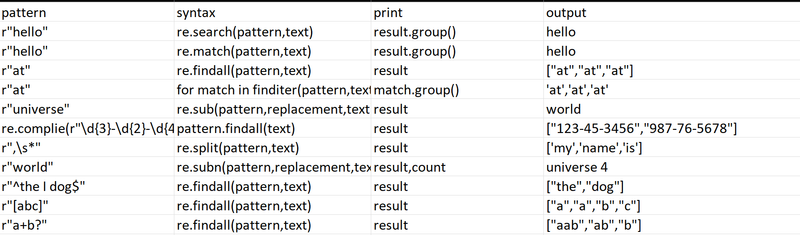
Regular expressions, often abbreviated as regex or regexp, are powerful tools for pattern matching and text manipulation. Below are some commonly used regex functions with examples in Python, though regex functionality is available in many programming languages and text editors.
re.search(pattern, text):
re.match(pattern, text)
re.findall(pattern, text)
re.finditer(pattern, text)
re.sub(pattern, replacement, text)
re.compile(pattern)
re.split(pattern, text)
re.subn(pattern, replacement, text)
Anchors (^ and $)
Character Classes ([...])
Quantifiers (*, +, ?):
Difference between search and match
Difference between findall and finditer
Difference between re.findall and re.compile(pattern)
re.search(pattern, text):
Searches for the first occurrence of the pattern in the text.
searches for the first occurrence of the pattern anywhere in the text
Example:
import re
text = "Hello, World!"
pattern = r"World"
result = re.search(pattern, text)
print(result.group()) # Output: World
re.match(pattern, text):
Searches for the pattern at the beginning of the text.
Example:
import re
text = "Hello, World!"
pattern = r"Hello"
result = re.match(pattern, text)
print(result.group()) # Output: Hello
re.findall(pattern, text):
Finds all non-overlapping occurrences of the pattern in the text and returns them as a list.
Example:
python
text = "The cat and the hat sat on the mat."
pattern = r"at"
result = re.findall(pattern, text)
print(result) # Output: ['at', 'at', 'at', 'at']
re.finditer(pattern, text):
Finds all non-overlapping occurrences of the pattern in the text and returns an iterator of match objects.
Example:
import re
text = "The cat and the hat sat on the mat."
pattern = r"at"
for match in re.finditer(pattern, text):
print(match.group()) # Output: 'at', 'at', 'at', 'at'
re.sub(pattern, replacement, text):
Replaces all occurrences of the pattern in the text with the replacement string.
Example:
import re
text = "Hello, World!"
pattern = r"World"
replacement = "Universe"
result = re.sub(pattern, replacement, text)
print(result) # Output: Hello, Universe!
re.compile(pattern):
Compiles a regular expression pattern into a regex object, which can be reused for matching multiple texts.
Example:
import re
pattern = re.compile(r"\d{3}-\d{2}-\d{4}")
text = "My SSN is 123-45-6789, and yours is 987-65-4321."
result = pattern.findall(text)
print(result) # Output: ['123-45-6789', '987-65-4321']
These are just a few common regex functions and methods. Regular expressions can be quite powerful and flexible for complex pattern matching and text manipulation tasks. However, they can also be complex and challenging to read and write, so it's important to understand the basics and practice regularly.
re.split(pattern, text):
Splits the text into a list of substrings based on the occurrences of the pattern.
Example:
import re
text = "apple,banana, cherry, date"
pattern = r",\s*"
result = re.split(pattern, text)
print(result) # Output: ['apple', 'banana', 'cherry', 'date']
re.subn(pattern, replacement, text):
Similar to re.sub(), but also returns the number of substitutions made.
Example:
import re
text = "Hello, World! World is great. World, hello World."
pattern = r"World"
replacement = "Universe"
result, count = re.subn(pattern, replacement, text)
print(result) # Output: Hello, Universe! Universe is great. Universe, hello Universe.
print(count) # Output: 4
re.escape(text):
Escapes special characters in a given text, making it safe to use as a literal in a regex pattern.
Example:
import re
text = "(1+1)=2"
pattern = re.escape(text)
result = re.search(pattern, "The equation (1+1)=2 is correct.")
print(result.group()) # Output: (1+1)=2
Anchors (^ and $):
^ matches the start of a line, and $ matches the end of a line.
