Using embed_query()
query_result = embeddings_specific.embed_query(text)
Purpose: This approach simply converts the input query (or text) into a vector (embedding) using the specified model (embeddings_specific).
Output: The output is a vector (numeric representation) of the text. This vector is a high-dimensional representation of the semantic meaning of the text but by itself, it doesn't tell you how similar the text is to any other content.
[0.1234, -0.5678, 0.9101, ..., 0.2345] # A list with 512 floating-point numbers
Usage: This method is useful if you just want to get the embedding of the query or text but don't need to compare it to any other content in your database. You might use it in scenarios where you want to process or analyze the query independently, or perhaps for storing it for future comparisons.
Example use case: If you're looking to store a query's embedding for later, but not compare it to existing documents right away.
from langchain_ollama import OllamaEmbeddings # Ollama embedding library
from langchain_community.vectorstores import Chroma # Vector store library
# Step 1: Create embeddings using Ollama
embeddings = OllamaEmbeddings(model="ollama-large") # Replace with your Ollama model
# Sample text to embed
query_text = "How can machine learning be used in healthcare?"
# Embed the query using Ollama
query_embedding = embeddings.embed_query(query_text)
print(query_embedding)
output
Query Embedding (vector): [0.1123, -0.4546, 0.9876, ..., 0.3412]
Using similarity_search(query) with a Vector Store
retrieved_results = db.similarity_search(query)
Purpose: The similarity_search(query) method is part of the vector store (db) and is used to compare the embedding of the query against the embeddings of documents already stored in the vector store. The vector store contains pre-computed embeddings of your documents or text, and you are searching for the most similar ones based on the query.
Process:
First, the query (like "How can machine learning be used in healthcare?") is embedded into a vector (numeric representation) using the embedding model.
The search then compares this query embedding with the embeddings of all the documents stored in the vector store (db) and retrieves the documents whose embeddings are most similar to the query embedding. The similarity is typically measured using cosine similarity or another metric.
Output: The output is a set of documents (or parts of documents) that are most similar to the query, based on the embedding comparison. This allows you to retrieve relevant content from a large corpus of documents based on the semantic meaning of the query.
[
{
"content": "Machine learning can analyze patient data to improve healthcare outcomes.",
"metadata": {"source": "document_1", "page": 2}
},
{
"content": "AI is transforming how diseases are diagnosed and treated.",
"metadata": {"source": "document_2", "page": 5}
}
]
Example use case: You have a collection of documents (e.g., medical papers, articles, or blog posts) in a database, and you want to retrieve the ones that are most relevant to the query about machine learning in healthcare.
from langchain_ollama import OllamaEmbeddings # Ollama embedding library
from langchain_community.vectorstores import Chroma # Vector store library
# Step 1: Create embeddings using Ollama
embeddings = OllamaEmbeddings(model="ollama-large") # Replace with your Ollama model
# Sample text to embed
query_text = "How can machine learning be used in healthcare?"
# Embed the query using Ollama
query_embedding = embeddings.embed_query(query_text)
loader=TextLoader('speech.txt')
docs=loader.load()
docs
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter=RecursiveCharacterTextSplitter(chunk_size=500,chunk_overlap=50)
final_documents=text_splitter.split_documents(docs)
final_documents
# Step 2: Retrieve data from the vector store
# Assuming `final_documents` and `db` are predefined
# Predefine and populate your vector store
db = Chroma.from_documents(final_documents, embeddings)
# Perform similarity search on the query
retrieved_results = db.similarity_search(query_text)
# Step 3: Append retrieved data to a list
results_list = [] # Initialize an empty list
for result in retrieved_results:
results_list.append(result["content"]) # Extract and append only the content of each result
# Step 4: Output the embedding and retrieved results
print("Query Embedding (vector):", query_embedding)
print("\nRetrieved Results:")
for idx, content in enumerate(results_list, start=1):
print(f"{idx}. {content}")
output
Retrieved Results:
1. "Machine learning is used to analyze patient data and provide predictive diagnostics."
2. "AI is transforming healthcare by enabling automated disease diagnosis."
from langchain_ollama import OllamaEmbeddings # Ollama for embeddings
from langchain_community.vectorstores import Chroma # Chroma Vector Store
# Step 1: Initialize Ollama Embeddings
embeddings = OllamaEmbeddings(model="gemma:2b") # Default model uses LLaMA2
# Step 2: Define Documents
documents = [
"Alpha is the first letter of Greek alphabet",
"Beta is the second letter of Greek alphabet",
]
# Step 3: Create a Vector Store
# Use Ollama embeddings directly as the embedding function
db = Chroma.from_texts(documents, embedding_function=embeddings.embed_documents)
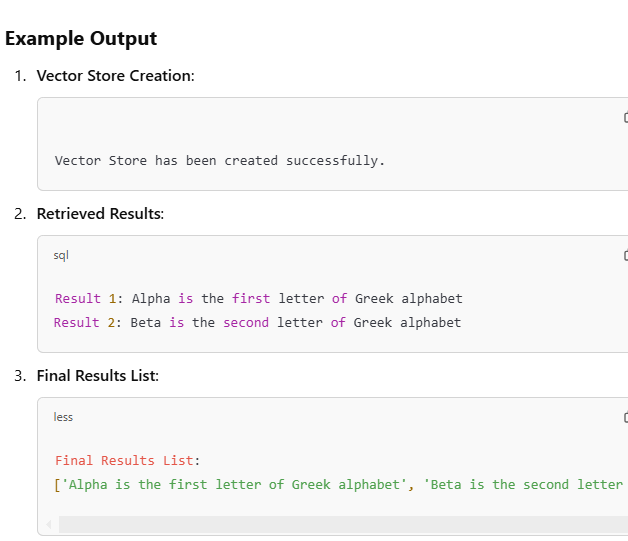
print("Vector Store has been created successfully.")
# Step 4: Perform a Similarity Search
query_text = "What is the first letter of the Greek alphabet?"
retrieved_results = db.similarity_search(query_text)
# Step 5: Append Results to a List
results_list = [] # Initialize an empty list to store results
for idx, result in enumerate(retrieved_results, start=1):
print(f"Result {idx}: {result['content']}")
results_list.append(result["content"]) # Append the content to the list
# Step 6: Final Results
print("\nFinal Results List:")
print(results_list)
output
Summary
Using embed_query()==>embeddings_specific.embed_query(text)
output is a vector (numeric representation) of the text
embedding of the query or text but don't need to compare it to any other content in your database
only store not compare
similarity_search(query) with a Vector Store===>db.similarity_search(query)
output is a set of documents (or parts of documents) that are most similar to the query
allow comparision then retrieve relevant content from a large corpus of documents
Coding example
Create embeddings using Ollama
Embed the query using Ollama
data ingestion or data loading==>splitting document
after splitting store in chroma vectordatabase==>db = Chroma.from_documents(final_documents, embeddings)
db.similarity_search(query_text)
Append retrieved data to a list inside for loop==> Extract and append only the content of each result==> results_list.append(result["content"])
output the embedding and retrieved results===>for idx, content in enumerate(results_list, start=1):

Top comments (0)