Advantage of YOLO Architecture
What is YOLO
Difference between CNN and Yolo
Object Detection with YOLO Example
Biggest advantages
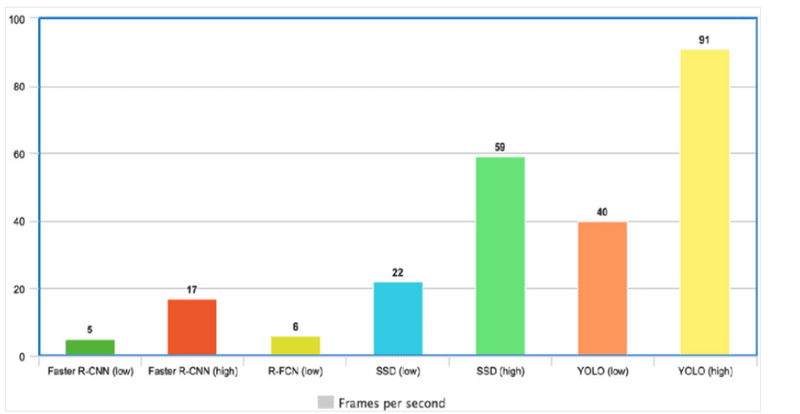
- Speed (45 frames per second — better than realtime)
- Network understands generalized object representation (This allowed them to train the network on real world images and predictions on artwork was still fairly accurate).
- faster version (with smaller architecture) — 155 frames per sec but is less accurate .High level idea: Compared to other region proposal classification networks (fast RCNN) which perform detection on various region proposals and thus end up performing prediction multiple times for various regions in a image, Yolo architecture is more like FCNN (fully convolutional neural network) and passes the image (nxn) once through the FCNN and output is (mxm) prediction. This the architecture is splitting the input image in mxm grid and for each grid generation 2 bounding boxes and class probabilities for those bounding boxes. Note that bounding box is more likely to be larger than the grid itself.
What is YOLO
You Only Look Once (YOLO) is a state-of-the-art, real-time object detection algorithm introduced in 2015 by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi in their famous research paper “You Only Look Once: Unified, Real-Time Object Detection”.
The authors frame the object detection problem as a regression problem instead of a classification task by spatially separating bounding boxes and associating probabilities to each of the detected images using a single convolutional neural network (CNN).
By taking the Image Processing with Keras in Python course, you will be able to build Keras based deep neural networks for image classification tasks.
If you are more interested in Pytorch, Deep Learning with Pytorch will teach you about convolutional neural networks and how to use them to build much more powerful models
What Makes YOLO Popular for Object Detection?
Some of the reasons why YOLO is leading the competition include its:
- Speed
- Detection accuracy
- Good generalization
- Open-source 1- Speed YOLO is extremely fast because it does not deal with complex pipelines. It can process images at 45 Frames Per Second (FPS). In addition, YOLO reaches more than twice the mean Average Precision (mAP) compared to other real-time systems, which makes it a great candidate for real-time processing.
High detection accuracy
YOLO is far beyond other state-of-the-art models in accuracy with very few background errors.
3- Better generalization
This is especially true for the new versions of YOLO, which will be discussed later in the article. With those advancements, YOLO pushed a little further by providing a better generalization for new domains, which makes it great for applications relying on fast and robust object detection.
For instance the Automatic Detection of Melanoma with Yolo Deep Convolutional Neural Networks paper shows that the first version YOLOv1 has the lowest mean average precision for the automatic detection of melanoma disease, compared to YOLOv2 and YOLOv3.
4- Open source
Making YOLO open-source led the community to constantly improve the model. This is one of the reasons why YOLO has made so many improvements in such a limited time.
YOLO Architecture
YOLO architecture is similar to GoogleNet. As illustrated below, it has overall 24 convolutional layers, four max-pooling layers, and two fully connected layers.
