello"
word_count = Counter(text.split())
print(word_count)
output
Counter({'hello': 2, 'world': 1})
counting dynamically
words = re.findall(r'\b\w+\b', sentence.lower())
word_count = Counter(words)
output
Counter({'this': 2, 'sentence': 2, 'is': 2, 'a': 1, 'test': 1, 'hello': 1, 'for': 1, 'testing': 1})
(Most common word):
sentence = "apple banana apple apple orange banana"
# Count words
word_count = Counter(sentence.split())
# Get most common word
most_common = word_count.most_common(1)
print(most_common)
output
[('apple', 3)]
Counting Occurrences Across Multiple Lists/Strings
from collections import Counter
list1 = ["apple", "banana", "cherry", "apple"]
list2 = ["banana", "apple", "date", "apple"]
list3 = ["cherry", "apple", "banana", "cherry"]
combined_counter = Counter(list1 + list2 + list3)
# Alternatively, you can use multiple counters and add them
counter1 = Counter(list1)
counter2 = Counter(list2)
counter3 = Counter(list3)
combined_counter = counter1 + counter2 + counter3
print(combined_counter)
output
Counter({'apple': 5, 'banana': 3, 'cherry': 3, 'date': 1})
from collections import Counter
sentence1 = "apple banana apple"
sentence2 = "banana apple date"
sentence3 = "cherry apple banana"
words1 = sentence1.split()
words2 = sentence2.split()
words3 = sentence3.split()
combined_counter = Counter(words1 + words2 + words3)
# Alternatively, you can use multiple counters and add them
counter1 = Counter(words1)
counter2 = Counter(words2)
counter3 = Counter(words3)
combined_counter = counter1 + counter2 + counter3
print(combined_counter)
Output:
Counter({'apple': 4, 'banana': 3, 'cherry': 1, 'date': 1})
most common element in a more than 2 list or 2 string or 2 sentence by combing counter
from collections import Counter
list1 = ["apple", "banana", "cherry", "apple"]
list2 = ["banana", "apple", "date", "apple"]
list3 = ["cherry", "apple", "banana", "cherry"]
combined_counter = Counter(list1 + list2 + list3)
counter1 = Counter(list1)
counter2 = Counter(list2)
counter3 = Counter(list3)
combined_counter = counter1 + counter2 + counter3
most_common = combined_counter.most_common(1)
print(f"The most common element is: {most_common[0]}")
The most common element is: ('apple', 5)
Accessing Counts
Counter({'banana': 3, 'apple': 2, 'orange': 1})
print(counter['banana']) # Output: 3
Get the 2 most common elements
most_common = counter.most_common(2)
print(most_common)
Output:
[('banana', 3), ('apple', 2)]
Combining Counters with .update()
counter = Counter(['apple', 'banana'])
# Update the counter with more elements
counter.update(['apple', 'cherry', 'banana', 'banana'])
print(counter)
Output:
Counter({'banana': 3, 'apple': 2, 'cherry': 1})
Finding Elements that Occur Only Once
elements = ['apple', 'banana', 'apple', 'orange', 'cherry', 'banana']
counter = Counter(elements)
# Find elements that occur exactly once
unique_elements = [item for item, count in counter.items() if count == 1]
print(unique_elements)
Output:
['orange', 'cherry']
sorted_by_key = sorted(counter.items())

convert counter object to list or dictionary
pos_counts = Counter(token.pos_ for token in doc)
