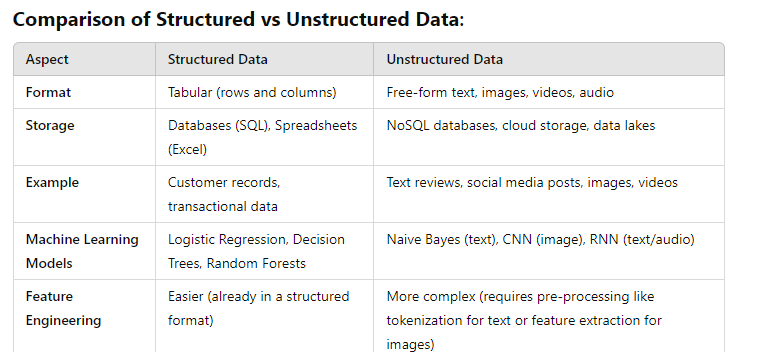
Difference between structured data and unstructured data in terms of format,storage,example,ML models,feature engeenering
which ML algorithm is best when various decision trees to make the classification or more complex model want to use
How CNN classify image based on
what are the common preprocessing technique for text data and image data
how to transition perform text to structured data and image to structured data
Here are examples of structured and unstructured data, along with examples of models that are typically applied to each type of data.
- Structured Data: Definition: Structured data is highly organized, typically in a tabular format (rows and columns) with predefined fields and types. It is often found in databases and spreadsheets, where each field has a specific type (e.g., numeric, categorical).
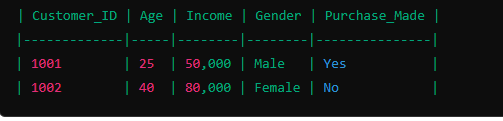
A dataset of customer information in a spreadsheet
Model Example:
Logistic Regression for classification: You can use logistic regression to predict whether a customer will make a purchase based on their Age, Income, and Gender
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
Random Forest for classification: To handle the same problem with a more complex model, you could use a random forest, which will consider various decision trees to make the classification.
Unstructured Data:
Definition: Unstructured data lacks a predefined structure or organization. This type of data includes text, images, videos, audio files, and social media posts. It doesn’t easily fit into rows and columns.
Example:
Text Data: Reviews from an e-commerce site, where each review is a free-form text:
"Great product! Highly recommend."
"The product broke after a week. Disappointing."
"Amazing service and delivery."
Image Data: A collection of labeled images of cats and dogs used in image classification.
Model Example:
Naive Bayes Classifier for text classification: You can use Naive Bayes for classifying text reviews into categories such as positive or negative sentiment.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
vectorizer = CountVectorizer()
X_train_counts = vectorizer.fit_transform(train_data)
model = MultinomialNB()
model.fit(X_train_counts, y_train)
Convolutional Neural Network (CNN) for image classification: For image data, CNNs are commonly used. They can classify whether an image contains a cat or a dog by learning patterns from the pixel data of images.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
MaxPooling2D(pool_size=(2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10)
Common Preprocessing for Unstructured Data:
Text Data: Tokenization, stemming, lemmatization, converting text to vectors (e.g., using CountVectorizer, TF-IDF, or word embeddings like Word2Vec or BERT).
Image Data: Image resizing, normalization, and data augmentation techniques (e.g., flipping, rotating, zooming) to make the images consistent in size and format for training.
Example of Transition:
Sometimes unstructured data is converted into structured data for analysis:
Text to Structured: By converting text into numerical features (e.g., using TF-IDF for text classification), unstructured text data can be represented in a structured matrix format.
Image to Structured: By extracting features from images (e.g., using CNNs or manually engineered features), images can be represented in structured formats for further analysis.
This division between structured and unstructured data helps determine which machine learning models and preprocessing techniques are most appropriate for the task.

Top comments (0)