Example:
import re
text = "The quick brown fox\nJumps over the lazy dog"
pattern = r"^The|dog$"
result = re.findall(pattern, text, re.MULTILINE)
print(result) # Output: ['The', 'dog']
Character Classes ([...]):
[...] matches any character from within the square brackets.
Example:
import re
text = "apple, banana, cherry"
pattern = r"[abc]"
result = re.findall(pattern, text)
print(result) # Output: ['a', 'a', 'b', 'a', 'a', 'c']
Quantifiers (*, +, ?):
- matches zero or more occurrences, + matches one or more, and ? matches zero or one. Example:
import re
text = "aaab, ab, b"
pattern = r"a+b?"
result = re.findall(pattern, text)
print(result) # Output: ['aab', 'ab', 'ab']
These additional examples demonstrate various regex functions and concepts for pattern matching and manipulation. Regular expressions are a versatile tool for text processing tasks.
Difference between findall and finditer
re.findall() and re.finditer() are two functions in Python's re module used for finding non-overlapping matches of a regular expression pattern in a given text. They have some key differences:
Return Type:
re.findall(pattern, text): Returns a list of all non-overlapping matches as strings.
re.finditer(pattern, text): Returns an iterator of match objects.
Data Structure:
re.findall() returns a list of strings that match the pattern.
re.finditer() returns an iterator of match objects, which contain information about the matched text, its position, and more.
Memory Usage:
re.findall() returns all matches as a list, which can consume more memory if there are many matches.
re.finditer() returns an iterator, so it consumes memory efficiently. It's preferred when dealing with large texts or many matches.
Here are examples to illustrate the differences:
Using re.findall():
import re
text = "The cat and the hat sat on the mat."
pattern = r"\b\w{3}\b" # Matches three-letter words
result = re.findall(pattern, text)
print(result)
# Output: ['cat', 'the', 'hat', 'sat', 'the', 'mat']
Using re.finditer():
import re
text = "The cat and the hat sat on the mat."
pattern = r"\b\w{3}\b" # Matches three-letter words
result_iterator = re.finditer(pattern, text)
for match in result_iterator:
print(match.group())
Output:
# cat
# hat
# sat
# the
# mat
In the re.findall() example, all matches are returned as a list of strings. In the re.finditer() example, an iterator of match objects is used, which allows you to access individual match objects and their properties.
Use re.findall() when you want a simple list of matched strings, and use re.finditer() when you need more detailed information about each match and want to conserve memory, especially when dealing with large texts or many matches.
=============================================================
Difference between re.findall(pattern, text) and re.compile(pattern)
re.findall(pattern, text):
re.findall() is a function that searches for all non-overlapping occurrences of a regular expression pattern within a given text.
It returns a list of strings representing all the matched substrings in the text.
This function is used directly to perform one-time pattern matching and retrieve all matches in a text.
Example:
import re
text = "The cat and the hat sat on the mat."
pattern = r"\b\w{3}\b" # Matches three-letter words
result = re.findall(pattern, text)
print(result)
# Output: ['cat', 'the', 'hat', 'sat', 'the', 'mat']
re.compile(pattern):
re.compile() is a function that compiles a regular expression pattern into a regex object.
The resulting regex object can be stored and reused for multiple pattern matching operations.
It is helpful when you want to perform the same pattern matching multiple times, as it can improve code readability and performance.
Example:
import re
text = "The cat and the hat sat on the mat."
pattern = r"\b\w{3}\b" # Matches three-letter words
compiled_pattern = re.compile(pattern)
result = compiled_pattern.findall(text)
print(result)
# Output: ['cat', 'the', 'hat', 'sat', 'the', 'mat']
In summary:
re.findall(pattern, text) is a one-time pattern matching function that directly returns a list of matched strings in the given text.
re.compile(pattern) compiles the pattern into a regex object that can be reused for multiple pattern matching operations. It improves code efficiency and readability when you need to apply the same pattern multiple times.
The choice between these two depends on your specific use case. If you only need to perform a single pattern matching operation, re.findall() is straightforward. If you plan to reuse the pattern multiple times, it's more efficient to compile it with re.compile() to avoid unnecessary recompilation of the same pattern.

Top comments (0)