doc._.pos_counts = dict(pos_counts)
=========OR===============
dict(Counter(['apple', 'apple', 'orange'])) {'apple': 2, 'orange': 1}
list(Counter('aabbc').items()) [('a', 2), ('b', 2), ('c', 1)]
===============OR==================
pos_counts = Counter(token.pos_ for token in doc)
# Convert to a list of tuples (pos_tag, count)
pos_list = list(pos_counts.items())
# Optional: Sort the list by count (if desired)
sorted_pos_list = sorted(pos_list, key=lambda x: x[1], reverse=True)
Convert dictionary from various format
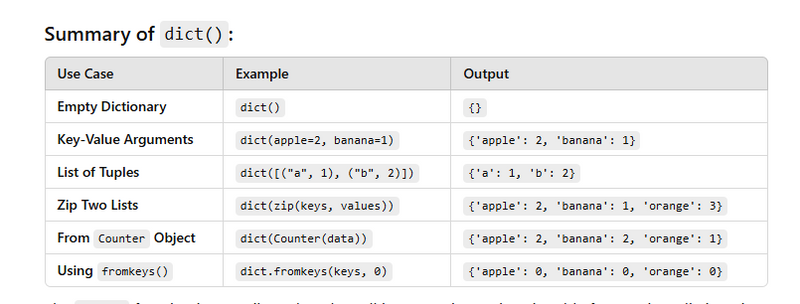
Converting into a Dictionary from Key-Value Arguments
my_dict = dict(a=1, b=2, c=3)
`output`
{'a': 1, 'b': 2, 'c': 3}
Converting into a Dictionary from a List of Tuples
# List of tuples containing key-value pairs
tuple_list = [('a', 1), ('b', 2), ('c', 3)]
# Converting the list of tuples into a dictionary
my_dict = dict(tuple_list)
print(my_dict)
Output:
{'a': 1, 'b': 2, 'c': 3}
Converting into a Dictionary from a zip Object
keys = ["name", "age", "city"]
values = ["Alice", 25, "New York"]
# Use zip() to combine the two lists and convert it into a dictionary
my_dict = dict(zip(keys, values))
print(my_dict)
Output:
{'name': 'Alice', 'age': 25, 'city': 'New York'}
==============or==================
Using List Comprehension Inside zip() to Create Keys and Values Dynamically
output


================or==================
Dynamic Key-Value Creation Based on Index
output


================or==================
Dynamic Key and Value Computation Based on Some Condition
output


Converting into a Dictionary using Counter
from collections import Counter
# List of items
items = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
# Using Counter to count occurrences and create a dictionary-like object
counter = Counter(items)
# Convert Counter to dictionary
my_dict = dict(counter)
print(my_dict)
Output:
{'apple': 3, 'banana': 2, 'orange': 1}
Converting into a Dictionary using List Comprehension
# List of tuples (key, value)
pairs = [('a', 1), ('b', 2), ('c', 3)]
# Using list comprehension to convert into a dictionary
my_dict = {key: value for key, value in pairs}
print(my_dict)
Output:
{'a': 1, 'b': 2, 'c': 3}
Converting into a Dictionary from a String (Key-Value Pairs)
# String with key-value pairs
data = "a=1, b=2, c=3"
# Converting the string to a dictionary
my_dict = dict(item.split('=') for item in data.split(', '))
print(my_dict)
Output:
{'a': '1', 'b': '2', 'c': '3'}
Using fromkeys() Method to Create a Dictionary
# List of keys
keys = ['a', 'b', 'c']
# Using fromkeys() to create a dictionary with all values set to 0
my_dict = dict.fromkeys(keys, 0)
print(my_dict)
Output:
{'a': 0, 'b': 0, 'c': 0}
Converting from JSON String to Dictionary
import json
# JSON string
json_string = '{"a": 1, "b": 2, "c": 3}'
# Converting JSON string to dictionary
my_dict = json.loads(json_string)
print(my_dict)
Output:
{'a': 1, 'b': 2, 'c': 3}
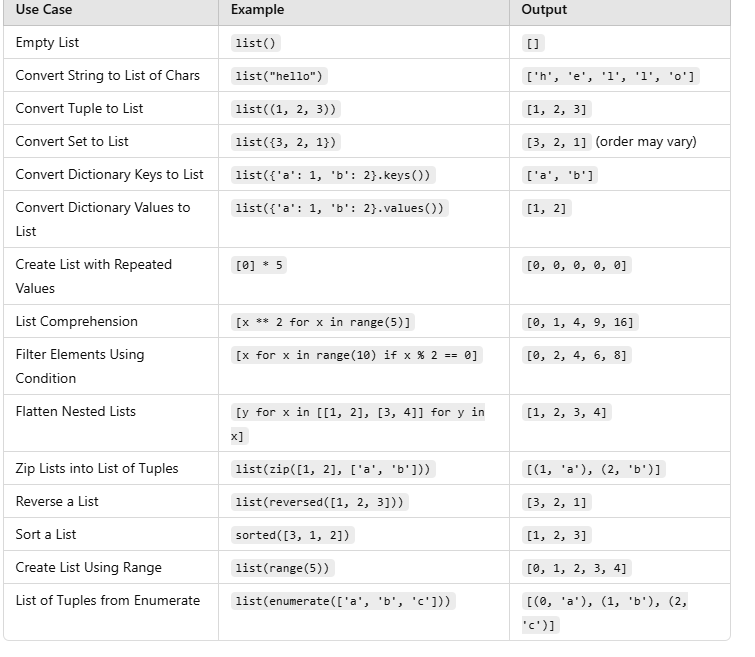
Convert a String to a List
When converting a string into a list, each character in the string will become an element in the list.
