Why overfitting occurs?
Technique to avoid overfitting in cnn
How batch normalization avoid overfitting with example in CNN
How dropout is used to avoid overfitting with example in CNN
How weight initializor avoid overfitting with example in CNN
How Early Stopping avoid overfitting with example in CNN
How weight initializor avoid overfitting with example in CN
Why overfitting occurs
Overfitting is a common issue in Convolutional Neural Networks (CNNs) as well as in other machine learning models. Overfitting occurs when a model learns not only the underlying patterns in the training data but also noise and specific characteristics of that dataset that do not generalize well to new, unseen data. Here are some reasons why overfitting may occur in CNNs:
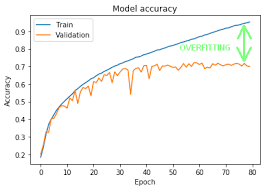

Model Complexity:
CNNs, especially deep ones with a large number of layers and parameters, have the capacity to memorize intricate details in the training data. If the model is too complex for the given dataset, it may capture noise and idiosyncrasies, leading to overfitting.
Insufficient Data:
CNNs require a substantial amount of diverse and representative data to learn generalizable features. When the dataset is small or lacks diversity, the model might memorize the training examples, making it more prone to overfitting.
Lack of Data Augmentation:
Data augmentation is a technique where the training data is artificially expanded by applying transformations (e.g., rotations, flips, zooms) to generate new examples. Without data augmentation, the model may not see enough variations in the data, making it susceptible to overfitting.
Too Many Parameters:
If the CNN has too many parameters relative to the size of the dataset, it can learn to fit the noise in the training data rather than capturing meaningful patterns. Regularization techniques like dropout or weight decay can help mitigate this.
Training for Too Many Epochs:
Continuing training for too many epochs can lead to overfitting. The model may start to memorize the training data rather than learning general patterns. Monitoring performance on a validation set and using early stopping can help prevent this.
Improper Validation Split:
If the validation set is not representative of the data the model will encounter in the real world, it may not provide a reliable indication of generalization performance. A poorly chosen validation set can lead to overfitting.
Leakage of Information:
Information leakage occurs when aspects of the validation or test set are inadvertently used during training. For example, if the mean or standard deviation of the input features is calculated using the entire dataset instead of just the training set, it can lead to overfitting.
Complexity of the Task:
If the task is inherently complex or the dataset is noisy, there is a higher risk of overfitting. Complex tasks may require more sophisticated architectures, regularization techniques, or ensemble methods to generalize well.
High Learning Rate:
Using a learning rate that is too high can cause the model to oscillate or diverge instead of converging to a minimum. This instability can lead to overfitting as the model fits the noise in the training data.
Lack of Regularization:
Regularization techniques, such as dropout or L2 regularization, help prevent overfitting by adding constraints to the model parameters. If these regularization techniques are not employed, the model may become overly complex and overfit the training data.
To address overfitting, it's important to experiment with regularization techniques, increase the diversity and size of the dataset, use proper validation strategies, and monitor performance metrics on both training and validation sets. Regularization techniques, early stopping, and data augmentation are common strategies to mitigate overfitting in CNNs.
Technique to avoid overfitting in cnn
Avoiding overfitting in Convolutional Neural Networks (CNNs) is crucial for building models that generalize well to new, unseen data. Here are several techniques commonly used to mitigate overfitting in CNNs:
Data Augmentation:
Augmenting the training dataset by applying random transformations to the input images (e.g., rotations, flips, zooms) creates new examples, helping the model generalize better to variations in the data.
Dropout:
Dropout is a regularization technique where, during training, randomly selected neurons are ignored, or "dropped out," on each forward pass. This helps prevent the model from relying too heavily on specific neurons and enhances generalization.
