Challanges faced in RNN
Difference between LSTM and GRU
Architectural Details
Implemention of LSTM and GRU
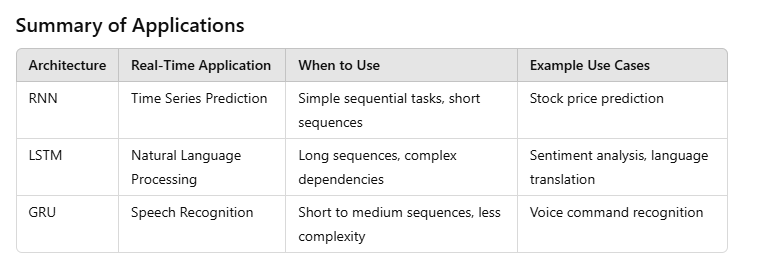
When to Use LSTM vs. GRU
Why GRU is best for speech recognization
Challanges faced in RNN
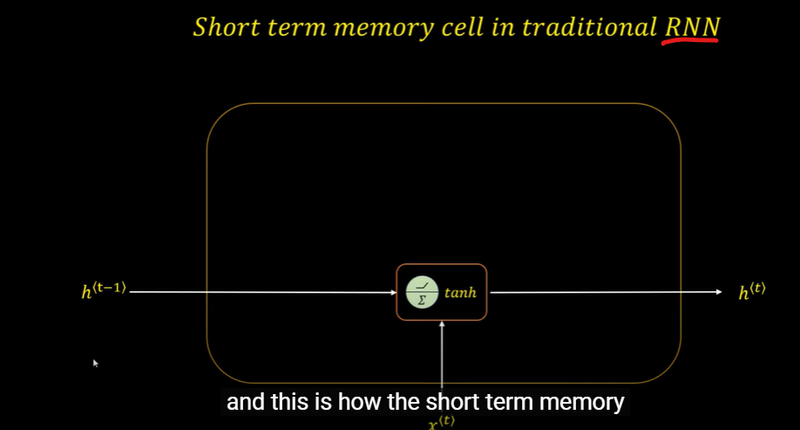
Short-Term Memory Cell in Traditional RNN
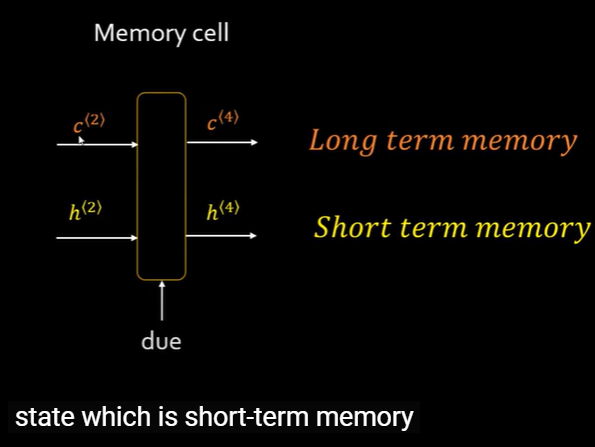

