regression score( R adjusted score)
In machine learning, the regression score, also known as the coefficient of determination or R-squared, is used to evaluate the performance and goodness-of-fit of a regression model. It provides a measure of how well the model fits the observed data points and explains the variability of the dependent variable.
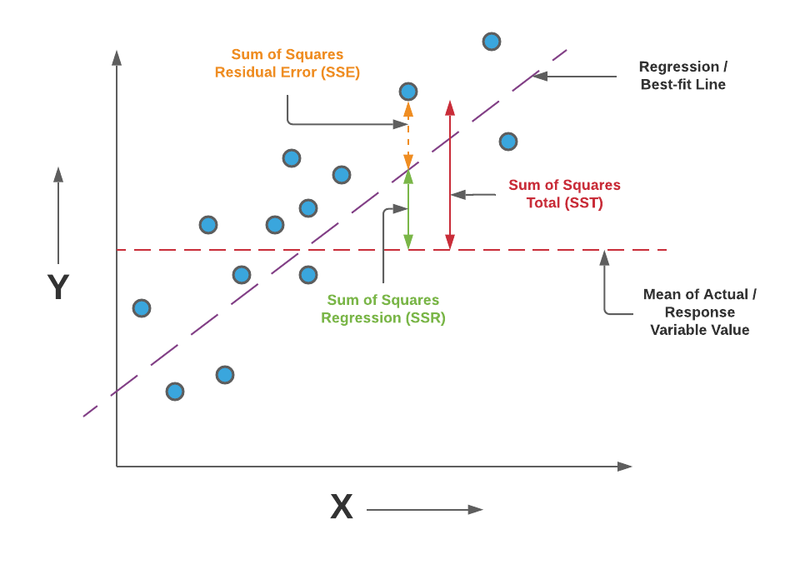
There are several reasons why the regression score is used in machine learning:
Model Evaluation: The regression score serves as a metric to assess the performance of a regression model. It provides a quantitative measure of how well the model predicts the dependent variable based on the independent variables. Higher R-squared values indicate better model performance, while lower values suggest poor fit.
Model Comparison: The regression score allows for the comparison of different regression models. By comparing the R-squared values of multiple models, one can determine which model performs better in terms of capturing the relationships between variables and explaining the variance in the data.
Feature Selection: R-squared is often used in feature selection processes. It helps identify the most relevant features that contribute significantly to the prediction of the dependent variable. Features with higher impact on the R-squared value indicate their importance in the model, aiding in the selection of the most informative variables.
Overfitting Detection: R-squared helps in detecting overfitting, which occurs when a model performs well on the training data but fails to generalize to new, unseen data. A high R-squared value on the training data, but a significantly lower value on the test data, indicates overfitting. Monitoring the R-squared on both the training and test data helps ensure a well-fitted and generalizable model.
Interpretability: The regression score provides a simple and interpretable measure of model performance. It represents the proportion of the variance in the dependent variable that is explained by the independent variables. This allows for a straightforward understanding of how well the model captures the relationship between the variables and the predictive power of the model.
Decision Making: R-squared plays a crucial role in decision-making processes. It assists in determining the usefulness and reliability of a regression model, which can guide decision-makers in choosing appropriate models for prediction, forecasting, or understanding the relationships between variables.
It's important to note that the R-squared value alone may not provide a complete picture of model performance. It should be considered along with other evaluation metrics, such as mean squared error (MSE), root mean squared error (RMSE), or cross-validation scores, to obtain a comprehensive assessment of the model's performance and potential limitations.
Overall, the regression score is a valuable tool in machine learning for assessing model performance, comparing models, identifying important features, detecting overfitting, and aiding decision-making processes. It provides a straightforward measure of how well the model captures the relationship between variables and explains the observed data.
