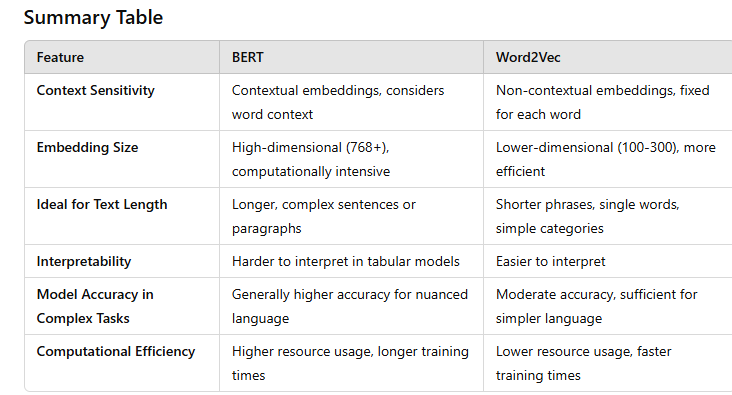
Key Differences Between BERT and Word2Vec
Contextual vs. Non-Contextual Embeddings:
- BERT generates contextual embeddings, meaning it produces different embeddings for the same word depending on its surrounding words (context). For example, "bank" in "river bank" will have a different embedding than "bank" in "financial bank."
Word2Vec produces non-contextual embeddings, meaning each word has a fixed vector representation, regardless of the surrounding words. As a result, it lacks the ability to differentiate meanings based on context
.
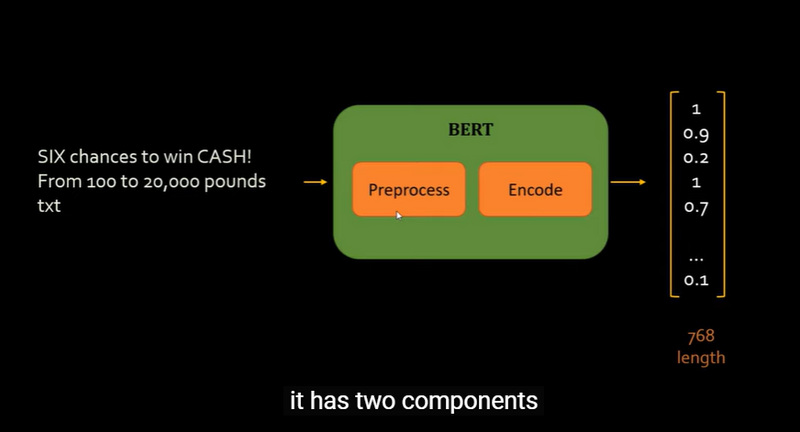
Embedding Dimensionality and Complexity:BERT embeddings are generally high-dimensional (e.g., 768 or 1024 dimensions) and are derived from large, deep transformer-based models. This high dimensionality and complexity provide nuanced information but come at the cost of computational efficiency.
Word2Vec embeddings are lower-dimensional (often 100-300 dimensions) and based on shallower neural networks (skip-gram or CBOW models). This simplicity makes them computationally faster but less powerful in capturing complex language patterns
.
Training Data and Purpose:BERT was trained on vast amounts of text data (like Wikipedia and BooksCorpus) with the objective of capturing deep semantic and syntactic relationships. It performs well on tasks requiring detailed text understanding.
Word2Vec was trained for simpler, often general-purpose word associations, like similarity and analogy tasks, but lacks the depth for sophisticated language tasks
.
Handling Unseen Words:BERT uses subword tokenization (e.g., WordPiece), meaning it can decompose unseen or rare words into smaller components (subwords). This allows it to handle a broader vocabulary.
Word2Vec is limited to words in its vocabulary. Unseen words are either ignored or require retraining, which can be a significant limitation in text-heavy tabular data
.
When Integrated with Tabular Data
When embedding text fields within tabular data, the choice between BERT and Word2Vec has practical implications for the model's performance and interpretability:
BERT in Tabular Models:
Pros:
- It provides richer, context-sensitive embeddings, making it better for text fields that are essential to understanding domain-specific jargon or complex linguistic nuances.
Fine-tuned BERT embeddings can significantly enhance the predictive power when text is critical for classification or regression tasks in tabular data
.
Cons:The embeddings are computationally intensive and may require fine-tuning specific to the task, which can be costly.
For simpler tabular models, BERT embeddings may add unnecessary complexity, potentially leading to overfitting or diminishing returns
.
Word2Vec in Tabular Models:
Pros:
- Word2Vec embeddings are faster to compute and may integrate seamlessly into standard tabular models, especially when textual features are secondary.
They work well for straightforward language patterns, where contextual nuance is less critical
.
Cons:Non-contextual embeddings mean they may lose essential meanings if words in the text fields are highly context-dependent.
In situations where polysemy (words with multiple meanings) is common, Word2Vec may reduce the model's accuracy due to lack of context-awareness
.
Which to Use?
BERT is ideal if:Text data has complex, domain-specific language.
The meaning of the text field significantly impacts the predictions.
Resources allow for computationally heavier models
.
Word2Vec is suitable if:Text fields are simpler or secondary to other features in the tabular data.
Computational efficiency is a priority.
You do not need fine-grained understanding of context for your task.
Both embeddings can add value to tabular data, but the choice largely depends on the nature of the text data and the computational constraint
s.




Top comments (0)