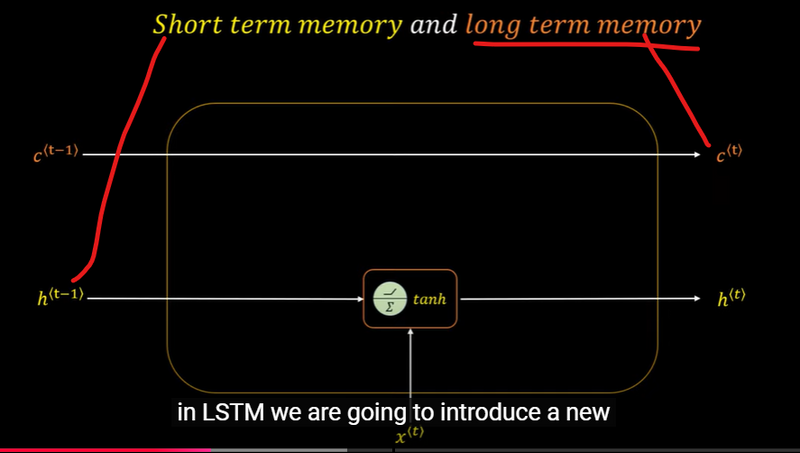
Short-Term and Long-Term Memory

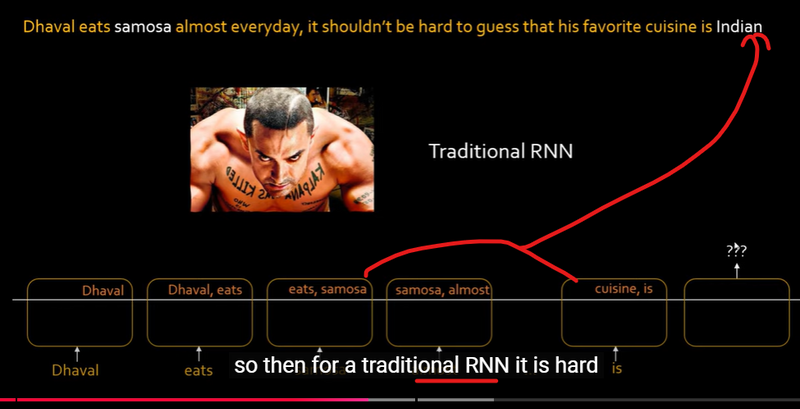
Traditional RNN Example

Contextual Understanding


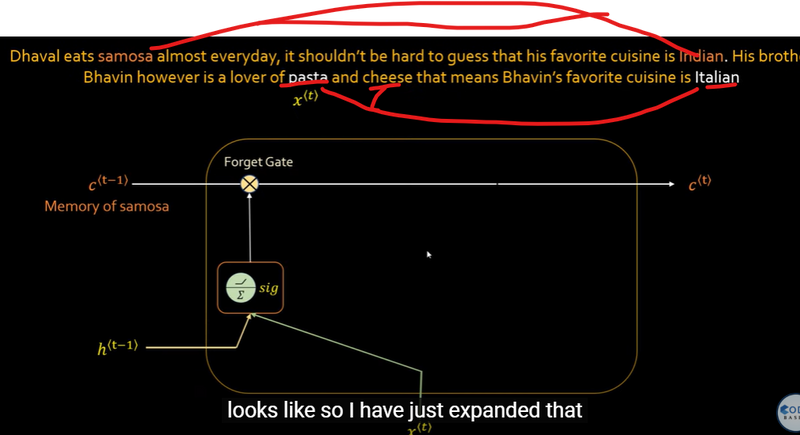
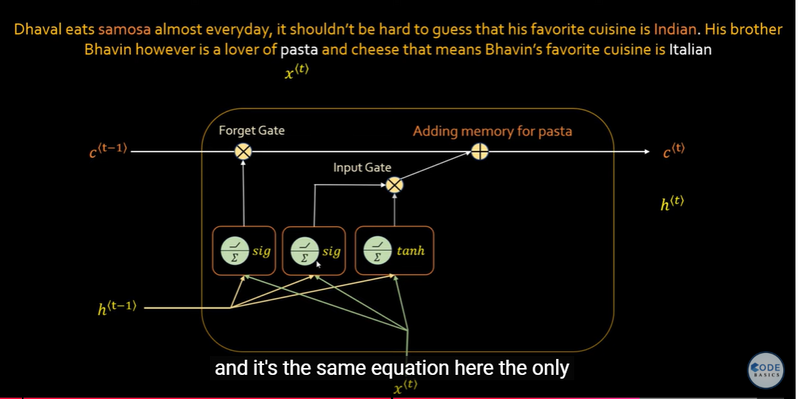
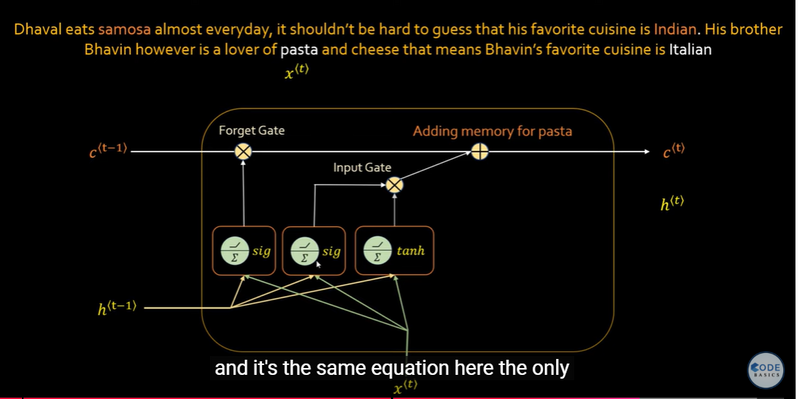
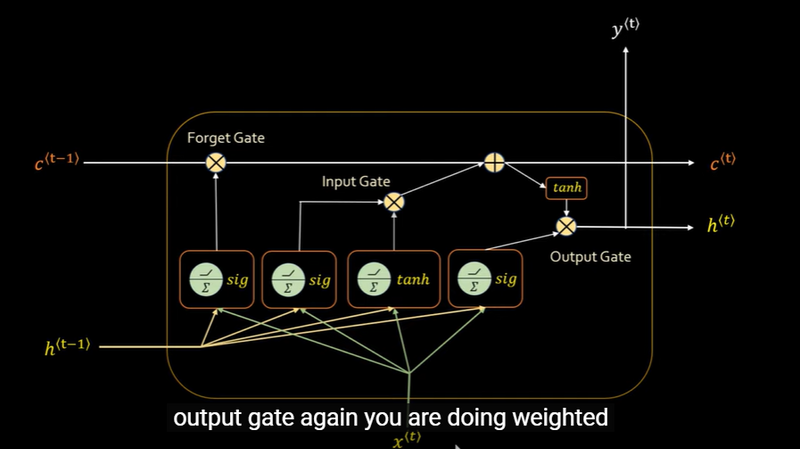
LSTM Architecture

