pros and cons of different Object detection architecture
Difference between faster rcnn and yolo Object detection architecture
Object detection in deep learning has evolved with various architectures, each with its own set of pros and cons. Here's a comparison of some popular object detection architectures:
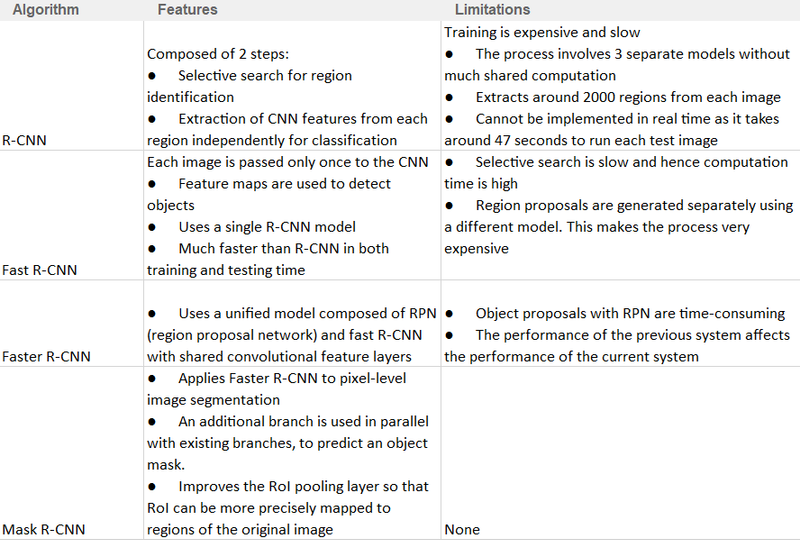
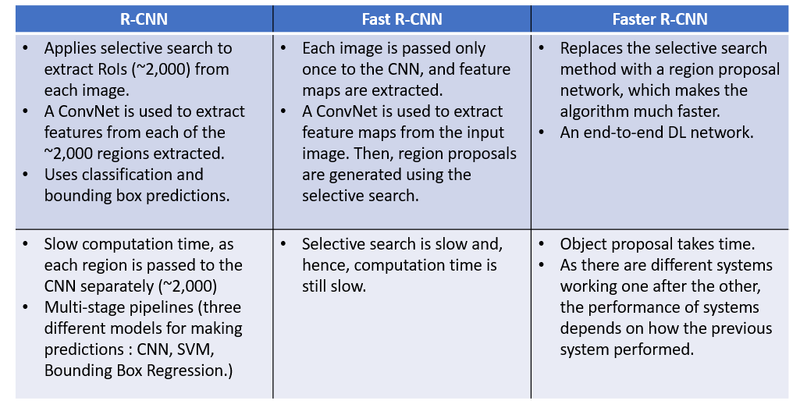
Region-based Convolutional Neural Networks (R-CNN):
Pros:
Accurate object localization.
Robust feature representation using CNN.
Suitable for small datasets.
Cons:
Slow inference due to region proposal and classification steps.
Complex and computationally expensive during training.
Fast R-CNN:
Pros:
End-to-end training for faster convergence.
Shared CNN features for region proposal and classification.
Improved speed over R-CNN.
Cons:
Slower than subsequent architectures.
Still computationally intensive during training.
Faster R-CNN:
Pros:
Introduction of Region Proposal Network (RPN) for efficient region proposal.
End-to-end training.
Better speed compared to R-CNN and Fast R-CNN.
Cons:
Can be complex to implement.
Inference speed still depends on the number of region proposals.
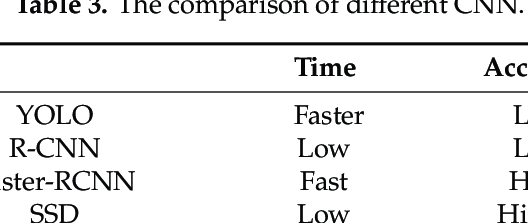
You Only Look Once (YOLO):
Pros:
Extremely fast inference speed.
Good performance on real-time applications.
Simplicity and efficiency.
Cons:
May struggle with small objects.
Lower accuracy compared to slower counterparts.
Sensitivity to object scale and aspect ratio.
Single Shot Multibox Detector (SSD):
Pros:
Good compromise between speed and accuracy.
Handles objects of different scales using multiple feature maps.
Simple architecture.
Cons:
Can be less accurate than slower architectures.
May struggle with small objects.
EfficientDet:
Pros:
Efficient architecture for balancing accuracy and speed.
Scales to different resource constraints using compound scaling.
State-of-the-art performance.
Cons:
Slightly more complex than simpler architectures.
RetinaNet:
Pros:
Addresses class imbalance with the introduction of Focal Loss.
High accuracy in detecting objects of different scales.
Performs well on challenging datasets.
Cons:
Relatively slower than some real-time architectures.
CenterNet:
Pros:
Simplicity and efficiency.
Direct regression of object centers.
