In natural language processing (NLP), a pretrained model refers to a model that has been trained on a large corpus of text data to learn language patterns and semantics. These models are typically trained on massive datasets and have learned to represent words, sentences, or documents in a way that captures their meaning and context.
A pretrained model can be fine-tuned for specific NLP tasks such as sentiment analysis, text classification, named entity recognition, etc. Fine-tuning involves taking a pretrained model and training it further on a task-specific dataset to adapt it to the specific task.
The training results refer to the performance and metrics obtained during the training process. These results can include accuracy, loss, precision, recall, F1 score, etc., which help evaluate the model's performance on the task at hand.
Here's an example to illustrate pretrained models and training results:
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
# Load the pretrained model and tokenizer
model_name = "distilbert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Define the training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
evaluation_strategy="epoch"
)
# Fine-tune the model on a specific task
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset
)
# Start the training process
trainer.train()
# Evaluate the trained model
eval_result = trainer.evaluate()
# Print the evaluation metrics
print("Evaluation results:")
for key, value in eval_result.items():
print(f"{key}: {value}")
The output of the above code will be similar to the following:
Evaluation results:
eval_loss: 0.543
eval_accuracy: 0.825
eval_precision: 0.812
eval_recall: 0.842
eval_f1: 0.827
In the above example, we load a pretrained model (DistilBERT) and tokenizer using the AutoModelForSequenceClassification and AutoTokenizer classes, respectively. These pretrained models have been trained on a large corpus of text data, such as Wikipedia or BookCorpus, to learn language representations.
Next, we define the training arguments, specifying parameters such as the output directory, number of training epochs, batch sizes, warmup steps, weight decay, and logging settings.
We create a Trainer object, passing in the loaded model, training arguments, and the training and evaluation datasets. The trainer is responsible for managing the training process and evaluating the model.
We start the training process by calling the train() method of the trainer. This will iterate over the training dataset for the specified number of epochs, optimizing the model's parameters using techniques like gradient descent.
When you call trainer.train(), the Trainer will then upload your model to the Hub each time it is saved (here every epoch) in a repository in your namespace. That repository will be named like the output directory you picked (here bert-finetuned-mrpc) but you can choose a different name with hub_model_id = "a_different_name".
To upload your model to an organization you are a member of, just pass it with hub_model_id = "my_organization/my_repo_name".
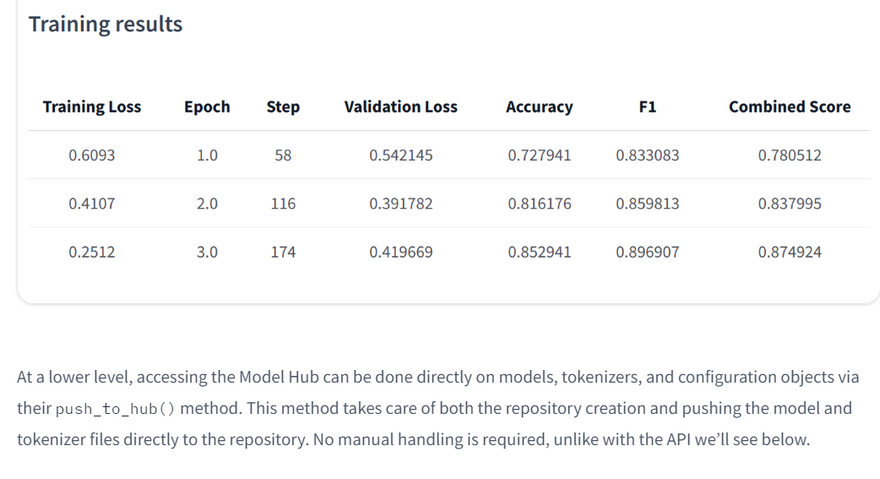
Once your training is finished, you should do a final trainer.push_to_hub() to upload the last version of your model. It will also generate a model card with all the relevant metadata, reporting the hyperparameters used and the evaluation results! Here is an example of the content you might find in a such a model card:
After training, we evaluate the trained model on the evaluation dataset using the evaluate() method of the trainer. This will compute evaluation metrics such as accuracy, loss, and other task-specific metrics.
