Why we need this architecture ?
Model Construction Architecture
The Problem of naive version of the inception model or How does this architecture reduce dimensionality
Why we need this architecture ?
Building a powerful deep neural network is possible by increasing the number of layers in a network Two problems with the above approach are that increasing the number of layers of a neural network may lead to overfitting especially if you have limited labeled training data and there is an increase in the computational requirement.
Inception networks were created with the idea of increasing the capability of a deep neural network while efficiently using computational resources.
wider as well as deeper neural network required
Consider the below images of peacocks. The area of the image occupied by the peacock varies in both images, selecting the right kernel size thus becomes a difficult choice. A large kernel size is used to capture a global distribution of the image while a small kernel size is used to capture more local information.
see above image peacock wider as well deeper image required

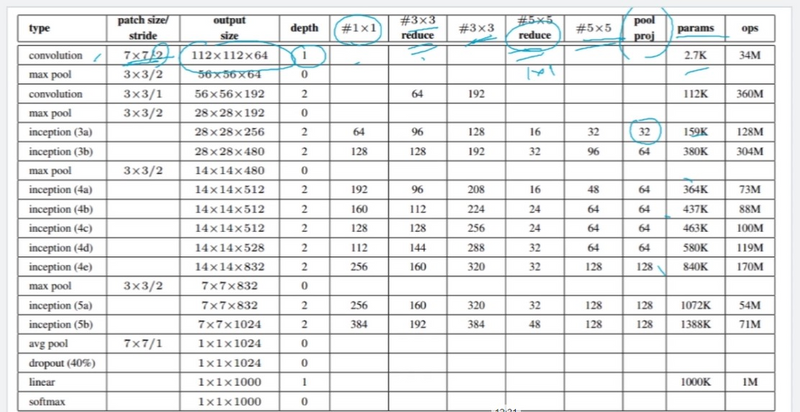
The Inception architecture, specifically Inception-v1, also known as GoogLeNet, was a breakthrough in deep learning, especially in the field of image classification. It introduced a novel approach to designing convolutional neural networks (CNNs) that aimed to improve both accuracy and efficiency. Here's an overview of the Inception architecture and why it was needed:
Inception Architecture:
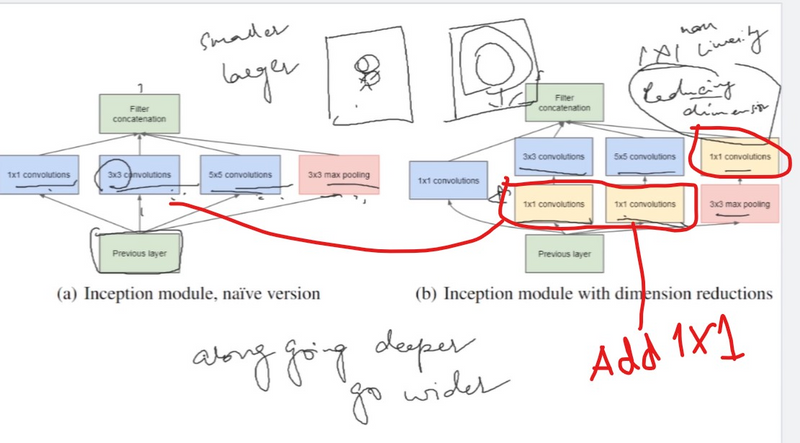
Module Design: The hallmark of the Inception architecture is its unique module design. Instead of relying solely on a stack of convolutional layers with pooling, it employs a set of parallel convolutional layers with different kernel sizes (1x1, 3x3, 5x5) and pooling operations.
Inception Modules: These modules allow the network to capture features at multiple spatial scales efficiently. By having parallel paths, the network can learn to extract features at different levels of abstraction simultaneously.
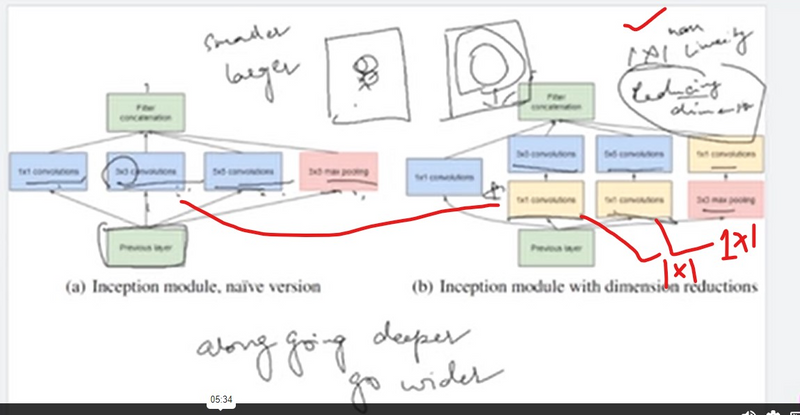
