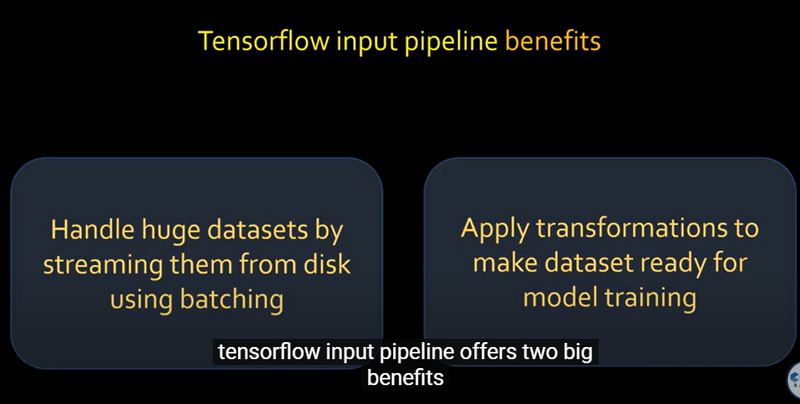
Tensorflow pipeline benefits
Different way to handle large dataset using tensorflow pipeline
Explain the purpose and performance impact Shuffling ,Splitting,Label Extraction,Label Extraction,Scaling.
Different Steps to perform Tensorflow Pipeline
Tensorflow pipeline benefits
The TensorFlow input pipeline is essential for efficiently managing large datasets and preparing them for machine learning models. Here are the key reasons for using it:
Efficient Handling of Large Datasets: The pipeline can handle huge datasets by streaming data directly from disk instead of loading everything into memory. It uses batching to process data in manageable chunks, which helps reduce memory usage and speeds up data processing.
Data Transformation: The pipeline allows for various transformations (e.g., normalization, augmentation) to prepare the data in a format suitable for training. This enables consistent preprocessing and ensures the data is optimized for model performance.
Efficient Data Loading and Preprocessing: The input pipeline uses the tf.data API to manage and process data in parallel with model training, minimizing bottlenecks.
Scalability: Pipelines can handle large datasets, processing data in chunks or batches and performing transformations as needed.
Flexible Transformation: The API offers various operations, such as shuffling, mapping, batching, and caching, which can be combined for optimized training.
Easier Deployment: The tf.data pipeline integrates well with TensorFlow models, making deployment simpler and consistent across environments.
Code: Using tf.data API
import tensorflow as tf
# Simulate a dataset of integers from 0 to 99
data = tf.data.Dataset.range(100)
# Shuffle, batch, and map transformations
pipeline = (
data
.shuffle(buffer_size=100) # Randomize the data
.batch(10) # Batch in groups of 10
.map(lambda x: x * 2) # Multiply each element by 2
.prefetch(buffer_size=tf.data.AUTOTUNE) # Prefetch for efficiency
)
# Print the output from each batch
for batch in pipeline:
print(batch.numpy())

Output
[60 36 82 58 76 56 26 74 62 18]
[94 84 22 10 80 66 48 50 2 88]
Coding for Input Pipeline for NLP Task
import tensorflow as tf
# Example dataset: List of sentences and corresponding labels
sentences = [
"TensorFlow is great for machine learning",
"Natural language processing is fun",
"I love creating deep learning models",
"Transformers have revolutionized NLP",
"TensorFlow Hub provides pre-trained models"
]
labels = [1, 0, 1, 0, 1] # Example binary labels
# Create a tf.data Dataset from sentences and labels
data = tf.data.Dataset.from_tensor_slices((sentences, labels))
# Text vectorization layer to tokenize and convert text to sequences
vectorizer = tf.keras.layers.TextVectorization(output_mode='int', max_tokens=1000)
vectorizer.adapt(sentences) # Fit the vectorizer on the data
# Pipeline: Shuffle, batch, tokenize, and prefetch
pipeline = (
data
.shuffle(buffer_size=5) # Shuffle the sentences
.batch(2) # Batch data in groups of 2
.map(lambda x, y: (vectorizer(x), y)) # Tokenize sentences
.prefetch(buffer_size=tf.data.AUTOTUNE) # Prefetch for efficiency
)
# Print the output from each batch
for batch, labels in pipeline:
print("Batch (tokenized):", batch.numpy())
print("Labels:", labels.numpy()


Different way to handle large dataset using tensorflow pipeline
Handling large datasets efficiently is crucial in machine learning workflows, especially when working with TensorFlow. Here are some strategies that can help manage and process large datasets effectively:
-
Data Loading with TensorFlow Data API
Use tf.data.Dataset: The tf.data.Dataset API in TensorFlow enables you to create a pipeline that can read data in batches, shuffle it, preprocess it, and even parallelize these tasks. This minimizes memory usage and maximizes GPU utilization.Streaming from Disk: Instead of loading the entire dataset into memory, you can stream data directly from storage using Dataset.from_tensor_slices (for smaller datasets) or Dataset.from_generator (for larger, more complex data sources). -
Batching
Batching: Process the data in small chunks (batches) instead of loading the entire dataset at once. Batching allows you to split large datasets into manageable sizes, reducing memory requirements and speeding up training. Use dataset.batch(batch_size) to specify the batch size for training. -