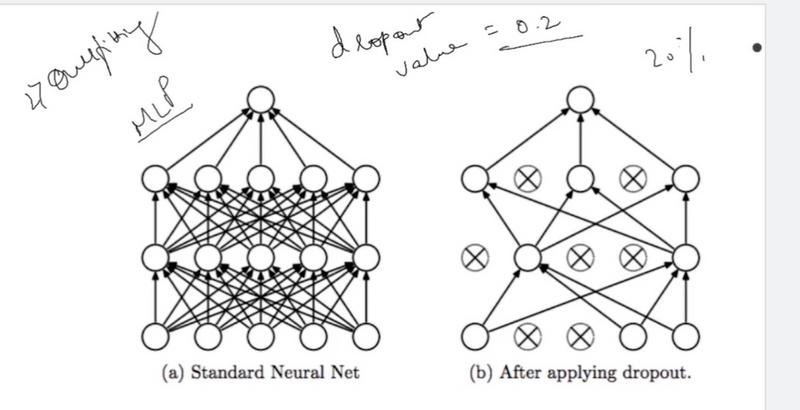
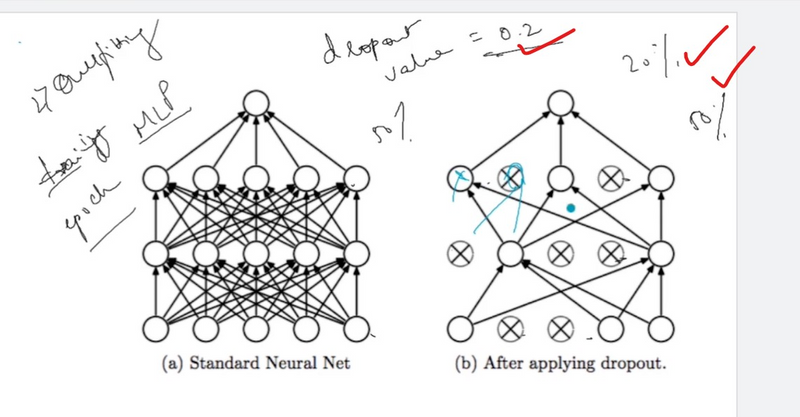

Weight Regularization (L1 and L2):
Adding regularization terms to the loss function penalizes large weights. L1 regularization adds the absolute values of the weights to the loss, and L2 regularization adds the squared values. This discourages the model from fitting noise in the training data.
Early Stopping:
Monitor the performance on a validation set during training and stop training once the performance starts to degrade. This prevents the model from overfitting by stopping before it memorizes the training data.
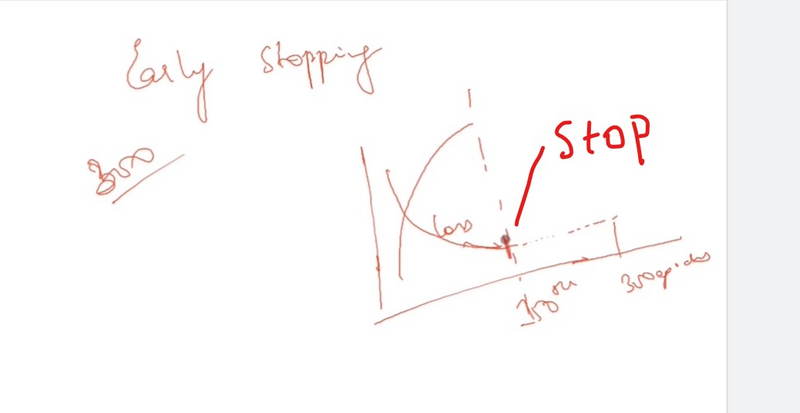
Reduce Model Complexity:
Simplify the architecture of the CNN by reducing the number of layers, the number of neurons in each layer, or the overall number of parameters. A simpler model is less prone to overfitting, especially with limited data.
Transfer Learning:
Use pre-trained models on large datasets and fine-tune them for the specific task of interest. Transfer learning leverages features learned on diverse data, helping the model generalize better to new tasks with limited data.
Batch Normalization:
Batch normalization normalizes the inputs of a layer, reducing internal covariate shift. It helps stabilize and accelerate training, acting as a form of regularization and mitigating overfitting.


Gradient Clipping:
Clip the gradients during backpropagation to prevent exploding gradients, especially in deep networks. This can help stabilize training and prevent the model from overfitting to noisy gradients.
Ensemble Methods:
Train multiple CNN models with different initializations or architectures and combine their predictions. Ensemble methods can reduce overfitting by averaging out individual model biases.
Cross-Validation:
Use cross-validation to assess model performance on different subsets of the data. This helps ensure that the model's generalization performance is consistent across different data partitions.
Learning Rate Scheduling:
Adjust the learning rate during training. Gradually decreasing the learning rate can help the model converge to a more robust solution and avoid oscillations around local minima.
Noise Injection:
Introduce noise into the training process, such as dropout or adding random noise to input data. Noise injection can act as a form of regularization, preventing the model from fitting noise in the training data.