# Example string
my_string = "hello"
# Convert string to list of characters
my_list_from_string = list(my_string)
print(my_list_from_string)
Output:
['h', 'e', 'l', 'l', 'o']
-
Convert a Set to a ListYou can easily convert a set to a list using the list() constructor. Keep in mind that sets are unordered collections, so the resulting list may not maintain the order of the elements.
my_set = {1, 2, 3, 4}
# Convert set to list
my_list_from_set = list(my_set)
print(my_list_from_set)
Output:
[1, 2, 3, 4]
(The order of elements might vary because sets are unordered.)
-
Convert a Tuple to a ListTo convert a tuple to a list, you can use the list() constructor. The tuple's order will be preserved in the resulting list.
Code:
# Example tuple
my_tuple = (1, 2, 3, 4)
# Convert tuple to list
my_list_from_tuple = list(my_tuple)
print(my_list_from_tuple)
Output:
[1, 2, 3, 4]
Convert a Dictionary to a List
Code:
# Example dictionary
my_dict = {'a': 1, 'b': 2, 'c': 3}
# Convert dictionary keys to a list
keys_list = list(my_dict.keys())
# Convert dictionary values to a list
values_list = list(my_dict.values())
# Convert dictionary items (key-value pairs) to a list of tuples
items_list = list(my_dict.items())
print(keys_list)
print(values_list)
print(items_list)
Output
:
['a', 'b', 'c']
[1, 2, 3]
[('a', 1), ('b', 2), ('c', 3)]
-
Convert Multiple Data Types into a List
# Example data types
my_string = "hello"
my_set = {1, 2, 3}
my_tuple = (4, 5)
my_dict = {'a': 1, 'b': 2}
# Combine them into a single list
combined_list = list(my_string) + list(my_set) + list(my_tuple) + list(my_dict.keys())
print(combined_list)
Output:
['h', 'e', 'l', 'l', 'o', 1, 2, 3, 4, 5, 'a', 'b']
-
Convert Multiple Data Types into a List (Alternative Approach).
Code:
# Example data types
my_string = "hello"
my_set = {1, 2, 3}
my_tuple = (4, 5)
my_dict = {'a': 1, 'b': 2}
# Combine them as separate lists in one list
combined_separated_list = [list(my_string), list(my_set), list(my_tuple), list(my_dict.items())]
print(combined_separated_list)
Output:
[['h', 'e', 'l', 'l', 'o'], [1, 2, 3], [4, 5], [('a', 1), ('b', 2)]]
Combine Multiple Lists
To combine multiple lists, you can use the + operator or extend() method to concatenate them into one list.
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list3 = [7, 8, 9]
# Combine using + operator
combined_list = list1 + list2 + list3
# Or using extend()
list1.extend(list2)
list1.extend(list3)
print("Combined List:", combined_list)
print("Combined List using extend:", list1)
Output:
Combined List: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Combined List using extend: [1, 2, 3, 4, 5, 6, 7, 8, 9]
-
Reverse a ListTo reverse a list, you can use the reversed() function or the slicing technique.
# Reverse a list using reversed()
reversed_list = list(reversed(combined_list))
# Or using slicing
reversed_list2 = combined_list[::-1]
print("Reversed List using reversed():", reversed_list)
print("Reversed List using slicing:", reversed_list2)
Output:
Reversed List using reversed(): [9, 8, 7, 6, 5, 4, 3, 2, 1]
Reversed List using slicing: [9, 8, 7, 6, 5, 4, 3, 2, 1]
-
Sort a ListTo sort a list in ascending or descending order, you can use the sort() method (which modifies the list in place) or sorted() (which returns a new sorted list).