Output Gate in LSTM

Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Gated Recurrent Units (GRUs) are all types of neural network architectures designed for processing sequential data. While they share some similarities, they differ in terms of their architecture and how they handle information over time. Here's a comparison of RNNs, LSTMs, and GRUs:
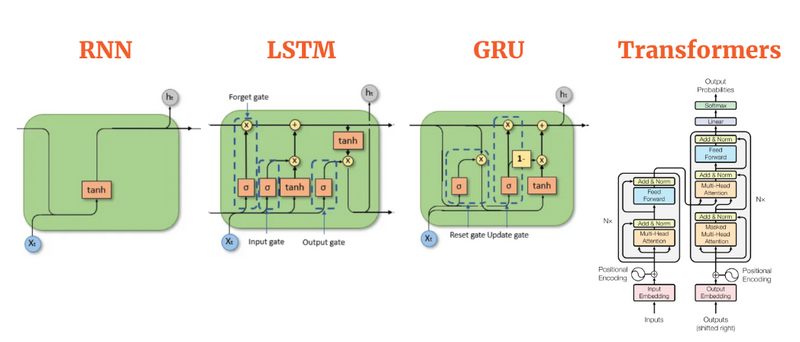
RNNs (Recurrent Neural Networks)
:
Basic Architecture: RNNs consist of a chain of repeating neural network modules. Each module takes an input and produces an output while also passing a hidden state to the next module in the sequence.
Memory: RNNs have a simple memory mechanism where the hidden state serves as the memory of the network. However, traditional RNNs suffer from the vanishing gradient problem, which limits their ability to capture long-term dependencies in sequences.
Training: RNNs are trained using backpropagation through time (BPTT), which is an extension of backpropagation that takes into account the sequential nature of the data.
Pros and Cons: RNNs are simple and easy to understand, but they struggle with capturing long-term dependencies and can suffer from issues like vanishing or exploding gradients.
LSTMs (Long Short-Term Memory Networks)
:
Architecture: LSTMs are a type of RNN specifically designed to address the vanishing gradient problem. They include additional components called "gates" that regulate the flow of information through the network.
Memory: LSTMs have more complex memory cells, which consist of a cell state and three gates: input gate, forget gate, and output gate. These gates allow LSTMs to selectively remember or forget information over long sequences, making them better suited for capturing long-term dependencies.
Training: LSTMs are trained using the same backpropagation algorithm as traditional RNNs, but they tend to converge more reliably due to their improved ability to capture long-term dependencies.
Pros and Cons: LSTMs are effective at capturing long-term dependencies and have become the standard for many sequential tasks. However, they are more complex and computationally expensive than traditional RNNs.
GRUs (Gated Recurrent Units)
Architecture: GRUs are a variation of LSTMs that combine the forget and input gates into a single "update gate." They also merge the cell state and hidden state, simplifying the architecture compared to LSTMs.
Memory: GRUs have a simpler architecture compared to LSTMs, but they still include gating mechanisms that allow them to selectively update and forget information over time.
Training: GRUs are trained using backpropagation similar to LSTMs, but they may converge faster due to their simpler architecture.
Pros and Cons: GRUs are computationally efficient and may be easier to train than LSTMs due to their simpler architecture. However, they may not perform as well as LSTMs on tasks that require capturing very long-term dependencies.
In summary, while RNNs, LSTMs, and GRUs are all types of recurrent neural networks used for processing sequential data, they differ in terms of their architecture, memory mechanisms, training algorithms, and performance characteristics. LSTMs and GRUs are extensions of basic RNNs designed to address the limitations of traditional RNNs in capturing long-term dependencies.
Difference between LSTM and GRU
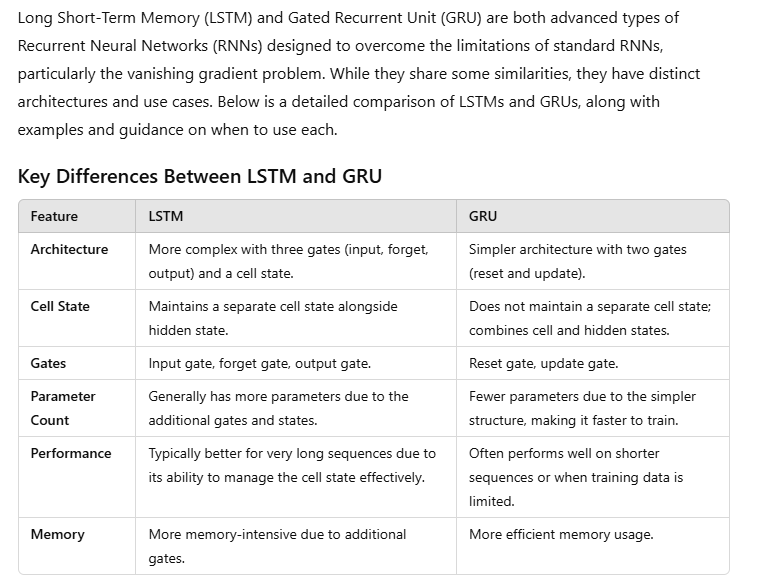
Architectural Details