The effectiveness of these techniques may vary depending on the specific characteristics of the dataset and the complexity of the task. Experimentation and tuning are essential to find the right combination of techniques that work well for a given CNN architecture and dataset.
How batch normalization avoid overfitting with example in CNN
Batch Normalization (BatchNorm) is a regularization technique that can help mitigate overfitting in Convolutional Neural Networks (CNNs). It normalizes the inputs to a layer in a mini-batch, making the optimization process more stable and accelerating training. Additionally, BatchNorm acts as a form of regularization by introducing a slight noise during training. Here's how BatchNorm can help avoid overfitting, along with an example:
How Batch Normalization Works:
Normalization:
BatchNorm normalizes the input to a layer by subtracting the batch mean and dividing by the batch standard deviation. This helps address internal covariate shift, making the training more stable.
Scaling and Shifting:
After normalization, the normalized values are scaled by a learnable parameter (gamma) and shifted by another learnable parameter (beta). This introduces flexibility to the normalization process.
Parameter Updates:
The gamma and beta parameters are updated during training through backpropagation. These parameters act as a form of learnable affine transformation, allowing the model to adapt to the specific characteristics of the data.
Mini-Batch Statistics:
BatchNorm computes the mean and standard deviation within each mini-batch during training. This introduces a form of noise, as each mini-batch has slightly different statistics. This stochastic element helps the model generalize better and acts as a regularizer.
Example of Batch Normalization in Keras:
Here's an example of using BatchNorm in a simple CNN using Keras:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, BatchNormalization
# Build a simple CNN with Batch Normalization
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(BatchNormalization())
model.add(Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
In this example:
- BatchNorm layers are added after each Conv2D layer and before the activation function.
- The model includes MaxPooling2D layers to downsample the spatial dimensions.
- The final layers consist of dense layers with BatchNorm before the activation function . How BatchNorm Helps Avoid Overfitting: Reducing Internal Covariate Shift:
BatchNorm helps stabilize and accelerate training by reducing internal covariate shift. This can contribute to more stable convergence and mitigate overfitting.
Adapting to Mini-Batch Statistics:
The mini-batch statistics introduce a form of noise during training, making the model more robust and preventing it from overfitting to specific characteristics of the training data.
Regularization Effect:
The learnable parameters (gamma and beta) act as additional parameters that are updated during training. This introduces a regularization effect, helping the model generalize better.
When using BatchNorm, it's essential to monitor the model's performance on both the training and validation sets to ensure that it is not overfitting to the training data. Adjusting the learning rate and exploring other regularization techniques in conjunction with BatchNorm can further improve the model's generalization performance.
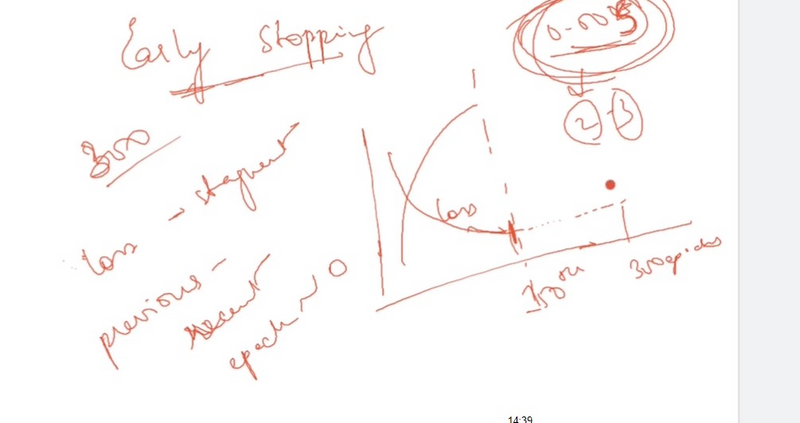
How Early stopping is used to avoid overfitting with example in CNN
Early stopping is a regularization technique used to prevent overfitting in Convolutional Neural Networks (CNNs) by monitoring the model's performance on a validation set during training. It involves stopping the training process once the model's performance on the validation set starts to degrade, preventing the model from memorizing noise in the training data. Here's how early stopping works, along with an example in a simple CNN using Keras:
How Early Stopping Works:
Monitor Validation Performance:
During training, monitor the model's performance on a separate validation set. This set is not used for training but is reserved for evaluating how well the model generalizes to unseen data.