# Sort list in ascending order
sorted_list = sorted(combined_list)
# Sort list in descending order
sorted_desc_list = sorted(combined_list, reverse=True)
# Or sort in place using sort()
combined_list.sort() # Ascending order
combined_desc_list = combined_list.copy()
combined_desc_list.sort(reverse=True) # Descending order
print("Sorted List (Ascending):", sorted_list)
print("Sorted List (Descending):", sorted_desc_list)
print("Sorted In Place (Ascending):", combined_list)
print("Sorted In Place (Descending):", combined_desc_list)
Output:
Sorted List (Ascending): [1, 2, 3, 4, 5, 6, 7, 8, 9]
Sorted List (Descending): [9, 8, 7, 6, 5, 4, 3, 2, 1]
Sorted In Place (Ascending): [1, 2, 3, 4, 5, 6, 7, 8, 9]
Sorted In Place (Descending): [9, 8, 7, 6, 5, 4, 3, 2, 1]
4.Remove Duplicates
To remove duplicates from a list while maintaining the order, you can use a set() combined with list comprehension.
Code:
list_with_duplicates = [1, 2, 2, 3, 4, 4, 5, 5, 6]
# Remove duplicates while maintaining order
unique_list = list(dict.fromkeys(list_with_duplicates))
print("List with Duplicates removed:", unique_list)
Output:
List with Duplicates removed: [1, 2, 3, 4, 5, 6]
-
Filter a List Based on ConditionYou can use list comprehension or the filter() function to filter elements based on a condition.
Code:
# Filter even numbers from a list
even_numbers = [num for num in combined_list if num % 2 == 0]
# Or using filter() function
even_numbers_filter = list(filter(lambda x: x % 2 == 0, combined_list))
print("Even Numbers (List Comprehension):", even_numbers)
print("Even Numbers (Using filter()):", even_numbers_filter)
Output:
Even Numbers (List Comprehension): [2, 4, 6, 8]
Even Numbers (Using filter()): [2, 4, 6, 8]
-
Find the Most Frequent ElementTo find the most frequent element across multiple lists, you can use the Counter class from the collections module.
Code:
from collections import Counter
list1 = [1, 2, 3, 4, 1]
list2 = [5, 1, 6, 2, 1]
list3 = [7, 1, 8, 1, 9]
# Combine all lists
combined_lists = list1 + list2 + list3
# Use Counter to get the frequency of each element
counter = Counter(combined_lists)
# Find the most common element
most_common_element = counter.most_common(1)
print("Most Common Element:", most_common_element)
Output:
Most Common Element: [(1, 5)]
-
Flatten Nested ListsTo flatten a nested list, you can use a list comprehension or a recursive function.
Code:
nested_list = [[1, 2, 3], [4, 5], [6, 7]]
# Using list comprehension to flatten
flattened_list = [item for sublist in nested_list for item in sublist]
print("Flattened List:", flattened_list)
Output:
Flattened List: [1, 2, 3, 4, 5, 6, 7]
-
Zip Multiple Lists TogetherYou can use zip() to combine multiple lists element-wise.
Code:
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
# Zip lists together
zipped = list(zip(list1, list2))
print("Zipped Lists:", zipped)
Output:
Zipped Lists: [(1, 'a'), (2, 'b'), (3, 'c')]
-
Apply Functions to ListsYou can apply functions to each element in a list using map() or list comprehension.
# Example function to square numbers
def square(x):
return x ** 2
# Apply using map
squared_numbers = list(map(square, combined_list))
# Or using list comprehension
squared_numbers_comprehension = [x ** 2 for x in combined_list]
print("Squared Numbers (map):", squared_numbers)
print("Squared Numbers (List Comprehension):", squared_numbers_comprehension)
Output:
Squared Numbers (map): [1, 4, 9, 16, 25, 36, 49, 64, 81]
Squared Numbers (List Comprehension): [1, 4, 9, 16, 25, 36, 49, 64, 81]
-
Sum of Elements in a ListYou can use the sum() function to find the sum of elements in a list.