Shuffling and Prefetching
Shuffling: Randomly shuffle the data to ensure each batch contains different data points. This helps reduce bias and makes the model training more robust. Use dataset.shuffle(buffer_size) to shuffle data with a specified buffer size.Prefetching: Use dataset.prefetch(buffer_size=tf.data.AUTOTUNE) to overlap the data preprocessing and model training steps. This loads data for the next batch while the model is training on the current batch, improving training throughput. -
Parallel Processing
Parallel Reads: If you're reading data from multiple files, use dataset.interleave() with parallel calls to read data in parallel from multiple sources, increasing the data-loading speed.Parallel Mapping: Use dataset.map() with num_parallel_calls=tf.data.AUTOTUNE to apply transformations to multiple data items in parallel, leveraging multiple CPU cores. - Caching Caching Data: If your dataset fits in memory, you can use dataset.cache() to cache data in memory after the first epoch. This eliminates the need to re-read data from disk, speeding up subsequent epochs. If the dataset is too large for memory, you can consider caching on disk.
-
Using Optimized Data Formats
TFRecord Format: Store your data in TFRecord format, which is TensorFlow’s efficient binary format. This format is optimized for TensorFlow and can be read in chunks, making it suitable for large datasets.Compression: If using large text files (e.g., CSVs), consider compressing them to reduce disk read times. TensorFlow can read compressed files like .gz. -
Distributed Processing with TPUs or Multiple GPUs
Distributed Strategy: If your dataset is very large and you have access to multiple GPUs or TPUs, use TensorFlow’s tf.distribute.Strategy to distribute the dataset across multiple devices for faster processing and training.
Example: Efficient TensorFlow Pipeline for Large Datasets
Here's a basic example using some of these techniques in a TensorFlow pipeline:
import tensorflow as tf
# Assuming you have a large dataset stored as TFRecord files
dataset = tf.data.TFRecordDataset(["file1.tfrecord", "file2.tfrecord"])
# Define a function to parse and preprocess data
def parse_function(example_proto):
# Parse the input tf.train.Example proto using the dictionary
features = {
'feature1': tf.io.FixedLenFeature([], tf.float32),
'feature2': tf.io.FixedLenFeature([], tf.int64),
}
parsed_features = tf.io.parse_single_example(example_proto, features)
return parsed_features['feature1'], parsed_features['feature2']
# Apply transformations
dataset = dataset.map(parse_function, num_parallel_calls=tf.data.AUTOTUNE)
dataset = dataset.shuffle(buffer_size=10000)
dataset = dataset.batch(32)
dataset = dataset.prefetch(buffer_size=tf.data.AUTOTUNE)
# Use the dataset for model training
model.fit(dataset, epochs=5)
Explain the purpose and performance impact Shuffling ,Splitting,Label Extraction,Label Extraction,Scaling
Code Explanation
The code you provided creates a TensorFlow data pipeline for loading, processing, and preparing images for training, all of which contributes to improved performance and efficiency. Here’s how and why each step in the pipeline enhances performance:
- Creating a List of Files
images_ds = tf.data.Dataset.list_files('images//', shuffle=False)
Purpose: tf.data.Dataset.list_files creates a dataset of file paths. Using a list of file paths allows you to avoid loading all images into memory at once, which is important for large datasets.
Performance Impact: By referencing file paths instead of actual image data, this step reduces memory usage and makes the dataset manageable, even if it’s large.
- Shuffling the Dataset
images_ds = images_ds.shuffle(200)
Purpose: Shuffling is essential for training as it helps prevent the model from learning any unintentional ordering patterns in the data.
Performance Impact: TensorFlow’s shuffle method leverages an internal buffer to handle shuffling efficiently. A larger buffer size (like 200 here) ensures better randomness, while smaller sizes conserve memory.
- Splitting the Dataset
train_size = int(image_count * 0.8)
train_ds = images_ds.take(train_size)
test_ds = images_ds.skip(train_size)
Purpose: The dataset is split into training and testing subsets, typically with 80% of data for training and 20% for testing. take and skip provide an efficient way to split without duplicating or storing data.