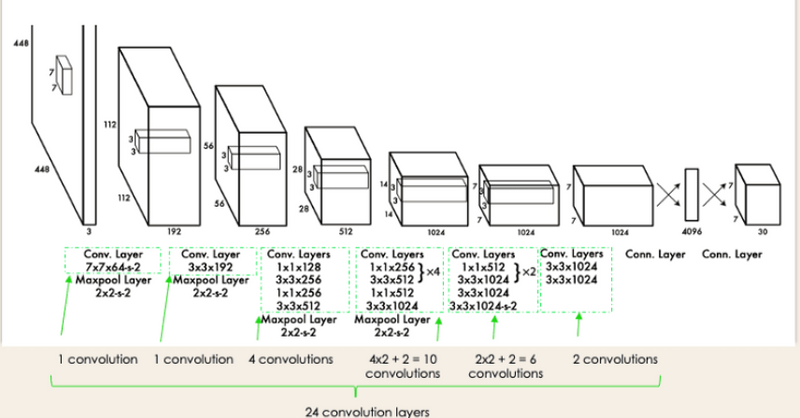
The architecture works as follows:
- Resizes the input image into 448x448 before going through the convolutional network.
- A 1x1 convolution is first applied to reduce the number of channels, which is then followed by a 3x3 convolution to generate a cuboidal output.
- The activation function under the hood is ReLU, except for the final layer, which uses a linear activation function.
- Some additional techniques, such as batch normalization and dropout, respectively regularize the model and prevent it from overfitting . By completing the Deep Learning in Python course, you will be ready to use Keras to train and test complex, multi-output networks and dive deeper into deep learning.
How Does YOLO Object Detection Work?
Now that you understand the architecture, let’s have a high-level overview of how the YOLO algorithm performs object detection using a simple use case.
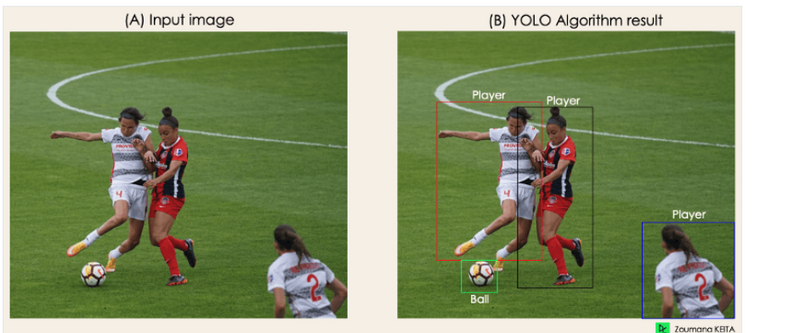
“Imagine you built a YOLO application that detects players and soccer balls from a given image.
But how can you explain this process to someone, especially non-initiated people?
→ That is the whole point of this section. You will understand the whole process of how YOLO performs object detection; how to get image (B) from image (A)
Difference between CNN and Yolo




Image Summary
Focuses on assigning a label to the entire image.
Outputs a class label (e.g., dog or person) without any positional information
YOLO=dentifies the class of objects and their positions within the image.
Outputs a class label along with bounding boxes that specify where in the image the object is located.
idendification + bounding box(positions within the image)
How YOLO process image



Image Summary
Grid Division(step1) + Bounding Boxes(step2): +Detailed Predictions
if C1= 0 image is not presence
if c1=1 image presence
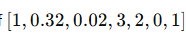
suggests that the probability of an object being present is 1, with specific values for the bounding box coordinates and dimensions.