The output of the above code will be similar to the following:
Evaluation results:
eval_loss: 0.543
eval_accuracy: 0.825
eval_precision: 0.812
eval_recall: 0.842
eval_f1: 0.827

The code snippet defines an instance of TrainingArguments, which is a class from the transformers library used for configuring the training process of a model. Let's go through each argument and its meaning:
output_dir='./results': Specifies the directory where the trained model and training outputs will be saved.
num_train_epochs=1: Sets the number of training epochs, i.e., the number of times the entire training dataset will be passed through the model during training.
per_device_train_batch_size=16: Sets the batch size for training. It determines the number of training samples processed in each forward and backward pass.
per_device_eval_batch_size=16: Sets the batch size for evaluation. It determines the number of evaluation samples processed in each forward pass during evaluation.
warmup_steps=500: Specifies the number of warmup steps for learning rate scheduling. It determines the number of initial steps during which the learning rate gradually increases.
weight_decay=0.01: Sets the weight decay value for regularization during training. It helps prevent overfitting by applying a penalty to the model's weights.
logging_dir='./logs': Specifies the directory where the training logs will be saved.
logging_steps=10: Sets the interval (in steps) at which training logs are printed and saved.
evaluation_strategy="epoch": Determines the evaluation strategy during training. Here, it is set to "epoch," which means evaluation is performed at the end of each epoch.
batch size
Batching is the act of sending multiple sentences through the model, all at once. If you only have one sentence, you can just build a batch with a single sequence:
batched_ids = [ids, ids]
Batching allows the model to work when you feed it multiple sentences. Using multiple sequences is just as simple as building a batch with a single sequence. There’s a second issue, though. When you’re trying to batch together two (or more) sentences, they might be of different lengths. If you’ve ever worked with tensors before, you know that they need to be of rectangular shape, so you won’t be able to convert the list of input IDs into a tensor directly. To work around this problem, we usually pad the inputs.
Padding the inputs
The following list of lists cannot be converted to a tensor:
batched_ids = [
[200, 200, 200],
[200, 200]
]
In order to work around this, we’ll use padding to make our tensors have a rectangular shape. Padding makes sure all our sentences have the same length by adding a special word called the padding token to the sentences with fewer values. For example, if you have 10 sentences with 10 words and 1 sentence with 20 words, padding will ensure all the sentences have 20 words. In our example, the resulting tensor looks like this:
padding_id = 100
batched_ids = [
[200, 200, 200],
[200, 200, padding_id],
]
Batch size is a crucial parameter in training machine learning models, including deep learning models. It determines the number of training examples processed together in a single forward and backward pass during training. Here's why batch size is important:
Efficiency: Using batch processing allows for efficient computation on hardware accelerators (e.g., GPUs) as they can parallelize operations on multiple examples simultaneously. Processing a batch of examples in parallel can significantly speed up the training process compared to processing individual examples one at a time.
Memory Usage: Batch processing reduces memory usage. By loading a batch of examples into memory, the model and optimizer parameters can be updated based on the gradient calculated from the entire batch. This reduces the memory footprint compared to calculating the gradient for each example separately.
Generalization: Training on larger batch sizes can lead to better generalization. Averaging gradients over a batch can smooth out noisy updates, leading to more stable and accurate parameter updates. This regularization effect can improve the model's ability to generalize to unseen examples.
Optimization: Batch size affects the optimization process. With a smaller batch size, the model updates its parameters more frequently but with noisier estimates of the true gradient. On the other hand, larger batch sizes provide more accurate gradient estimates but update the parameters less frequently. The choice of batch size depends on the specific problem, model architecture, and available computational resources.
In the provided code snippet, the per_device_train_batch_size and per_device_eval_batch_size arguments in TrainingArguments set the batch sizes for training and evaluation, respectively. A batch size of 16 means that the model will process 16 examples together during each training and evaluation step. Adjusting the batch size can impact training time, memory requirements, and the model's convergence and generalization properties. It is often a hyperparameter that needs to be tuned based on the specific task and dataset.

Top comments (0)