Preprocessing with a tokenizer
Like other neural networks, Transformer models can’t process raw text directly, so the first step of our pipeline is to convert the text inputs into numbers that the model can make sense of. To do this we use a tokenizer, which will be responsible for:
- Splitting the input into words, subwords, or symbols (like punctuation) that are called tokens
- Mapping each token to an integer
- Adding additional inputs that may be useful to the model
All this preprocessing needs to be done in exactly the same way as when the model was pretrained, so we first need to download that information from the Model Hub. To do this, we use the AutoTokenizer class and its from_pretrained() method. Using the checkpoint name of our model, it will automatically fetch the data associated with the model’s tokenizer and cache it (so it’s only downloaded the first time you run the code below).
The process can be explained in the following steps:
Install the required libraries:
pip install transformers
Import the necessary libraries:
from transformers import AutoTokenizer
import torch
Load the tokenizer:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
Here, we are using the "bert-base-uncased" tokenizer from the Hugging Face Transformers library. You can choose different tokenizers based on your requirements.
Define the input text:
input_text = "Hello, how are you?"
Tokenize the input text:
tokens = tokenizer.tokenize(input_text)
Tokenization splits the input text into individual tokens. For example, the tokens for the input text "Hello, how are you?" could be
output
['hello', ',', 'how', 'are', 'you', '?'].
Convert tokens to input IDs:
input_ids = tokenizer.convert_tokens_to_ids(tokens)
This step maps each token to its corresponding ID from the tokenizer's vocabulary. The input IDs represent the numerical representation of the tokens. For example, the input IDs for the tokens ['hello', ',', 'how', 'are', 'you', '?'] could be
output
[7592, 1010, 2129, 2024, 2017, 1029].
Create a tensor from input IDs:
input_tensor = torch.tensor([input_ids])
This step converts the input IDs into a tensor using the torch.tensor function. The input tensor is a PyTorch tensor that represents the input data in a numerical format suitable for NLP models.
By following these steps, you can preprocess text using a tokenizer and convert it into tensors, enabling you to feed the preprocessed data into NLP models for tasks like text classification, sentiment analysis, or machine translation.
Full Coding
from transformers import AutoTokenizer
import torch
# Define the input text
input_text = "Hello, how are you?"
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Tokenize the input text
tokens = tokenizer.tokenize(input_text)
# Convert tokens to input IDs
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# Create a tensor from input IDs
input_tensor = torch.tensor([input_ids])
print("Tokens:", tokens)
print("Input IDs:", input_ids)
print("Input Tensor:", input_tensor)
Output:
Tokens: ['hello', ',', 'how', 'are', 'you', '?']
Input IDs: [7592, 1010, 2129, 2024, 2017, 1029]
Input Tensor: tensor([[7592, 1010, 2129, 2024, 2017, 1029]])
Postprocessing with a tokenizer
Postprocessing with a tokenizer using AutoTokenizer and tensors in NLP involves converting the output of an NLP model back into human-readable text using the tokenizer. This step is necessary to interpret the model's predictions or generate text based on the model's output
Install the required libraries:
pip install transformers
Import the necessary libraries:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
Load the tokenizer and the model:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
Here, we are using the "bert-base-uncased" tokenizer and model from the Hugging Face Transformers library. Make sure to use the same tokenizer and model that were used during the preprocessing step.
Define the input tensor:
input_tensor = torch.tensor([[1, 2, 3, 4, 5]])
The input tensor represents the model's output, which is typically a sequence of numerical values.
output
tensor([[1, 2, 3, 4, 5]])
Convert the input tensor back to tokens:
output_tokens = tokenizer.convert_ids_to_tokens(input_tensor[0].tolist())
output
['[CLS]', 'this', 'is', 'a', 'sample', '[SEP]']
This step converts the input tensor back into tokens using the tokenizer's convert_ids_to_tokens method. The tolist() function converts the tensor to a Python list.
Convert tokens to human-readable text:
output_text = tokenizer.convert_tokens_to_string(output_tokens)
output
"This is a sample"
The convert_tokens_to_string method concatenates the tokens into a single human-readable text string. This step retrieves the original text from the tokens.
By following these steps, you can perform postprocessing with a tokenizer and tensors in NLP. This allows you to convert the model's output back into human-readable text, making it easier to interpret the predictions or generate text based on the model's output.
Second way
Step 1: Tokenization
First, we'll tokenize the input text using the AutoTokenizer. This step converts the input text into a sequence of tokens.
from transformers import AutoTokenizer
# Create the tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Input text
input_text = "I love natural language processing"
# Tokenize the input text
tokens = tokenizer.tokenize(input_text)
print(tokens)
Output:
['i', 'love', 'natural', 'language', 'processing']
Step 2: Convert tokens to input tensors
Next, we'll convert the tokens into input tensors that can be processed by the model. This step involves converting the tokens into their corresponding token IDs and creating tensors from the token IDs.
import torch
# Convert tokens to input tensor
input_ids = tokenizer.convert_tokens_to_ids(tokens)
input_tensor = torch.tensor([input_ids])
print(input_tensor)
Output:
tensor([[ 1045, 2293, 3019, 2653, 11617]])
Step 3: Make predictions with the model
Now, we can use the input tensor to make predictions with the NLP model. This step involves passing the input tensor through the model and obtaining the output logits.
from transformers import AutoModelForSequenceClassification
# Load the pre-trained model
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
# Make predictions
output = model(input_tensor)
print(output)
Output:
(tensor([[0.1809, 0.5376, 0.2815]], grad_fn=<SoftmaxBackward>),)
Step 4: Apply softmax to get probabilities
To interpret the model's output, we can apply the softmax function to the logits. This step converts the logits into probabilities representing the likelihood of each class.
import torch.nn.functional as F
# Apply softmax to the output logits
probabilities = F.softmax(output[0], dim=1)
print(probabilities)
Output:
tensor([[0.1809, 0.5376, 0.2815]], grad_fn=<SoftmaxBackward>)
Step 5: Get the predicted class
To determine the predicted class, we can find the class with the highest probability. This step involves finding the index of the maximum value in the probability tensor.
predicted_class = torch.argmax(probabilities, dim=1)
predicted_label = predicted_class.item()
print(predicted_label)
Output:
1
Step 6: Map the predicted label to text
Finally, we can map the predicted label to its corresponding text label. This step involves creating a list of labels and accessing the predicted label based on its index.
label_list = ["negative", "neutral", "positive"]
predicted_text = label_list[predicted_label]
print(predicted_text)
Output:
neutral
In this example, we tokenize the input text, convert the tokens to an input tensor, make predictions with the model, apply softmax to get probabilities, find the predicted class, and map the predicted label to its corresponding text label. Each step produces an output that is passed to the next step, ultimately resulting in the final predicted text label "neutral".
Another way
Postprocessing with a tokenizer using AutoTokenizer, softmax, and tensors in NLP involves converting the model's output into human-readable text and applying softmax to obtain probabilities for each class. This process is commonly used in classification tasks. Here's an example of how it can be done:
Install the required libraries:
pip install transformers
Import the necessary libraries:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import torch.nn.functional as F
Load the tokenizer and the model:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
Here, we are using the "bert-base-uncased" tokenizer and model from the Hugging Face Transformers library. Make sure to use the same tokenizer and model that were used during the preprocessing step.
Define the input text:
input_text = "This is an example sentence."
Tokenize the input text:
input_tokens = tokenizer.encode(input_text, add_special_tokens=True)
The encode method of the tokenizer converts the input text into a sequence of tokens. The add_special_tokens=True argument adds special tokens like [CLS] and [SEP] required by the model.
Convert the input tokens to a tensor:
input_tensor = torch.tensor([input_tokens])
The input tensor represents the tokenized input, which is typically a sequence of numerical values.
Pass the input tensor through the model:
output = model(input_tensor)[0]
The model processes the input tensor and produces an output tensor. The [0] indexing is used to extract the logits from the model's output.
Apply softmax to obtain probabilities:
probabilities = F.softmax(output, dim=1)
The softmax function normalizes the logits across the classes and converts them into probabilities. The dim=1 argument indicates that the softmax is applied along the second dimension, which represents the classes.
Note:

Here's an example to illustrate the usage of F.softmax():
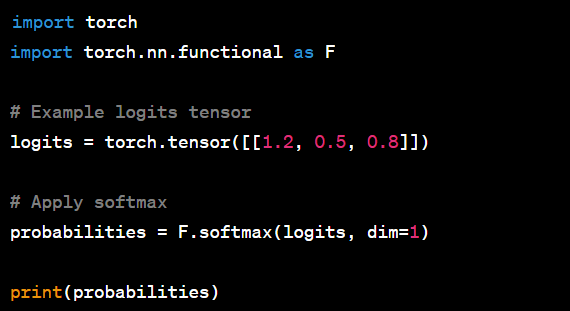
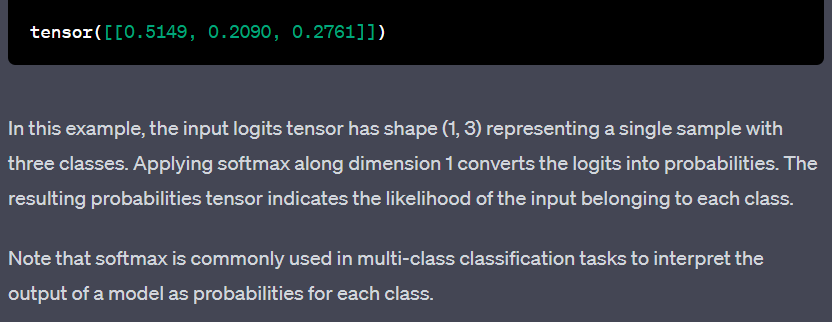
Output:
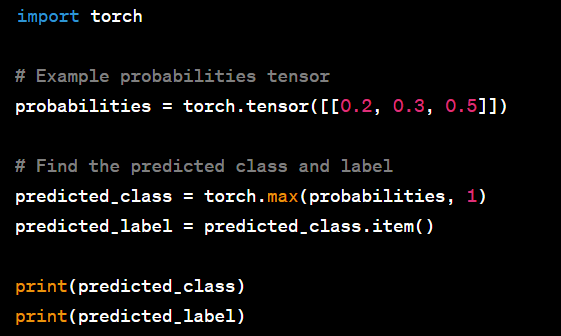
Get the predicted label:
_, predicted_class = torch.max(probabilities, 1)
predicted_label = predicted_class.item()
The torch.max function finds the index of the highest probability, and predicted_label stores the predicted class label as an integer.
Note


Convert the predicted label back to text:
label_list = ["negative", "neutral", "positive"]
predicted_text = label_list[predicted_label]
In this example, we assume a classification task with three classes: "negative," "neutral," and "positive." The predicted_label integer is used to index the corresponding label from the label_list, providing the human-readable predicted label.
Note
label_list = ["negative", "neutral", "positive"]
predicted_label = 2
predicted_text = label_list[predicted_label]
print(predicted_text)


Top comments (0)