Training Process of Yolo type of CNN
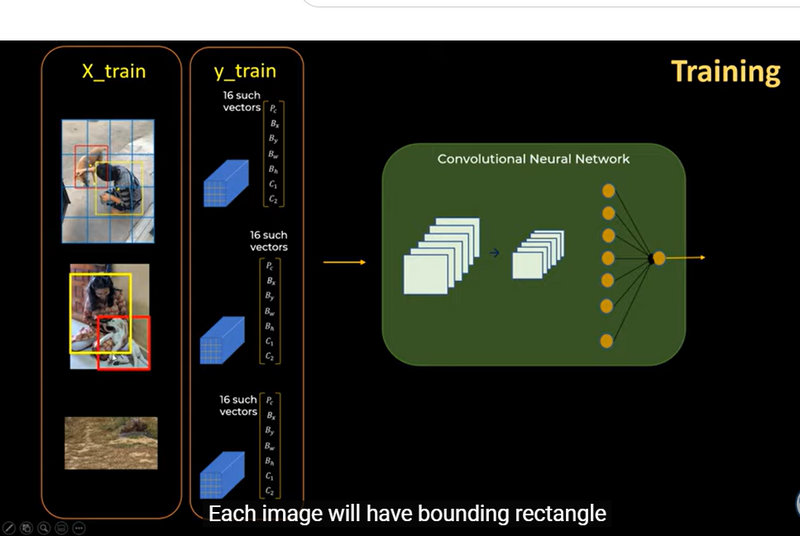
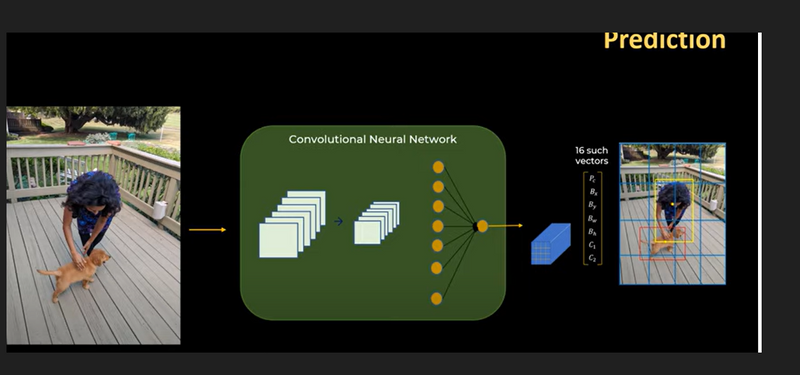

Image Summary
Input data==>contain grids+bounding box for each image
Output Data (y_train):==> 16 vectors for each image
cnn==processing 16 input vector for each image +extrat feturea + then fed into fully connected layers
Output Layer==> predictions for the object classes and their respective bounding boxes
Calculate IOU in object Detection Technique
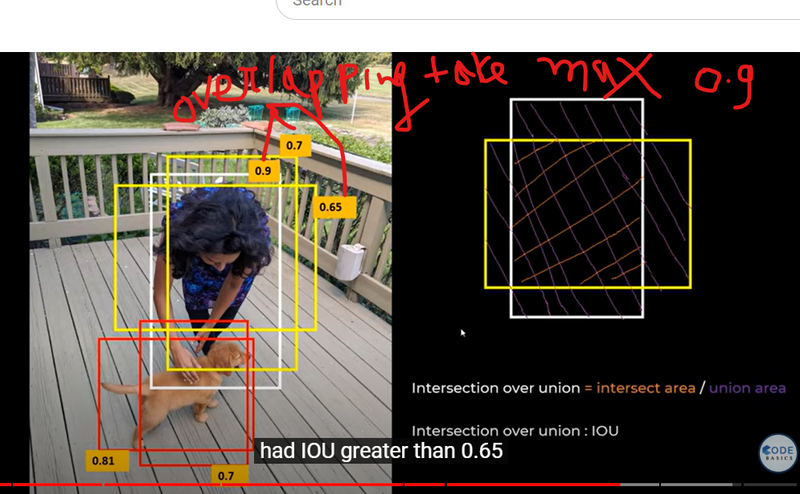


Image Summary
bounding box==detected object + iou score
iou values==better the overlap between the predicted bounding box and the ground truth bounding box
iou formulla
Numericals to calculate IOU
To calculate the Intersection over Union (IoU) using a numerical example, let's take two bounding boxes: the predicted bounding box (Pred) and the ground truth bounding box (Truth). We'll define their coordinates and calculate the IoU step-by-step.