Performance Impact: This method avoids unnecessary data copying and makes the code faster and more memory-efficient compared to traditional slicing.
- Label Extraction
def get_label(file_path):
import os
parts = tf.strings.split(file_path, os.path.sep)
return parts[-2]
Purpose: get_label extracts the label (class name) from the file path by splitting the path and using the folder name as the label (e.g., "cat" or "dog").
Performance Impact: By extracting labels directly from file paths, you avoid the need for a separate label dataset, which simplifies the data pipeline and minimizes memory usage.
- Image Processing
def process_image(file_path):
label = get_label(file_path)
img = tf.io.read_file(file_path)
img = tf.image.decode_jpeg(img)
img = tf.image.resize(img, [128, 128])
return img, label
Purpose: process_image reads, decodes, and resizes each image. This function applies necessary transformations to get images into a consistent format.
Performance Impact: Using TensorFlow's built-in functions (tf.io.read_file, tf.image.decode_jpeg, and tf.image.resize) ensures that these operations are highly optimized for performance. Resizing images to a smaller, fixed size (128x128) reduces memory usage and speeds up training by reducing the model's input size.
- Scaling the Images
def scale(image, label):
return image / 255.0, label
train_ds = train_ds.map(scale)
Purpose: scale normalizes the image data to a 0-1 range, which is generally recommended for neural network training to improve convergence and stability.
Performance Impact: Applying the scaling step as part of the pipeline (with map) leverages TensorFlow's efficient data transformation capabilities. Additionally, since scaling occurs on the fly during training, it avoids the need to create and store new scaled copies of the images.
-
Combining All Steps with the tf.data.Dataset Pipeline
The tf.data.Dataset API allows chaining all these operations into a single, continuous pipeline. By using methods like map (for parallel processing), shuffle, and batch, you create a highly efficient pipeline that can load and preprocess data on the fly during training.
Performance Impact: TensorFlow’s data pipeline operations like map, shuffle, batch, and prefetch can work asynchronously with the training step. This means that while the model is training on one batch, the next batch is being prepared. This parallel processing maximizes GPU utilization and avoids bottlenecks caused by data loading. Final Impact on Performance Overall, using a TensorFlow data pipeline as shown here offers:
Reduced Memory Usage: By loading data from disk as needed rather than all at once.
Increased Training Throughput: By leveraging parallel processing, shuffling, and prefetching to keep the data pipeline fast and prevent the model from waiting on data.
Efficient Data Handling: Operations like reading, decoding, resizing, and scaling are performed on the fly, which avoids redundant data processing and storage.
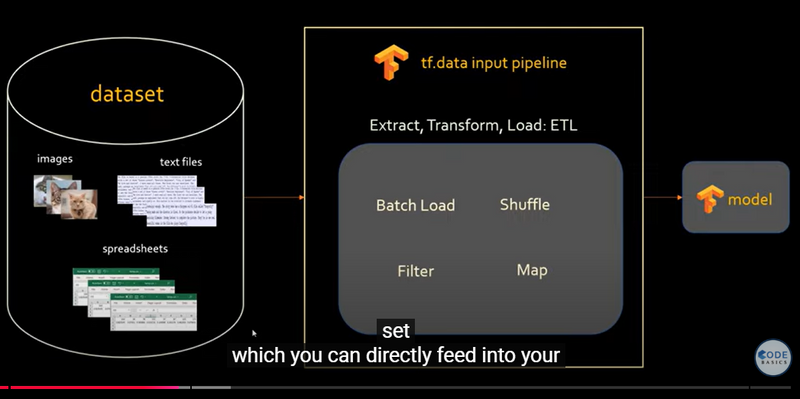
Different Steps to perform Tensorflow Pipeline
Overview of the Pipeline Steps
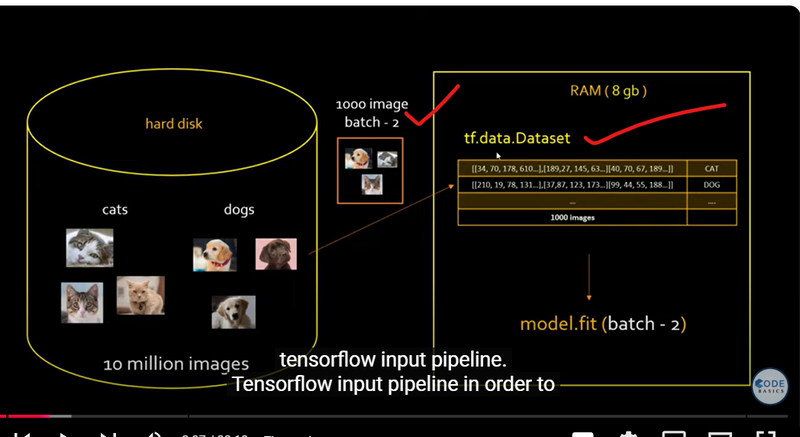
Data Storage and Loading (Hard Disk):
The images show a dataset with millions of images (e.g., 10 million) stored on disk. Loading such a large dataset directly into memory is impractical because it would exceed the memory capacity (e.g., 8GB in the example).