Good performance on real-time applications.
Cons:
May struggle with extreme scale variations.
General Considerations:
Speed vs. Accuracy Trade-off:
Faster architectures sacrifice some accuracy for speed and vice versa.
Model Complexity:
Simpler architectures are easier to understand and implement but may sacrifice some performance.
Training and Inference Speed:
The efficiency of training and inference varies across architectures.
Handling of Small Objects:
Some architectures may struggle with accurately detecting small objects.
Dataset Size:
Some architectures are better suited for smaller datasets, while others benefit from large-scale datasets.
Resource Requirements:
The computational and memory requirements differ among architectures.
The choice of the object detection architecture depends on specific requirements, including real-time constraints, accuracy demands, and resource limitations. It's essential to consider the application context and dataset characteristics when selecting an architecture. Additionally, ongoing research leads to continuous improvements and the emergence of new architectures with enhanced capabilities.
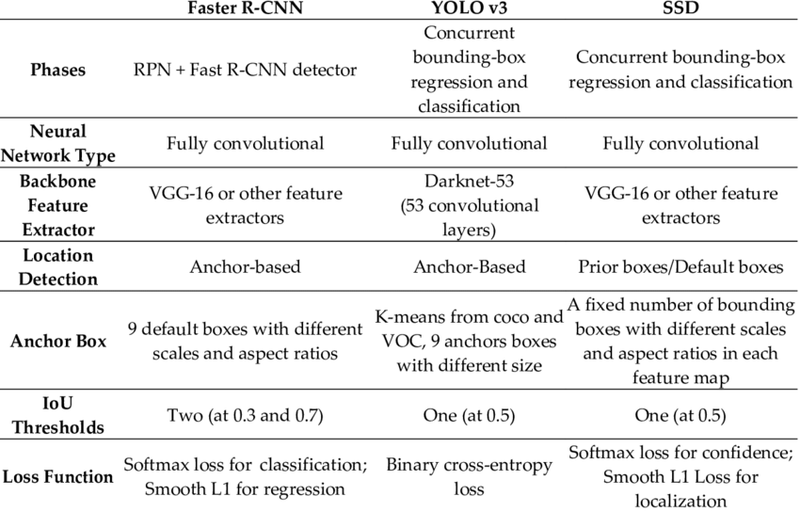
Difference between faster rcnn and yolo Object detection architecture
Faster R-CNN (Region-based Convolutional Neural Network) and YOLO (You Only Look Once) are both popular architectures for object detection in computer vision, but they differ in their approach to the task. Here are the key differences between Faster R-CNN and YOLO:
- Architectural Approach:
Faster R-CNN
:
Two-Stage Approach: Faster R-CNN follows a two-stage approach. It first generates region proposals using a Region Proposal Network (RPN) and then classifies and refines these proposals in the second stage.
Region Proposal Network (RPN): The RPN generates potential bounding box proposals by sliding a small window over the feature map and predicting whether there is an object or not in each window.
YOLO (You Only Look Once)
:
Single-Stage Approach: YOLO adopts a single-stage approach, processing the entire image in one forward pass. It divides the input image into a grid and predicts bounding boxes and class probabilities directly from the grid cells.
Grid-based Prediction: YOLO divides the image into a grid and predicts bounding boxes and class probabilities for each grid cell. Each grid cell is responsible for predicting objects within its boundaries.
- Speed: Faster R-CNN:
Typically slower than YOLO because of the two-stage approach.
The need for region proposals and subsequent refinement contributes to increased computational complexity.
YOLO
:
Known for its speed and real-time performance.
Processes the entire image at once, leading to faster inference.
- Accuracy: Faster R-CNN:
Generally achieves high accuracy, especially in scenarios where precise object localization is crucial.
Often used in applications with more demanding accuracy requirements.
YOLO
:
Provides a good balance between speed and accuracy.
Well-suited for scenarios where real-time processing is a priority, and high accuracy is not as critical.
- Handling of Small Objects: Faster R-CNN:
Can struggle with the detection of small objects due to the anchor-based proposal mechanism.
YOLO
Generally performs well in detecting small objects due to its grid-based approach.
- Use Cases: Faster R-CNN:
Commonly used in applications where high accuracy is a priority, such as medical imaging, autonomous vehicles, and detailed object recognition tasks.
YOLO
Well-suited for real-time applications, such as video surveillance, robotics, and situations where low-latency object detection is crucial.
- Versions and Variants: Faster R-CNN:
Has evolved with different versions, such as Faster R-CNN, Fast R-CNN, and Mask R-CNN.
YOLO:
Has different versions, including YOLOv1, YOLOv2 (YOLO9000), YOLOv3, and YOLOv4, each introducing improvements in terms of accuracy and speed.
Both Faster R-CNN and YOLO have their strengths and weaknesses, and the choice between them depends on the specific requirements of the application, such as the need for accuracy, real-time processing, or the nature of the objects being detected.

Top comments (0)