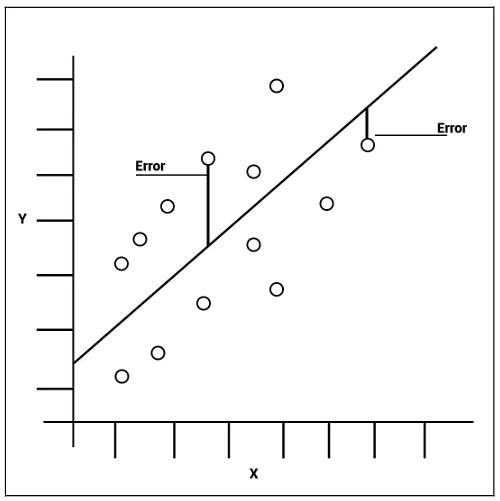
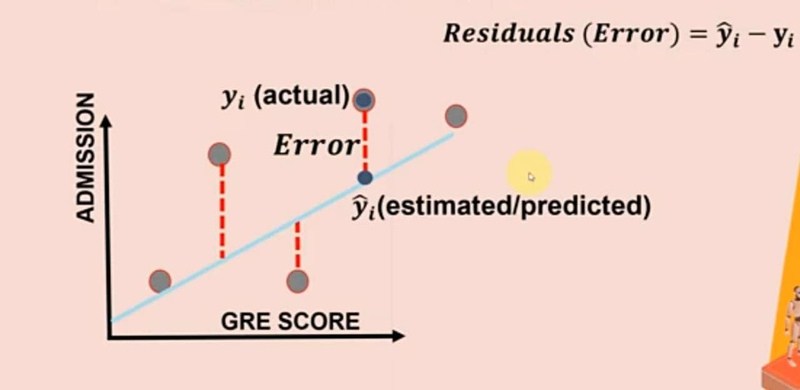
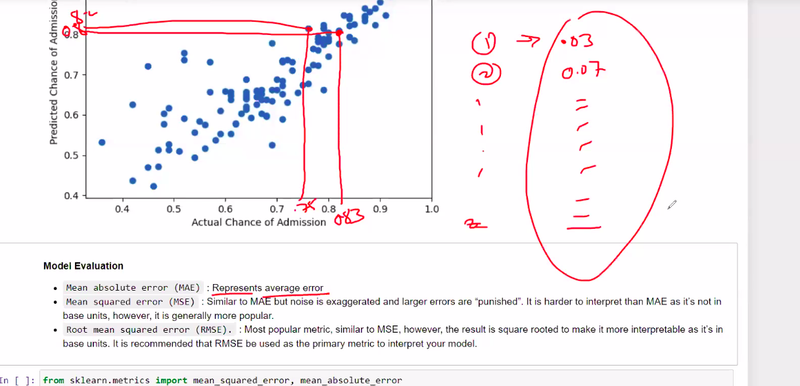
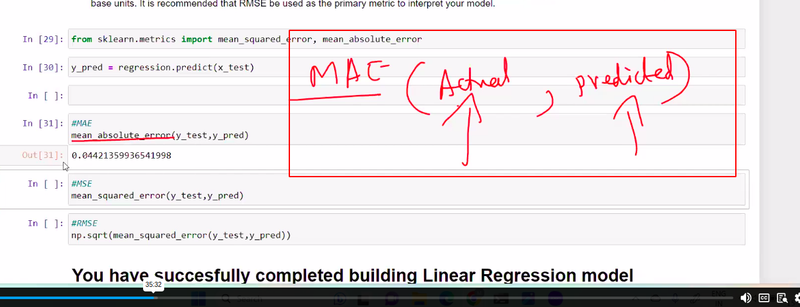
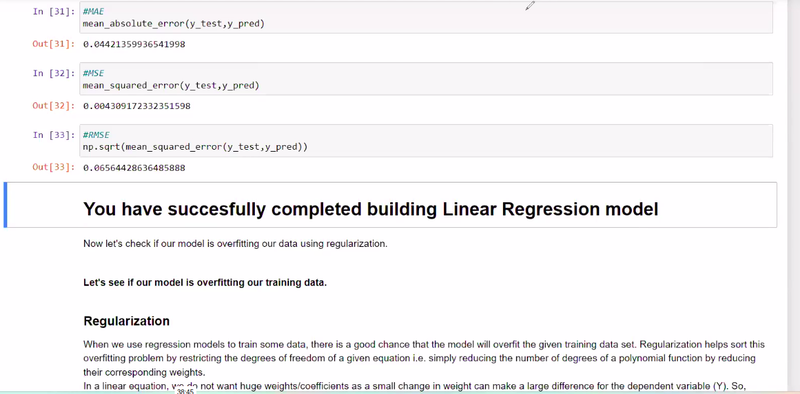
Mean Squared Error (MSE) and Mean Absolute Error (MAE) are both widely used evaluation metrics in machine learning to measure the performance of regression models. They quantify the difference between predicted values and actual values, but they differ in how they calculate and interpret the errors.