Role of anchor box and confidence score
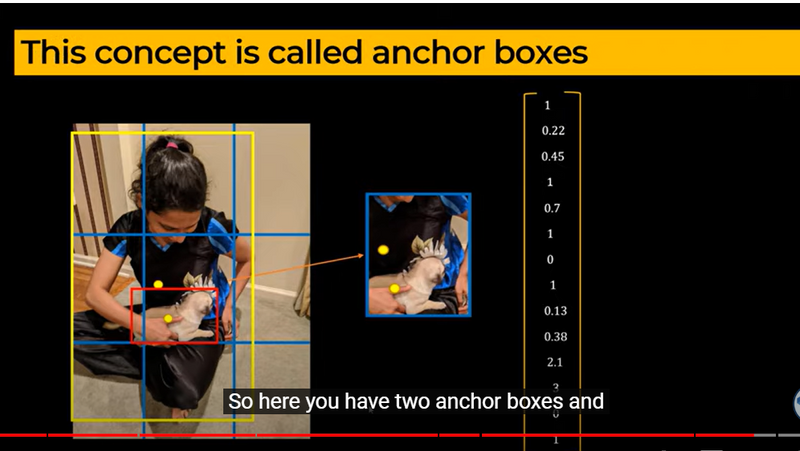

image summary
anchor box==> is designed to predict the presence and position of an object
confidence scores==> indicating how likely it is that an object is present in each anchor box.
A score of 1 ==>suggests a high confidence that an object is present
how a CNN processes an input image to generate predictions based on those anchor boxes.
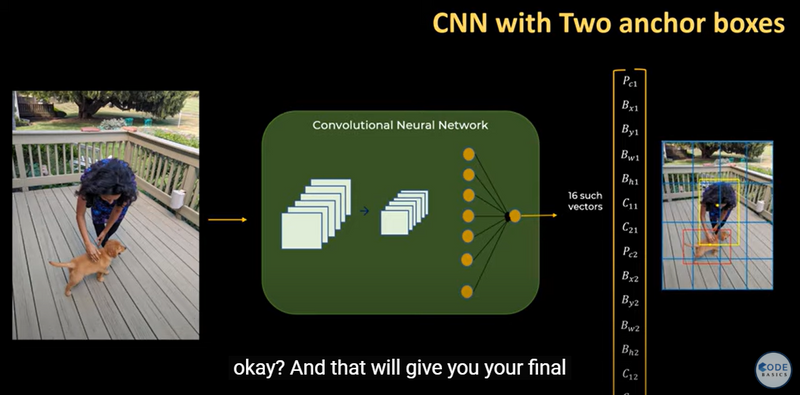

Convolutional Neural Networks (CNNs) and You Only Look Once (YOLO) are both crucial components in the field of computer vision, but they serve different purposes and have unique strengths.
CNNs (Convolutional Neural Networks)
Purpose: CNNs are a type of deep learning model primarily used for image classification, object detection, and image segmentation tasks. They work by using convolutional layers to automatically learn spatial hierarchies of features from input images.
How They Work: CNNs process the entire image to extract features. They pass the image through multiple layers of convolutions, pooling, and activation functions, enabling the model to learn complex patterns.
Use Cases: CNNs are used in various applications, including:
- Image classification (e.g., identifying objects in images)
- Image segmentation (e.g., delineating objects in an image)
- Face recognition
- Medical image analysis
YOLO (You Only Look Once)
Purpose: YOLO is an object detection system that is designed for real-time processing. Unlike traditional object detection algorithms, which often apply a CNN multiple times at different scales, YOLO approaches object detection as a single regression problem, predicting bounding boxes and class probabilities directly from the full image.
How It Works: YOLO divides the input image into a grid and predicts bounding boxes and confidence scores for each grid cell. This means it looks at the image only once to identify multiple objects, which makes it much faster than previous methods that required multiple passes.
Use Cases: YOLO is used in scenarios where real-time object detection is critical, such as:
- Autonomous vehicles (detecting pedestrians, cars, etc.)
- Surveillance systems
- Augmented reality applications
- Robotics
Why YOLO Came About
Speed: YOLO significantly increases the speed of object detection, making it suitable for applications requiring real-time processing. Traditional methods like R-CNN and Fast R-CNN, while accurate, were often too slow for real-time applications.
Unified Architecture: YOLO simplifies the object detection pipeline by using a single neural network architecture. This reduces the complexity of the model and the computational resources required.