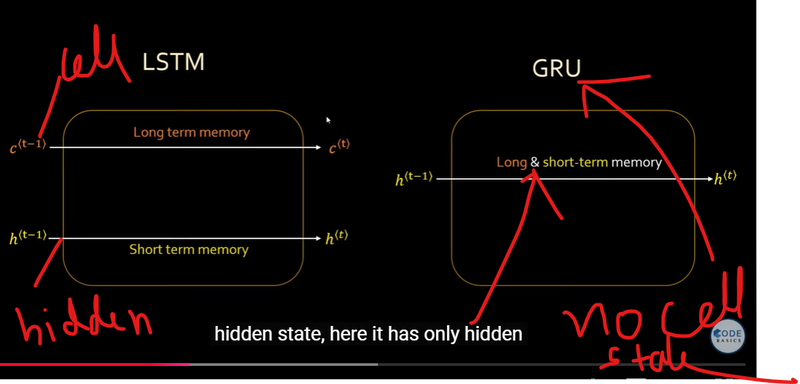


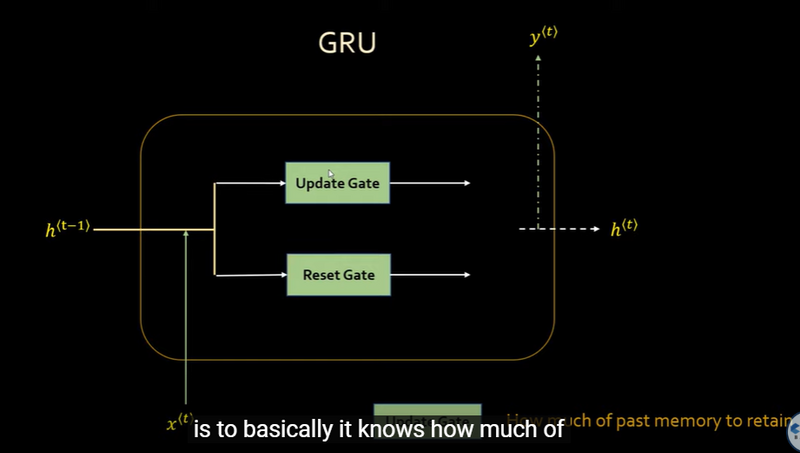

Example Implementation
Here’s how you can implement LSTM and GRU models for a sequence classification task using TensorFlow/Keras.
Using LSTM
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# Generate some random data for demonstration
X_train = np.random.rand(1000, 10, 64) # 1000 samples, 10 timesteps, 64 features
y_train = np.random.randint(2, size=(1000, 1)) # Binary classification
# Build the LSTM model
model_lstm = Sequential()
model_lstm.add(LSTM(64, input_shape=(10, 64))) # 64 units
model_lstm.add(Dense(1, activation='sigmoid')) # Output layer for binary classification
# Compile the model
model_lstm.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model_lstm.fit(X_train, y_train, epochs=5, batch_size=32)
Using GRU
from tensorflow.keras.layers import GRU
# Build the GRU model
model_gru = Sequential()
model_gru.add(GRU(64, input_shape=(10, 64))) # 64 units
model_gru.add(Dense(1, activation='sigmoid')) # Output layer for binary classification
# Compile the model
model_gru.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model_gru.fit(X_train, y_train, epochs=5, batch_size=32)
When to Use LSTM vs. GRU





Top comments (0)