Dimensionality Reduction: Inception modules also include 1x1 convolutions before larger convolutions to reduce the dimensionality of feature maps. This helps in reducing computational complexity while retaining representational power.
Auxiliary Classifiers: Inception-v1 introduced the concept of auxiliary classifiers, which are additional classifiers inserted at intermediate layers of the network. These classifiers help in combating the vanishing gradient problem during training and provide regularization.
Global Average Pooling: Instead of using fully connected layers at the end, Inception networks typically use global average pooling, which averages the spatial dimensions of the feature maps, reducing the number of parameters and improving generalization.
Why it's Needed:
Efficiency: Inception architectures are designed to achieve high accuracy while being computationally efficient. By employing parallel paths and dimensionality reduction techniques, they can achieve better performance with fewer parameters compared to traditional CNN architectures.
Feature Representation: The Inception architecture captures features at multiple scales, allowing it to effectively handle objects of different sizes and complexities within images. This makes it suitable for tasks like image classification where objects may vary significantly in size and appearance.
Scalability: Inception architectures can be scaled up or down depending on the requirements of the task and the computational resources available. This flexibility makes them adaptable to a wide range of applications, from small-scale embedded systems to large-scale distributed environments.
State-of-the-art Performance: Inception-v1 and its subsequent iterations have consistently achieved state-of-the-art performance on benchmark datasets like ImageNet, demonstrating the effectiveness of the architecture in tackling challenging image classification tasks.
Model Construction Architecture
Consider the below images of peacocks. The area of the image occupied by the peacock varies in both images, selecting the right kernel size thus becomes a difficult choice. A large kernel size is used to capture a global distribution of the image while a small kernel size is used to capture more local information.