# Sum elements in a list
total_sum = sum(combined_list)
print("Sum of List:", total_sum)
Output:
um of List: 45
extract the first person's name
name = next((ent.text for ent in doc.ents if ent.label_ == "PERSON"), None)
==============================OR======================
for ent in doc.ents:
if ent.label_ == "PERSON":
name = ent.text
break # Stop after finding the first PERSON entity
token text starts or ends with special symbol
token.text for token in doc if token.text.startswith("#")
token.text for token in doc if token.text.startswith("@")
sent.text for sent in doc.sents if sent.text.endswith("?")
sent.text for sent in doc.sents if not sent.text.endswith("?")
filter its sentences based on the presence of certain keywords or clauses from the list key_clauses
[sent.text for sent in doc.sents if any(clause in sent.text.lower() for clause in key_clauses)]
===============OR======================
clauses = []
for sent in doc.sents:
if any(clause in sent.text.lower() for clause in key_clauses):
clauses.append(sent.text)
store input text or llm response in list of elements
positive_words, negative_words = response.split("\n\n")
positive_list = [word.strip() for word in positive_words.split(",")]
====================or=========================================
keywords = [keyword.strip() for keyword in response.split(",")]
convert list data into set
keywords = [keyword.strip() for keyword in response.split(",")]
return set(keywords)
how to compares two sequences (strings, lists, etc.) and finds the longest contiguous matching subsequence between them
how to returns similarity score between two sequences (strings, lists, etc.
similarity = SequenceMatcher(None, sent.text, db_doc).ratio()
difference between doc,doc.sents and doc.text
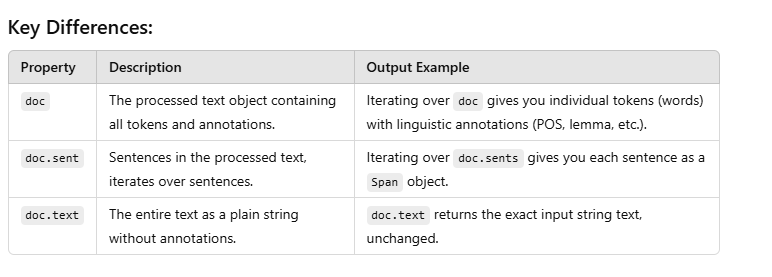
After Iterating over doc what ouput i will get
words or token
After Iterating over doc.sents what ouput i will get
`Sentences in the processed text`
Can i iterate over doc.text
no
Contains the original text or entire text as a plain string
exact input string text
After iterating doc i will get output token, from token what are the more things i will get
nlp = spacy.load("en_core_web_sm")
# Example text
text = "Apple is looking at buying U.K. startup for $1 billion. The company has been growing rapidly."
# Process the text with spaCy
doc = nlp(text)
# Iterate over each token and print various attributes
for token in doc:
print(f"Token: {token.text}")
print(f"Lemma: {token.lemma_}")
print(f"POS: {token.pos_}")
print(f"Tag: {token.tag_}")
print(f"Dep: {token.dep_}")
print(f"Head: {token.head.text}")
print(f"Is Stop: {token.is_stop}")
print(f"Is Alpha: {token.is_alpha}")
print(f"Is Digit: {token.is_digit}")
print(f"Shape: {token.shape_}")
print(f"Is Punct: {token.is_punct}")
print(f"Ent Type: {token.ent_type_}")
print(f"Ent IOB: {token.ent_iob_}")
print(f"Vector (first 10 elements): {token.vector[:10]}") # Only first 10 elements for display
print("-" * 40)

Token: Apple
Lemma: Apple
POS: PROPN
Tag: NNP
Dep: nsubj
Head: looking
Is Stop: False
Is Alpha: True
Is Digit: False
Shape: Xxxxx
Is Punct: False
Ent Type: ORG
Ent IOB: B
Vector (first 10 elements): [0.23762972 0.0010471 0.10166511 -0.23210286 -0.03329169 0.02825635
0.22114269 -0.07173653 -0.00645234 -0.08234595]
----------------------------------------
Token: is
Lemma: be
POS: AUX
Tag: VBZ
Dep: ROOT
Head: looking
Is Stop: True
Is Alpha: True
Is Digit: False
Shape: xx
Is Punct: False
Ent Type:
Ent IOB: O
Vector (first 10 elements): [-0.16527251 -0.05125302 -0.04848239 0.06471313 0.23750917 -0.15849067
0.09828461 -0.17527371 0.12672948 0.04478811]
----------------------------------------
Token: looking
Lemma: look
POS: VERB
Tag: VBG
Dep: ROOT
Head: looking
Is Stop: False
Is Alpha: True
Is Digit: False
Shape: xxxx
Is Punct: False
Ent Type:
Ent IOB: O
Vector (first 10 elements): [ 0.00665388 -0.26470256 -0.25616258 0.11279883 0.13066134 -0.05102386
0.00930824 0.07289567 -0.05367638 0.03498989]
----------------------------------------
To get attribute, what are the possible rhings i have to iterate over doc
for token in doc
for sentence in doc.sents
for ent in doc.ents:
for np in doc.noun_chunks:
for component in nlp.pipe_names:
create a DataFrame from the tokens data after iterating over doc
import spacy
import pandas as pd
nlp = spacy.load("en_core_web_sm")
text = "Apple is looking at buying U.K. startup for $1 billion. The company has been growing rapidly."