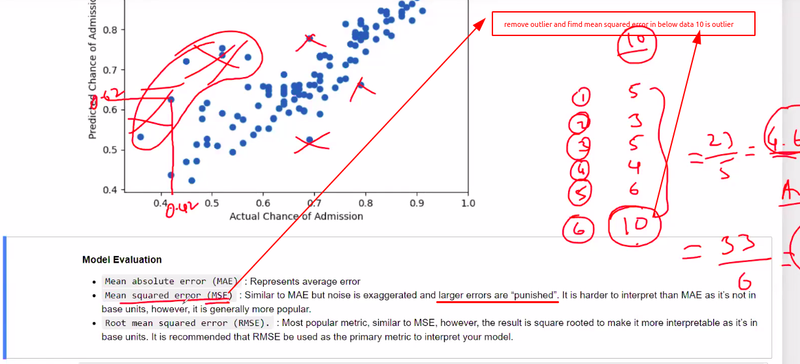
larger error are punished
Mean Squared Error (MSE):
MSE is calculated by taking the average of the squared differences between the predicted values and the actual values. It measures the average squared distance between the predicted and actual values. The formula for MSE is as follows:
MSE = (1/n) * Σ(y_true - y_pred)^2
where:
n is the number of samples or data points.
y_true represents the actual or observed values.
y_pred represents the predicted values.
The squared differences in MSE amplify the impact of larger errors, making it more sensitive to outliers. MSE penalizes larger errors more heavily and tends to give higher weightage to extreme values.
Mean Absolute Error (MAE):
MAE is calculated by taking the average of the absolute differences between the predicted values and the actual values. It measures the average absolute distance between the predicted and actual values. The formula for MAE is as follows:
larger error are not punished
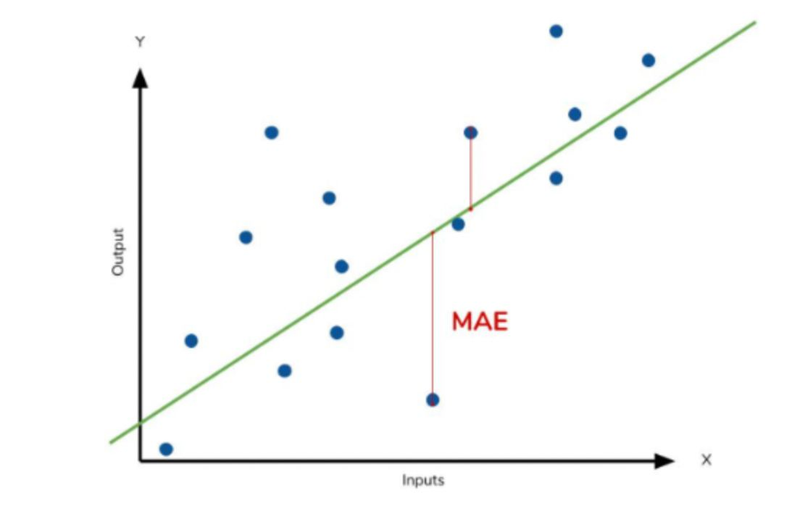
MAE = (1/n) * Σ|y_true - y_pred|
where:
n is the number of samples or data points.
y_true represents the actual or observed values.
y_pred represents the predicted values.
Unlike MSE, MAE does not square the errors. It treats all errors equally and does not emphasize outliers or extreme values. MAE is robust to outliers and provides a more balanced view of the errors in the model.
Differences and Use Cases:
Magnitude of Errors: MSE gives higher weightage to larger errors due to the squared term. It is more sensitive to outliers or extreme values. On the other hand, MAE treats all errors equally and is more robust to outliers.
Interpretability: MSE is not directly interpretable because it is in squared units (e.g., squared error). MAE is more interpretable as it represents the average absolute difference in the original unit of the target variable.
Application: MSE is commonly used when larger errors need to be penalized more, such as in situations where precise predictions are critical. It is widely used in applications like financial modeling, where even small errors can have significant consequences. MAE is often used when equal weighting of errors is desired, or when outliers are present and need to be given less influence.
Both MSE and MAE have their strengths and weaknesses, and the choice between them depends on the specific problem, data characteristics, and the desired emphasis on different types of errors.
Question
Regression score evalutes.......
Regression score measures/metric of.....
regression scores serves as---------
regession score determine how model predicts based on...........
task of feature selection
overfitting performs well on ------------- but fails on ----------
In overfitting test value is lower or higher ...........
r score plays crucial role on .........
larger error punished on MAE or MSE
MAE predicts difference b/w ------

Top comments (0)