Explain Model architecture of Alexnet
Explain pros and cons of Alexnet
Explain Model architecture of Alexnet
AlexNet is a deep convolutional neural network (CNN) that gained significant attention and marked a breakthrough in the field of deep learning, especially in the context of image classification. It was developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton and won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012.
LSVRC (Large Scale Visual Recognition Challenge) is a competition where research teams evaluate their algorithms on a huge dataset of labeled images (ImageNet) and compete to achieve higher accuracy on several visual recognition tasks. This made a huge impact on how teams approach the completion afterward.
The AlexNet contains 8 layers with weights;
5 convolutional layers
3 fully connected layers.
Here are the key components and features of AlexNet:
Architecture:
AlexNet consists of eight layers in total, with five convolutional layers followed by three fully connected layers.
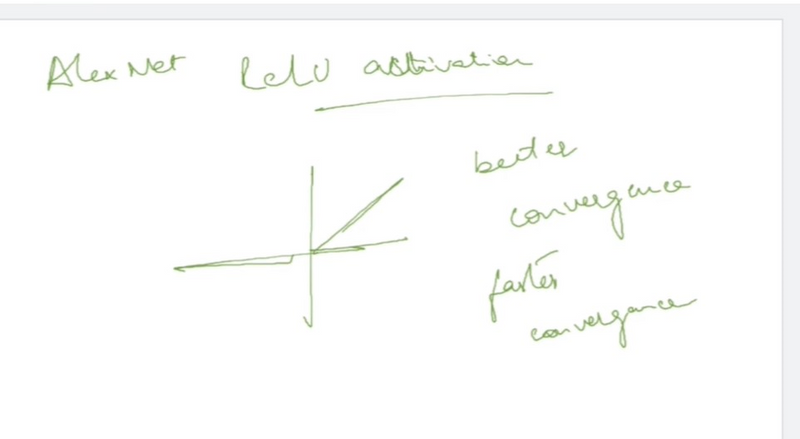
It uses the rectified linear unit (ReLU) activation function, which helps in overcoming the vanishing gradient problem and speeds up the training process.
Convolutional Layers:
The first convolutional layer has 96 kernels of size
11×11×3 (where 3 is for the RGB channels).
Subsequent convolutional layers use smaller filter sizes (e.g.,
5*5) and are followed by max-pooling layers.
Max-pooling is applied to reduce the spatial dimensions and capture the most important features.
Local Response Normalization (LRN):
LRN is applied after the first and second convolutional layers to normalize the responses within a local neighborhood.
This helps enhance the contrast between the activated neurons and improves generalization.
Fully Connected Layers:
The final three layers are fully connected layers. The first two have 4096 neurons each, and the last one has 1000 neurons corresponding to the ImageNet classes.
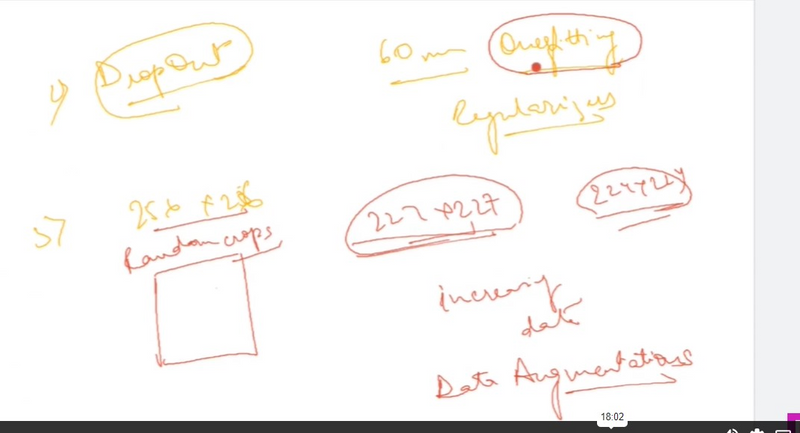
Dropout is applied to these fully connected layers during training to prevent overfitting.
Softmax Activation:
The output layer uses the softmax activation function to convert the final layer's outputs into probabilities for different classes.
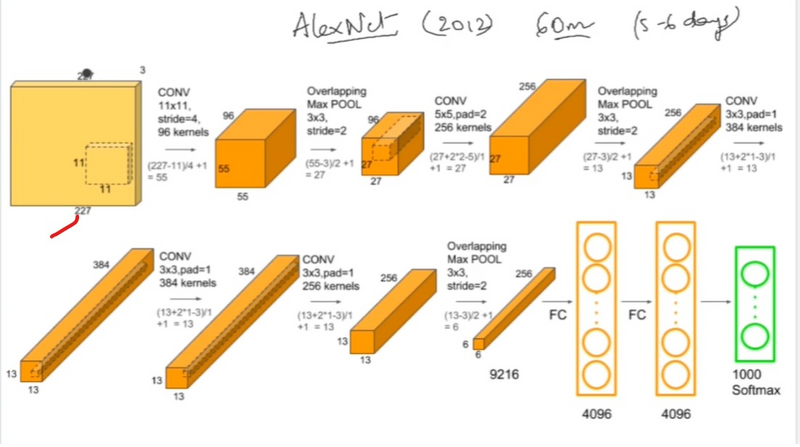
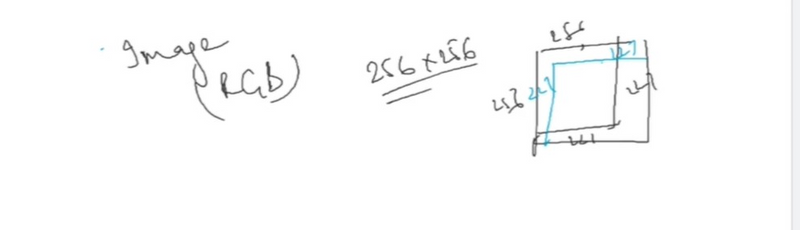
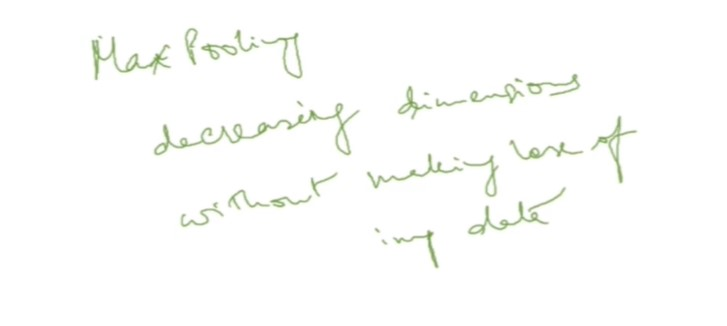
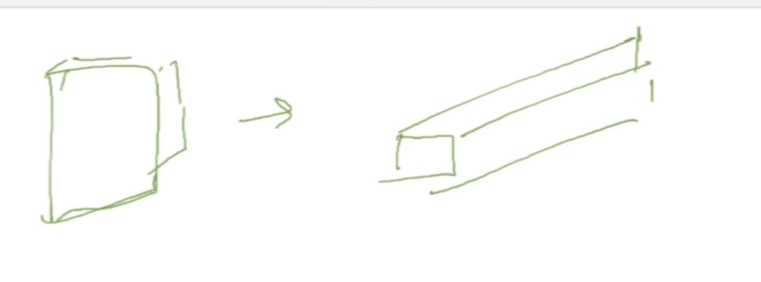

