What Are Bounding Boxes
bounding box is an imaginary rectangular box that includes an object and a set of data points. In the context of digital image processing, the bounding box denotes the border’s coordinates on the X and Y axes that enclose an image. They are used to identify a target and serve as a reference for object detection and generate a collision box for the object.
Bounding boxes are the key elements and one of the primary image processing tools for video annotation projects. In essence, a bounding box is an imaginary rectangle that outlines the object in an image as a part of a machine learning project requirement. The imaginary rectangular frame encloses the object in the image.
Bounding boxes specify the position of the object, its class, and confidence which tells the degree of probability that the object is actually present in the bounding box.
Computer vision offers amazing applications – from self-driving cars to facial recognition and more. And this, in turn, is made possible with image processing.
So, is image processing as simple as drawing rectangles or patterns around objects? No. That being said, what do bounding boxes do
How Do Bounding Boxes Work In Object Detection
As mentioned, the bounding box is an imaginary rectangle that acts as a reference point for object detection and develops a collision box for the object.
So, how does it help data annotators? Well, professionals use the idea of bounding boxes to draw imaginary rectangles over the images. They create outlines of the objects in question within each image and define its X and Y coordinates. This makes the job of machine learning algorithms simpler, helping them find collision paths and such, thereby saving computing resources.
For example, in the below image, each vehicle is a key object whose position and location are essential for training the machine learning models. Data annotators use the bounding boxes technique to draw the rectangles around each of these objects – vehicles, in this case.
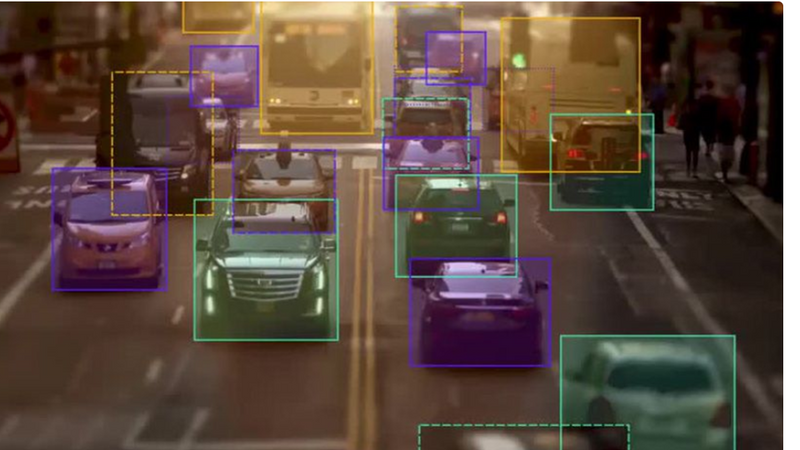
Then, they use the coordinates to understand the position and location of each object, which is useful to train the machine learning models. A single bounding box doesn’t provide a good prediction rate. For enhanced object detection, multiple bounding boxes must be used in combination with data augmentation methods.
Bounding boxes are highly efficient and robust image annotation techniques that reduce costs considerably.
Parameters Defining A Bounding Box
The parameters are based on the conventions used to specify the bounding box. The key parameters used include:
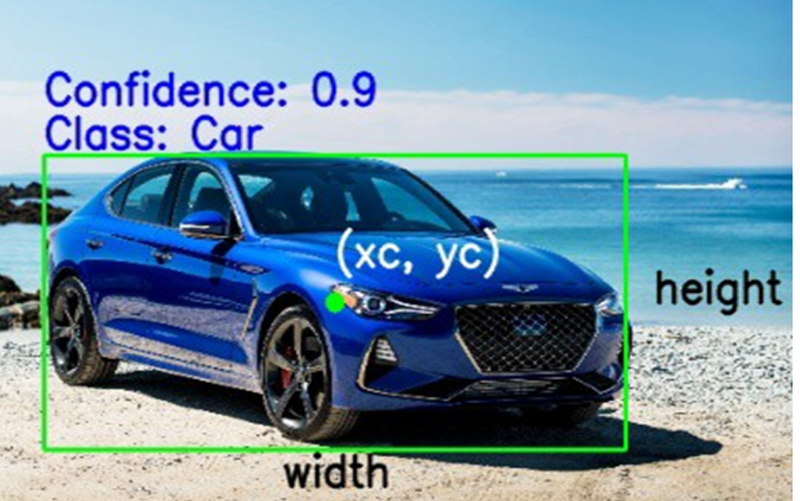
Class: It denotes the object inside the bounding box — for example, cars, houses, buildings, etc.
(X1, Y1): This refers to the X and Y coordinates of the top left corner of the rectangle.
(X2, Y2): This refers to the X and Y coordinates of the bottom right corner of the rectangle.
(Xc, Yc): This refers to the X and Y coordinates of the center of the bounding box.
Width: This denotes the width of the bounding box.
Height: This denotes the height of the bounding box.
Confidence: This represents the possibility of the object being in the box. Say, the confidence is 0.9. This means there’s a 90% probability that the object will actually be present inside the box.
Conventions Specifying A Bounding Box
When specifying a bounding box, usually, two main conventions need to be included. These are:
The X and Y coordinates of the top left and bottom right points of the rectangle.
The X and Y coordinates of the center of the bounding box, along with its width and height.
Let’s illustrate this with the example of a car.
a. With respect to the first convention, the bounding box is specified as per the coordinates of the top left and bottom right points.

With respect to the second convention, the bounding box is described as per the center coordinates, width, and height.
How Are The Conventions Related?
Depending on the use case, it is possible to convert between the different convention types.
Xc = (X1 + X2)/2
Yc = (Y1 + Y2)/2
Width = (X2 - X1)
Height = (Y2 - Y1)
Bounding Boxes Explained With Programming Code
Let’s see another example about the location or position of an object with code snippets.

Top comments (0)