Concept
Linear Regression:
Logistic Regression:
Application of hypothesis
Types of hypothesis
Concept
In machine learning, a hypothesis refers to the proposed relationship or pattern between input features and the output variable that a model tries to learn. It is the core concept behind many machine learning algorithms and serves as a foundation for making predictions or classifications on new, unseen data.
A hypothesis can be thought of as a function or model that takes input features as its input and produces an output or prediction. The goal of the machine learning algorithm is to find the best hypothesis that can accurately generalize from the training data to unseen examples.
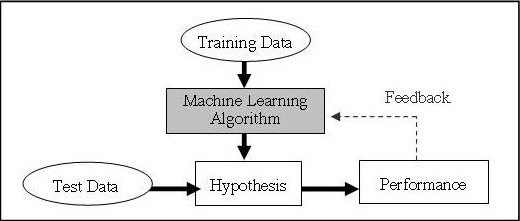
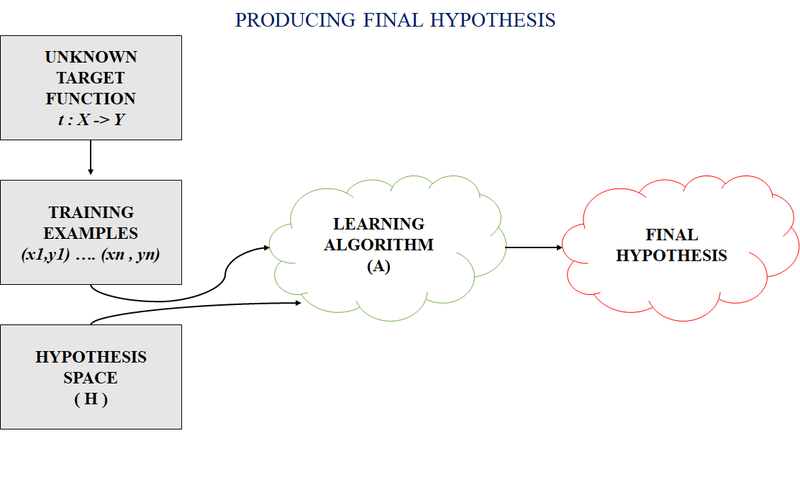

Here are a couple of examples to illustrate the concept of a hypothesis in machine learning:
Linear Regression:
In linear regression, the hypothesis is a linear function that tries to capture the relationship between the input features and the target variable. For example, consider a dataset that contains information about houses, such as their sizes (in square feet) and corresponding prices (in dollars). The hypothesis in this case would be a linear equation of the form:
h(x) = w0 + w1*x
Here, h(x) represents the predicted price, x is the input feature (size of the house), and w0 and w1 are the parameters that the model needs to learn.
Logistic Regression:
In logistic regression, the hypothesis is a logistic function that estimates the probability of a binary outcome based on the input features. For instance, suppose you have a dataset of student exam scores and whether they passed (1) or failed (0) a test. The hypothesis in this case would be the sigmoid function:
h(x) = 1 / (1 + exp(-(w0 + w1*x)))
Here, h(x) represents the probability of passing the test, x is the input feature (exam score), and w0 and w1 are the parameters to be learned.
The process of training a machine learning model involves finding the optimal values for the parameters in the hypothesis function, typically by minimizing a loss function that quantifies the discrepancy between the predicted outputs and the true labels in the training data. Once the model is trained, it can use the learned hypothesis to make predictions or classify new, unseen examples.
Application of hypothesis
The application of hypotheses in machine learning is pervasive across various domains and problem types. Here are some common applications where hypotheses play a crucial role:
Regression: Hypotheses are used to model relationships between input features and continuous output variables. This is widely applied in predicting housing prices, stock market trends, weather forecasting, and other numerical predictions.
Classification: Hypotheses are utilized to classify input instances into different predefined categories or classes. Examples include email spam detection, image recognition, sentiment analysis, and medical diagnosis.
Anomaly Detection: Hypotheses can be used to identify unusual or anomalous patterns in data. This is useful in fraud detection, network intrusion detection, and fault detection in industrial processes.
Recommender Systems: Hypotheses are used to predict user preferences and make personalized recommendations. This is seen in recommendation engines for movies, music, e-commerce products, and content platforms.
Natural Language Processing (NLP): Hypotheses play a role in language modeling, machine translation, text classification, and sentiment analysis tasks in NLP applications.
Time Series Analysis: Hypotheses are employed to model temporal patterns and make predictions based on historical data. This is seen in financial market forecasting, demand forecasting, and resource allocation.
Reinforcement Learning: Hypotheses are used to model an agent's behavior and predict the best actions to maximize rewards in sequential decision-making problemssuch as game playing and autonomous robotics.