Improved Accuracy: While CNNs can achieve high accuracy in classification tasks, YOLO's ability to consider the entire image context helps it improve detection accuracy, especially for smaller objects.
: Object Detection with YOLO
import cv2
import numpy as np
# Load YOLO
net = cv2.dnn.readNet("yolov3.weights", "yolov3.cfg")
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# Load image
img = cv2.imread("image.jpg")
height, width, _ = img.shape
# Prepare image for detection
blob = cv2.dnn.blobFromImage(img, 0.00392, (416, 416), (0, 0, 0), True, crop=False)
net.setInput(blob)
outs = net.forward(output_layers)
# Process outputs
class_ids = []
confidences = []
boxes = []
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5: # Confidence threshold
center_x = int(detection[0] * width)
center_y = int(detection[1] * height)
w = int(detection[2] * width)
h = int(detection[3] * height)
# Rectangle coordinates
x = int(center_x - w / 2)
y = int(center_y - h / 2)
boxes.append([x, y, w, h])
confidences.append(float(confidence))
class_ids.append(class_id)
# Non-max suppression to remove overlapping boxes
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
# Load COCO class labels
with open("coco.names", "r") as f:
classes = [line.strip() for line in f.readlines()]
# Draw bounding boxes
for i in range(len(boxes)):
if i in indexes:
x, y, w, h = boxes[i]
label = str(classes[class_ids[i]])
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(img, label, (x, y + 30), cv2.FONT_HERSHEY_PLAIN, 3, (0, 255, 0), 3)
# Display the output
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Explanation
Step-by-Step Explanation
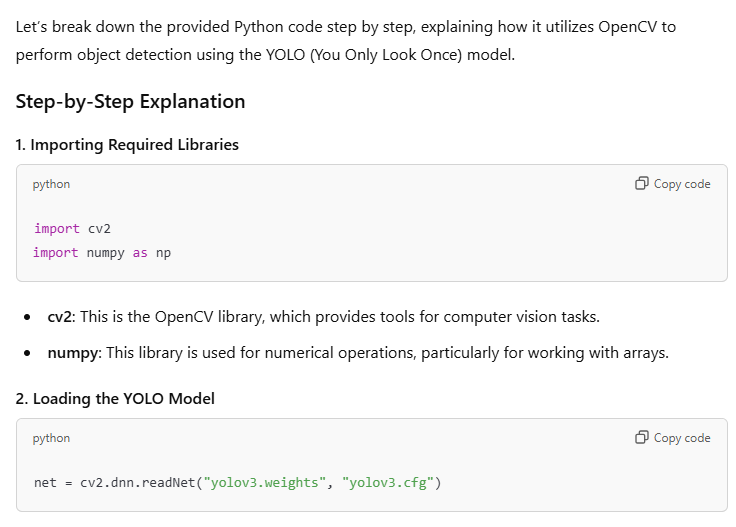
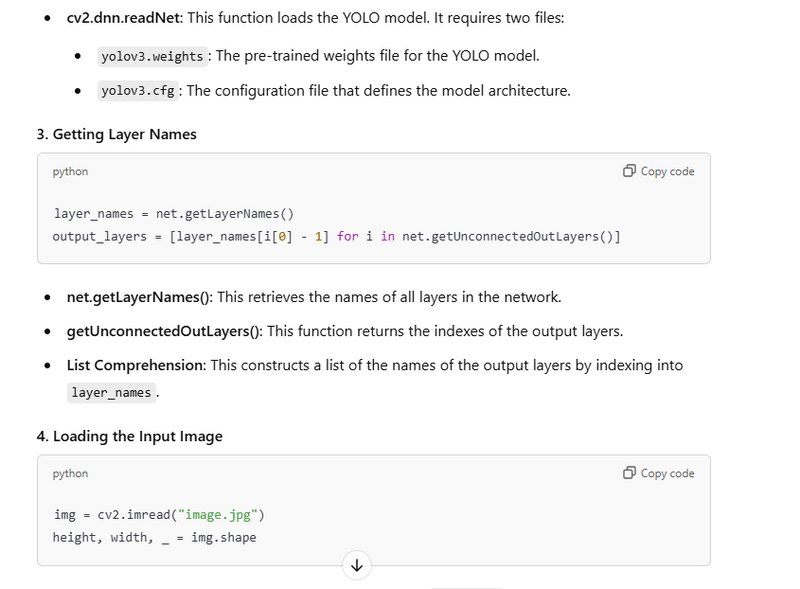

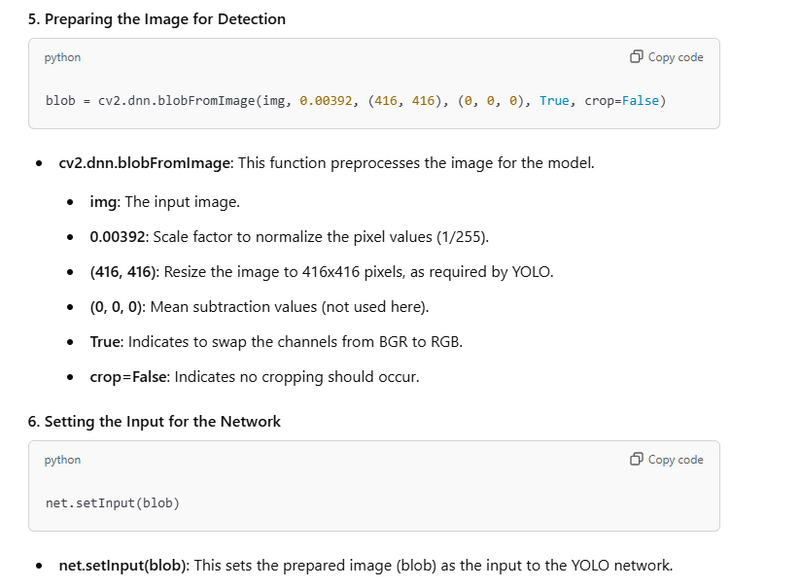
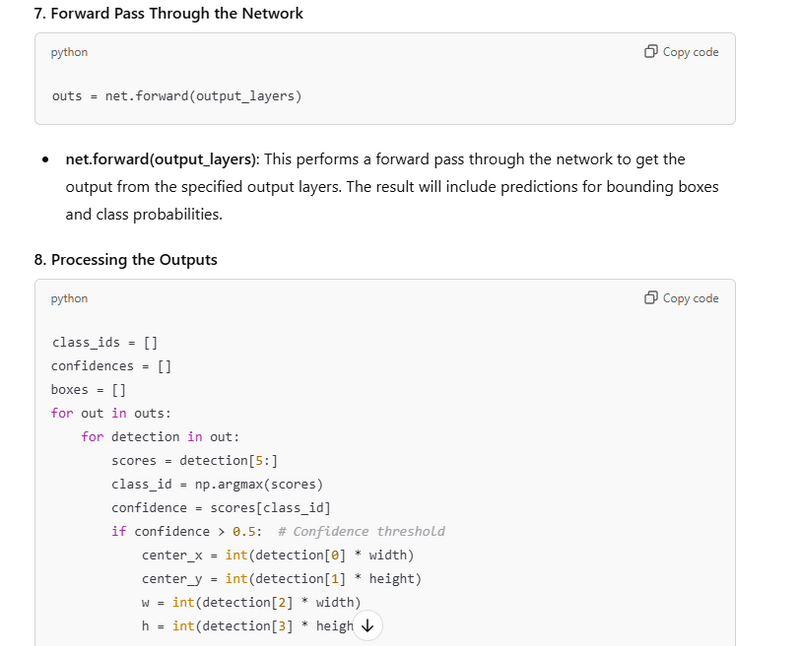


Image Summary
Loading the YOLO Model
Getting Layer Names(output layer)
get image usingimshow
Preparing the Image for Detection(normalize,resize,subtraction)
Setting the Input for the Network net.setInput(blob)
Forward Pass Through the Network using net.forward of output layer
Processing the Outputs==>Lists Initialization+ Nested Loop + Detection Processing:(scores,class_id ,confidence)
Non-Maximum Suppression

Top comments (0)