Inception network architecture makes it possible to use filters of multiple sizes without increasing the depth of the network. The different filters are added parallelly instead of being fully connected one after the other.
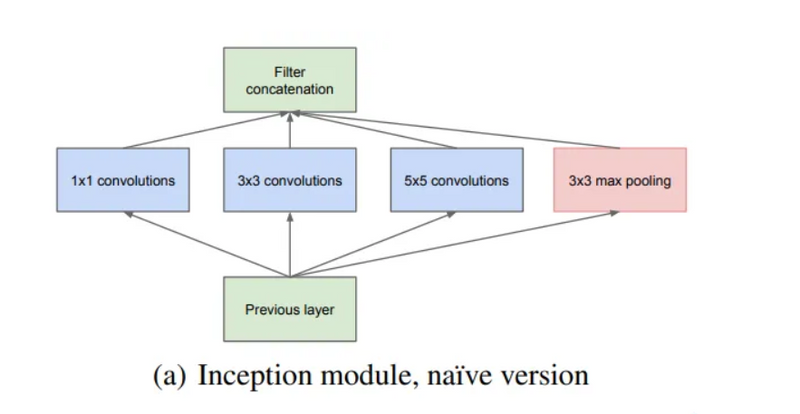
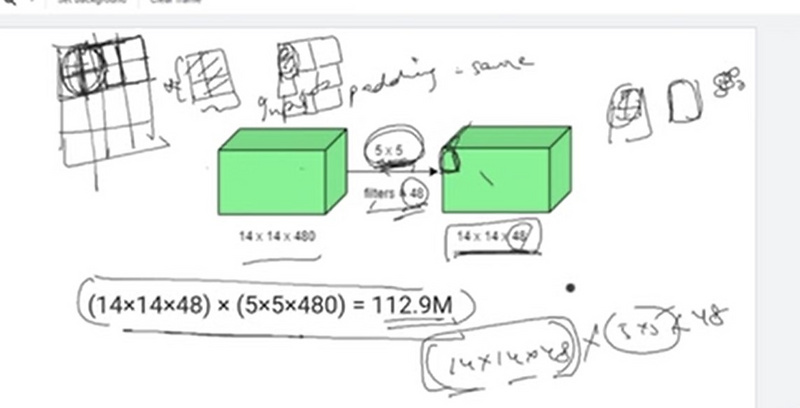
This is known as the naive version of the inception model. The problem with this model was the huge number of parameters. To mitigate the same, they came up with the below architecture.
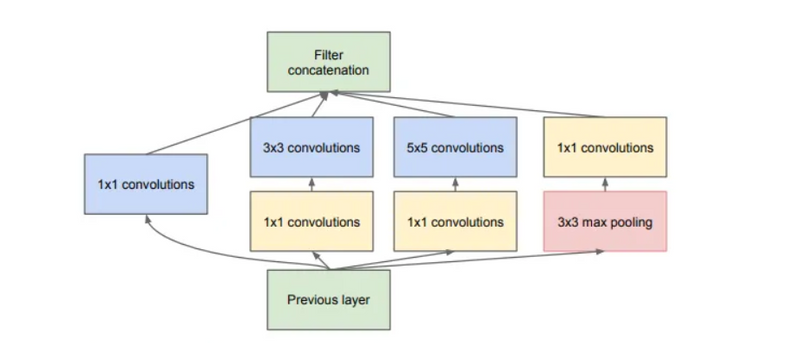
The Problem of naive version of the inception model or How does this architecture reduce dimensionality
The problem with this model was the huge number of parameters. To mitigate the same, they came up with the below architecture.
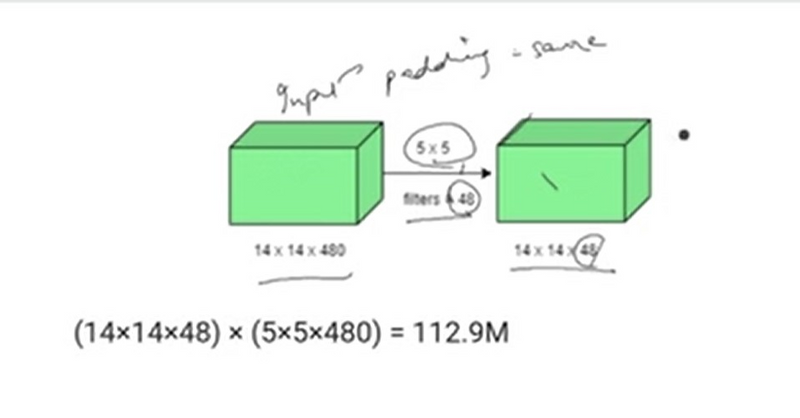
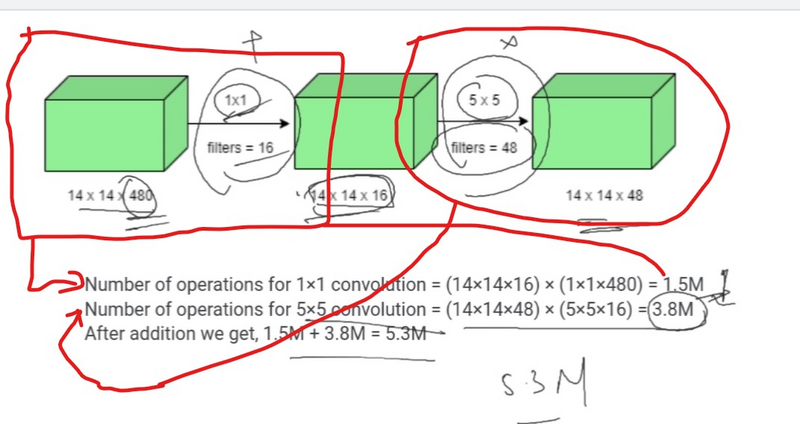
Adding a 1X1 convolution before a 5X5 convolution would reduce the number of channels of the image when it is provided as an input to the 5X5 convolution, in turn reducing the number of parameters and the computational requirement.


What is different in the Inception V3 network from the inception V1 network
?
Inception V3 is an extension of the V1 module, it uses techniques like factorizing larger convolutions to smaller convolutions (say a 5X5 convolution is factorized into two 3X3 convolutions) and asymmetric factorizations (example: factorizing a 3X3 filter into a 1X3 and 3X1 filter).

These factorizations are done with the aim of reducing the number of parameters being used at every inception module. Below is an image of the inception V3 module.

Top comments (0)