Clustering: Hypotheses are employed to group similar instances together based on their features. This is useful in customer segmentation, image segmentation, and document clustering.
Dimensionality Reduction: Hypotheses are used to find lower-dimensional representations of high-dimensional data while preserving relevant information. Techniques like Principal Component Analysis (PCA) and t-SNE rely on hypotheses to capture the underlying structure of the data.
Generative Models: Hypotheses are used to learn the underlying data distribution and generate new samples. Examples include generative adversarial networks (GANs) and variational autoencoders (VAEs) used for image synthesis and text generation.
Types
These are just a few examples of the wide range of applications where hypotheses are essential in machine learning. The specific hypothesis formulation and model selection depend on the nature of the problem, the available data, and the desired outcome.
In machine learning, hypotheses can be categorized into different types based on their characteristics and the nature of the problem being solved. Here are some common types of hypotheses:
Linear Hypothesis:
A linear hypothesis assumes a linear relationship between the input features and the output variable. It is represented by a linear equation or function. For example, in linear regression, the hypothesis is a linear combination of the input features, where the predicted output is a weighted sum of the features.
Example: h(x) = w0 + w1x1 + w2x2
Here, h(x) represents the predicted output, x1 and x2 are input features, and w0, w1, and w2 are the parameters to be learned.
Non-Linear Hypothesis:
A non-linear hypothesis allows for more complex relationships between the input features and the output variable. It can capture non-linear patterns and dependencies. Non-linear hypotheses can be represented by functions such as polynomials, exponential functions, or neural networks.
Example: h(x) = w0 + w1x + w2x^2
Here, h(x) represents the predicted output, x is the input feature, and w0, w1, and w2 are the parameters.
Probabilistic Hypothesis:
Probabilistic hypotheses are used in classification problems where the goal is to estimate the probability of an input belonging to different classes. The hypothesis assigns probabilities to each class and selects the most probable class as the predicted output. Examples of probabilistic hypotheses include logistic regression and Naive Bayes classifiers.
Example: h(x) = P(y=1|x) = 1 / (1 + exp(-(w0 + w1*x)))
Ensemble Hypothesis:
Ensemble hypotheses combine multiple individual hypotheses to make predictions. They leverage the idea that combining multiple weak models can lead to stronger overall performance. Ensemble methods, such as random forests and gradient boosting, create an ensemble hypothesis by aggregating predictions from multiple base models.
Example: An ensemble hypothesis can be created by averaging the predictions of multiple decision trees in a random forest.
Deep Learning Hypothesis:
Deep learning hypotheses are used in deep neural networks, which consist of multiple layers of interconnected nodes (neurons). These hypotheses can capture complex patterns and representations from raw data. Deep learning hypotheses can involve convolutional layers for image analysis, recurrent layers for sequential data, or a combination of various layer types.
Example: A deep learning hypothesis can be a convolutional neural network (CNN) that takes raw image pixels as input and produces a prediction for image classification.
SUMMARY
relationship or pattern between input features and the output variable.
core concept:for making predictions or classifications on new, unseen data
takes input features as its input and produces an output or prediction
ccurately generalize from the training data to unseen
machine learning model involves finding the optimal values for the parameters in the hypothesis function, typically by minimizing a loss function that quantifies
Linear Regression:
capture the relationship between the input features and the target variable
Logistic Regression:
estimates the probability of a binary outcome based on the input features
Application of hypothesis
Regression:model relationships between input features and continuous output variables.
Classification:classify input instances into different predefined categories or classes. email spam detection, image recognition, sentiment analysis, and medical diagnosis
Anomaly Detection
Recommender Systemspredict user preferences and make personalized recommendations
Natural Language Processing:machine translation, text classification, and sentiment analysis tasks
Time Series Analysis:based on historical data,financial market forecasting, demand forecasting, and resource allocation.
Reinforcement Learning:predict the best actions to maximize rewards in sequential decision-making problems,
Clustering:group similar instances together based on their features,image segmentation, and document clustering.
Dimensionality Reduction:Principal Component Analysis (PCA) and t-SNE r
Generative Models:generative adversarial networks (GANs) and variational autoencoders (VAEs) used for image synthesis and text generation.
Types of hypothesis
Linear Hypothesis:linear relationship between the input features and the output variable.
Non-Linear Hypothesis:more complex relationships between the input features and the output variable.
Probabilistic Hypothesis:estimate the probability of an input belonging to different classes.
Ensemble Hypothesis:combine multiple individual hypotheses to make predictions.combining multiple weak models can lead to stronger overall performance
Deep Learning Hypothesis:capture complex patterns and representations from raw data,takes raw image pixels as input and produces a prediction for image classification

Top comments (0)