Patience Parameter:
Define a "patience" parameter, which represents the number of epochs with no improvement on the validation set that the training process can tolerate before stopping.
Early Stopping Criteria:
If the validation performance does not improve for a specified number of consecutive epochs (exceeding the patience threshold), the training process is halted.
Retrieve Best Model:
The model weights from the epoch with the best validation performance are typically saved. This is considered the "best" model in terms of generalization to unseen data.
Example of Early Stopping in Keras:
Here's an example of using early stopping in a simple CNN using Keras:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.callbacks import EarlyStopping
# Build a simple CNN with Early Stopping
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Define Early Stopping callback
early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
# Train the model with Early Stopping
history = model.fit(train_data, train_labels, epochs=50, validation_data=(val_data, val_labels), callbacks=[early_stopping])
In this example:
The EarlyStopping callback is used to monitor the validation loss (monitor='val_loss') and set a patience of 3 epochs (patience=3).
The training process stops if the validation loss does not improve for three consecutive epochs.
The restore_best_weights=True option restores the model weights from the epoch with the best validation loss.
How Early Stopping Helps Avoid Overfitting:
Prevents Overfitting:
Early stopping prevents the model from continuing to train when it starts to overfit the training data. This is indicated by a lack of improvement on the validation set.
Generalization:
By stopping at the point of best validation performance, early stopping ensures that the model generalizes well to unseen data, rather than memorizing noise in the training set.
Saves Training Time:
Early stopping can save computational resources and training time by avoiding unnecessary epochs that do not contribute to better generalization.
It's important to choose the patience parameter carefully. Too much patience may stop training prematurely, while too little patience may not prevent overfitting effectively. Experimentation and monitoring the validation performance during training are key to finding an appropriate patience value.
How weight initializor avoid overfitting with example in CNN
Weight initialization is a crucial aspect of training Convolutional Neural Networks (CNNs) and can indirectly contribute to avoiding overfitting. Proper weight initialization helps the model converge faster and achieve better generalization. Here's an explanation of how weight initialization can impact overfitting, along with an example using Keras:
Importance of Weight Initialization:
Faster Convergence:
Properly initialized weights can help the network converge faster during training. Faster convergence can be advantageous as it reduces the risk of overfitting, especially when the model reaches optimal performance more quickly.
Avoiding Exploding or Vanishing Gradients:
Well-initialized weights help avoid issues like exploding or vanishing gradients, which can hinder the training process. These issues can contribute to overfitting, especially when gradients become unstable during backpropagation.
Balancing Neuron Activations:
Initialization techniques that balance the activations of neurons in different layers can contribute to better model generalization. This balance helps prevent neurons from becoming overly active or inactive, which can occur with poorly initialized weights.
Example of Weight Initialization in Keras:
Here's an example of using a specific weight initialization technique (Glorot initialization) in a simple CNN using Keras:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.initializers import GlorotUniform
# Build a simple CNN with Glorot initialization
model = Sequential()
# Use Glorot initialization for Conv2D layers
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer=GlorotUniform(), input_shape=(64, 64, 3)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer=GlorotUniform()))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer=GlorotUniform()))
model.add(Dense(10, activation='softmax', kernel_initializer=GlorotUniform()))
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
In this example:
The kernel_initializer parameter is set to GlorotUniform() for each Conv2D and Dense layer. Glorot initialization (also known as Xavier initialization) is designed to work well with activation functions like ReLU.
How Weight Initialization Helps Avoid Overfitting:
Balanced Learning:
Proper weight initialization contributes to a balanced learning process by preventing neurons from starting with extremely small or large weights. This balance helps stabilize training and avoid overfitting.
Encourages Smooth Optimization:
Well-initialized weights contribute to a smoother optimization landscape, making it easier for the optimizer to navigate. This can prevent the model from fitting noise and contributing to overfitting.
Improved Generalization:
Faster convergence and better-balanced neuron activations can lead to improved generalization. This is crucial in preventing the model from memorizing the training data and overfitting.
Choice of Initialization Method:
Different weight initialization methods are suitable for different activation functions and network architectures. Experimenting with initialization methods and choosing one that aligns well with the model's structure can contribute to better generalization.
While Glorot initialization is a popular choice, it's important to note that other initialization techniques, such as He initialization, are also widely used. The choice of the initialization method may depend on the specific characteristics of the network architecture and the activation functions used.

Top comments (0)