Random Forest is a popular machine learning algorithm used for both classification and regression tasks. It's an ensemble learning method that combines the predictions of multiple individual decision trees to produce a more accurate and robust prediction. The "forest" in Random Forest refers to a collection of decision trees.
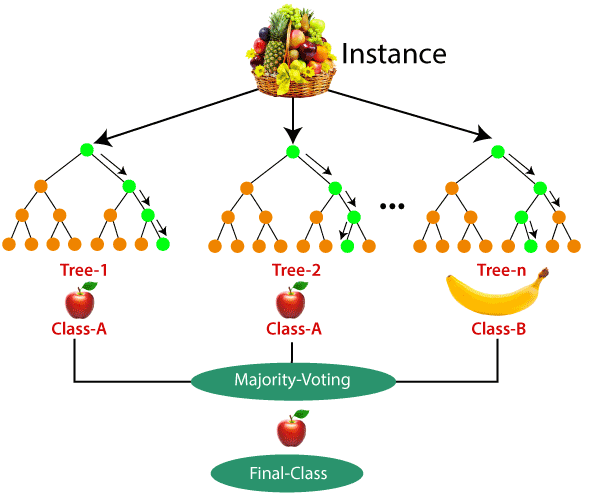
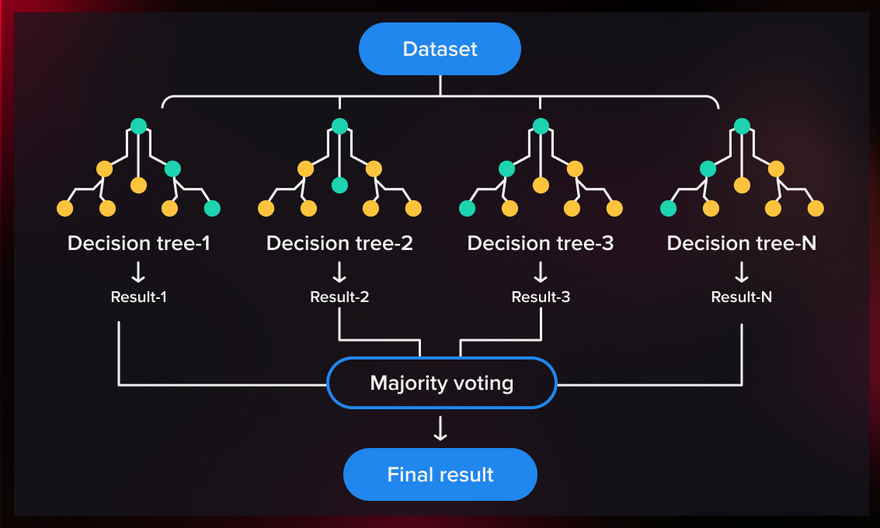
Here's how the Random Forest classifier works with an example:
Example: Predicting Iris Flower Species
In this example, we'll use the well-known Iris dataset to predict the species of iris flowers using the Random Forest classifier.
Import Libraries:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
Load and Prepare Data:
# Load the Iris dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train the Random Forest Classifier:
# Initialize the Random Forest classifier
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the classifier on the training data
rf_classifier.fit(X_train, y_train)
Make Predictions:
# Make predictions on the test data
y_pred = rf_classifier.predict(X_test)
Evaluate the Model:
# Calculate accuracy score
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
In this example:
We load the Iris dataset and split it into training and testing sets
.
- We create a Random Forest classifier with 100 decision trees (n_estimators=100).
- We train the classifier on the training data.
- We make predictions on the test data.
- We evaluate the model's accuracy using the accuracy score . The Random Forest algorithm works as follows:
It creates multiple decision trees, each trained on a different subset of the data and with a random selection of features.
For classification tasks, each decision tree "votes" for a class, and the class with the most votes becomes the final prediction. For regression tasks, the predictions from all trees are averaged to produce the final prediction.
Random Forest reduces overfitting by aggregating the predictions of multiple trees, which helps improve generalization and accuracy.
Random Forest's key advantages include handling non-linear relationships, robustness to outliers, and the ability to handle high-dimensional data. It's a powerful algorithm widely used in various applications, from finance to healthcare and beyond.
When to use
Random Forest classifier is commonly used in machine learning when you have a classification task where you want to predict the class or category of an instance based on its features. Here's an example of how to use the Random Forest classifier in a real-world machine learning scenario:
Example: Predicting Customer Churn
Suppose you are working for a telecommunications company and you want to predict whether a customer will churn (cancel their subscription) based on various customer attributes. You have a dataset with features like customer's contract duration, monthly charges, total charges, etc.
Import Libraries:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
Load and Prepare Data:
# Load the dataset
data = pd.read_csv("telecom_churn.csv")
# Split data into features (X) and target (y)
X = data.drop("Churn", axis=1)
y = data["Churn"]
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train the Random Forest Classifier:
# Initialize the Random Forest classifier
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the classifier on the training data
rf_classifier.fit(X_train, y_train)
Make Predictions:
# Make predictions on the test data
y_pred = rf_classifier.predict(X_test)
Evaluate the Model:
# Calculate accuracy and other metrics
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:\n", classification_rep)
In this example:
- You load the dataset containing customer attributes and churn information.
- You split the data into features (X) and the target variable (y).
- You create a Random Forest classifier with 100 decision trees (n_estimators=100).
- You train the classifier on the training data.
- You make predictions on the test data.
- You evaluate the model's accuracy using the accuracy score and provide a detailed classification report . The Random Forest classifier is well-suited for this scenario because it can handle a mix of different types of features, capture non-linear relationships, and provide insights into feature importance, which can help in understanding which features are contributing to customer churn.
Remember that this is a simplified example, and real-world scenarios often involve additional data preprocessing, hyperparameter tuning, and more in-depth evaluation.

Top comments (0)