5 convolution layer , 3 fully connected layer
96 feature image map ,one is edge,other is corner
[(n-k +2p)/s]+1
In first convolution
96 feature map
p=0(valid padding means there is no padding)
s=4(stride)
n=227
conv or filter size=k=11*11
input dimension size=n=227*227
[(227-11+2*0)/4] +1=55
In second convolution
p=0(valid padding means there is no padding)
s=2(stride)
max pooling=k=3*3
input dimension size=n=55*55
[(55-3+2*0)/2] +1=27
max-pooling====>decreasing dimension without making lose information
basic goals of image net architecture====> decreasing width and height and increasing depth



Explain pros and cons of Alexnet
AlexNet is a deep convolutional neural network architecture that gained significant attention for its breakthrough performance in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012. Here are some pros and cons of AlexNet:
Pros:
Effectiveness in Image Classification:
Pro: AlexNet demonstrated excellent performance in image classification tasks, significantly outperforming previous methods and winning the ILSVRC 2012 competition.
Use of Convolutional Layers:
Pro: AlexNet popularized the use of deep convolutional neural networks for image processing tasks. The use of convolutional layers allows the network to automatically learn hierarchical features.
Local Response Normalization (LRN):
Pro: AlexNet introduced Local Response Normalization in its architecture, which helps in lateral inhibition among the neurons. This can enhance the model's ability to generalize and respond to different inputs.
Data Augmentation:
Pro: To combat overfitting, AlexNet used data augmentation techniques during training, such as random cropping and flipping of input images. This contributes to improved generalization to unseen data.
Parallelization:
Pro: AlexNet made effective use of parallelization by distributing the workload across two GPUs. This helped in training the deep network efficiently, contributing to faster convergence during training.
Cons:
Computational Complexity:
Con: AlexNet is computationally intensive, especially for its time. Training deep neural networks with a large number of parameters requires significant computational resources, which might not be readily available in some environments.
Overfitting:
Con: With a large number of parameters, AlexNet is susceptible to overfitting, especially if the training dataset is not sufficiently large. Regularization techniques like dropout are often needed to mitigate this issue.
Memory Consumption:
Con: AlexNet's architecture may consume a significant amount of memory, which can be a limitation, especially on GPUs with limited memory capacity. This can lead to issues, especially when working with large image datasets.
Need for Large Datasets:
Con: Training deep networks like AlexNet effectively requires large amounts of labeled data. Obtaining such datasets, particularly for specific domains, might be challenging.
Difficulty in Deployment on Resource-Constrained Devices:
Con: The computational demands of AlexNet can make deployment on resource-constrained devices challenging. In applications where model size and computational efficiency are critical, simpler architectures may be preferred.
Limited Interpretability:
Con: The deep and complex nature of the network can make it challenging to interpret how the network is making decisions. Understanding the learned features and representations may be more difficult compared to simpler architectures.
In summary, while AlexNet marked a significant milestone in the development of deep learning architectures, it comes with challenges related to computational complexity, overfitting, and deployment on resource-constrained devices. Despite these limitations, its success paved the way for the development of more advanced architectures and contributed to the widespread adoption of deep learning in computer vision tasks.

Top comments (0)