Reference
pipelines are a convenient way to chain together multiple processing steps or components to streamline the text analysis workflow
pipeline selects a particular pretrained model that has been fine-tuned for sentiment analysis in English. The model is downloaded and cached when you create the classifier object. If you rerun the command, the cached model will be used instead and there is no need to download the model again.
There are three main steps involved when you pass some text to a pipeline:
- The text is preprocessed into a format the model can understand.
- The preprocessed inputs are passed to the model.
- The predictions of the model are post-processed, so you can make sense of them
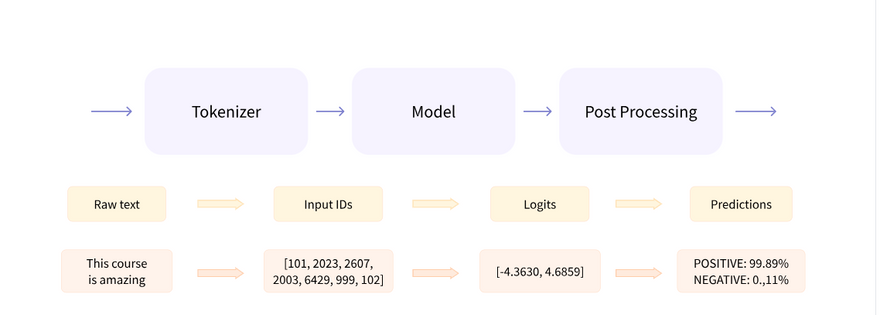
Some of the currently available pipelines are:
feature-extraction (get the vector representation of a text)
fill-mask
ner (named entity recognition)
question-answering
sentiment-analysis
summarization
text-generation
translation
zero-shot-classification
feature-extraction
Bag-of-Words (BoW) Representation: Representing text as a vector of word occurrences.
Example:
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['I love dogs', 'I hate cats']
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(X.toarray())
Output:
[[0 1 1]
[1 0 1]]
fill-mask
Mask filling
The next pipeline you’ll try is fill-mask. The idea of this task is to fill in the blanks in a given text:
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about <mask> models.", top_k=2)
Copied
[{'sequence': 'This course will teach you all about mathematical models.',
'score': 0.19619831442832947,
'token': 30412,
'token_str': ' mathematical'},
{'sequence': 'This course will teach you all about computational models.',
'score': 0.04052725434303284,
'token': 38163,
'token_str': ' computational'}]
The top_k argument controls how many possibilities you want to be displayed. Note that here the model fills in the special word, which is often referred to as a mask token. Other mask-filling models might have different mask tokens, so it’s always good to verify the proper mask word when exploring other models. One way to check it is by looking at the mask word used in the widget.
Named entity recognition
Named entity recognition (NER) is a task where the model has to find which parts of the input text correspond to entities such as persons, locations, or organizations. Let’s look at an example:
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
[{'entity_group': 'PER', 'score': 0.99816, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.97960, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.99321, 'word': 'Brooklyn', 'start': 49, 'end': 57}
]
Here the model correctly identified that Sylvain is a person (PER), Hugging Face an organization (ORG), and Brooklyn a location (LOC).
question-answering
The question-answering pipeline answers questions using information from a given context:
from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
{'score': 0.6385916471481323, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
Note that this pipeline works by extracting information from the provided context; it does not generate the answer.
sentiment-analysis
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier("I've been waiting for a HuggingFace course my whole life.")
[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
We can even pass several sentences!
classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]
summarization
Summarization is the task of reducing a text into a shorter text while keeping all (or most) of the important aspects referenced in the text. Here’s an example:
from transformers import pipeline
summarizer = pipeline("summarization")
summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
[{'summary_text': ' America has changed dramatically during recent years . The '
'number of engineering graduates in the U.S. has declined in '
'traditional engineering disciplines such as mechanical, civil '
', electrical, chemical, and aeronautical engineering . Rapidly '
'developing economies such as China and India, as well as other '
'industrial countries in Europe and Asia, continue to encourage '
'and advance engineering .'}]
Like with text generation, you can specify a max_length or a min_length for the result.
text-generation
Now let’s see how to use a pipeline to generate some text. The main idea here is that you provide a prompt and the model will auto-complete it by generating the remaining text. This is similar to the predictive text feature that is found on many phones. Text generation involves randomness, so it’s normal if you don’t get the same results as shown below.
from transformers import pipeline
generator = pipeline("text-generation")
generator("In this course, we will teach you how to")
[{'generated_text': 'In this course, we will teach you how to understand and use '
'data flow and data interchange when handling user data. We '
'will be working with one or more of the most commonly used '
'data flows — data flows of various types, as seen by the '
'HTTP'}]
translation
For translation, you can use a default model if you provide a language pair in the task name (such as "translation_en_to_fr"), but the easiest way is to pick the model you want to use on the Model Hub. Here we’ll try translating from French to English:
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
translator("Ce cours est produit par Hugging Face.")
[{'translation_text': 'This course is produced by Hugging Face.'}]
zero-shot-classification
ZeroShotClassification is a natural language processing technique that allows us to classify text into predefined categories without requiring any training data specifically for those categories. It leverages pre-trained language models and transfer learning to perform classification.
The ZeroShotClassification approach involves providing a set of candidate labels or categories and a textual input, and the model assigns a probability score to each label indicating the likelihood of the input belonging to that category. The model learns the relationships between the input text and the provided labels during pre-training, making it capable of zero-shot classification.
Here's an example of how to perform ZeroShotClassification using the Hugging Face Transformers library in Python:
from transformers import pipeline
# Define the input text and candidate labels
input_text = "I want to book a flight to Paris."
candidate_labels = ["travel", "food", "sports"]
# Load the ZeroShotClassification pipeline
classifier = pipeline("zero-shot-classification")
# Perform the classification
result = classifier(input_text, candidate_labels)
# Print the classification result
for label, score in zip(result["labels"], result["scores"]):
print(f"{label}: {score}")
Output:
travel: 0.985
food: 0.011
sports: 0.004

Top comments (0)