doc = nlp(text)
tokens_data = []
for token in doc:
tokens_data.append({
"Token": token.text,
"Lemma": token.lemma_,
"POS": token.pos_,
"Tag": token.tag_,
"Dep": token.dep_,
"Head": token.head.text,
"Is Stop": token.is_stop,
"Is Alpha": token.is_alpha,
"Is Digit": token.is_digit,
"Shape": token.shape_,
"Is Punct": token.is_punct,
"Ent Type": token.ent_type_,
"Ent IOB": token.ent_iob_,
"Vector (first 10)": token.vector[:10] # Show only first 10 elements of the vector
})
df = pd.DataFrame(tokens_data)
print(df)

difference between while iterating
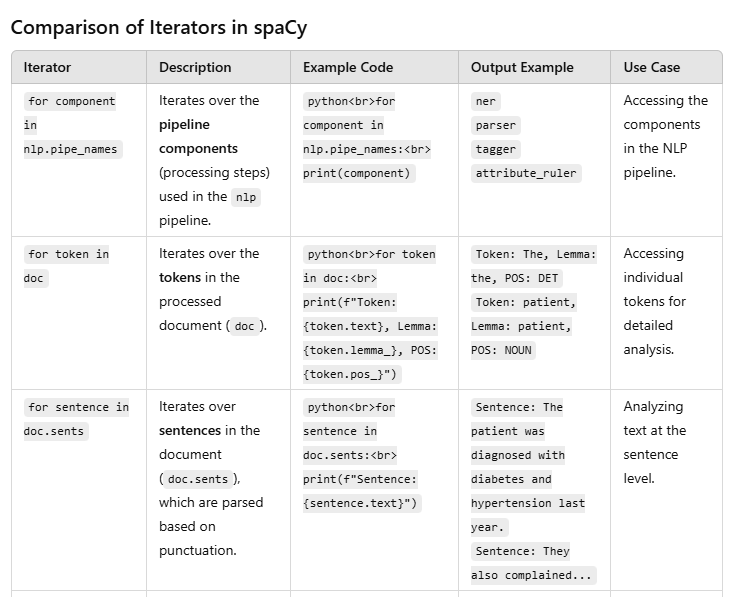
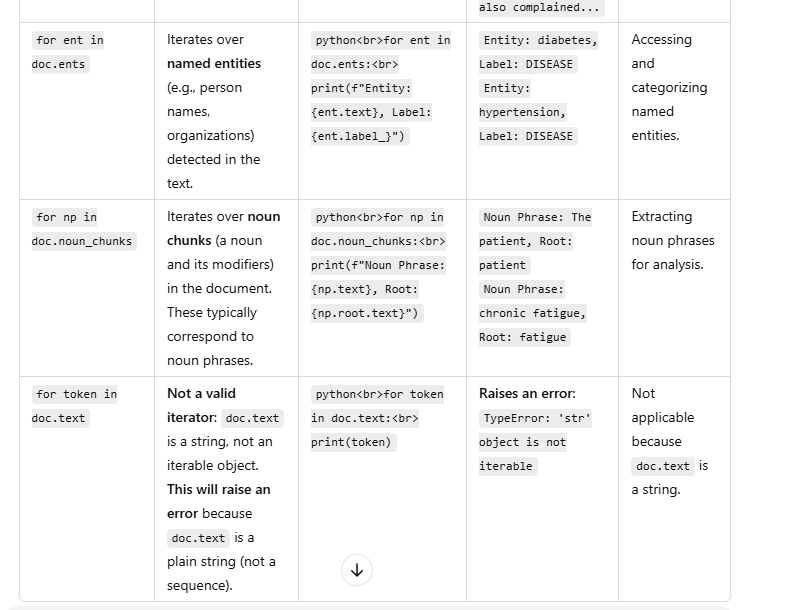

Top comments (0)