TensorFlow's pipeline loads data in smaller, manageable batches. In the image, this is shown with batches of 1,000 images being loaded from the hard disk into RAM.
tf.data.Dataset:
This object is created to handle and structure the data. tf.data.Dataset manages the dataset and allows you to apply transformations without loading everything into memory at once.
The dataset can be batched, preprocessed, and shuffled efficiently, as shown in the right side of the images.
Batching:
The pipeline loads data in batches (e.g., 1,000 images) instead of all at once. This approach conserves memory and allows the model to train on manageable portions of data at a time.
The batch size can be adjusted based on the available memory, which optimizes RAM usage.
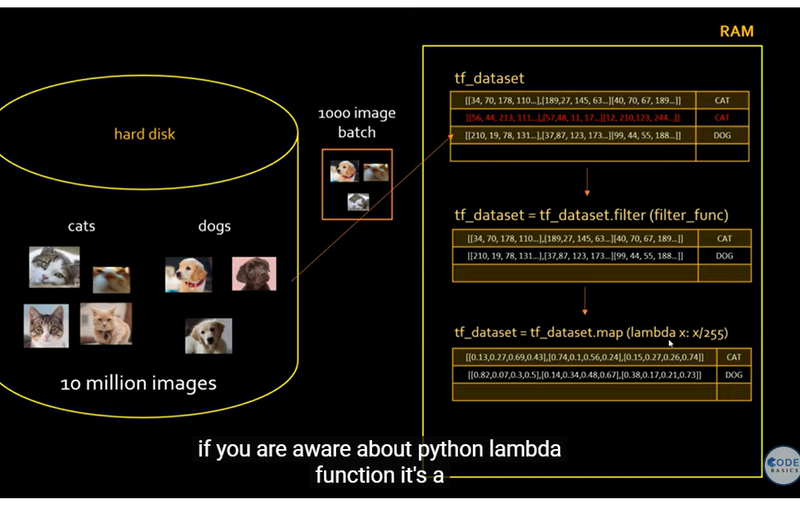
Filtering:
In the pipeline, the dataset can be filtered using specific criteria (e.g., using tf_dataset = tf_dataset.filter(filter_func)). This helps in selecting only relevant data, reducing the amount of unnecessary information processed, which can speed up training and reduce memory usage.
Mapping/Normalization:
The images show a map function applied to the dataset (e.g., tf_dataset = tf_dataset.map(lambda x: x/255)), which normalizes pixel values by dividing by 255. Normalization helps improve model performance and stability.
Mapping functions allow for efficient preprocessing, including resizing, cropping, and other transformations, which can be done on-the-fly during training.
Prefetching:
Although not explicitly shown, the pipeline can also include prefetching, where data for the next batch is loaded while the model is processing the current batch. Prefetching minimizes idle time and maximizes GPU utilization
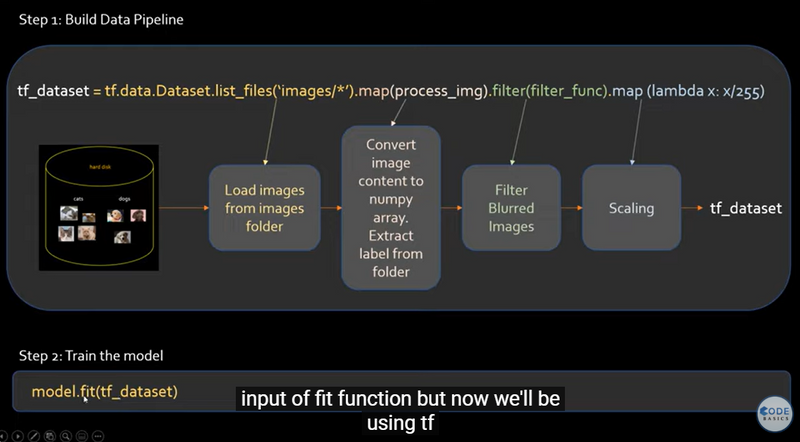
Coding Steps Example
Folder Structure

import tensorflow as tf
import numpy as np
import os
# Set parameters
IMG_SIZE = 128
BATCH_SIZE = 32
AUTOTUNE = tf.data.AUTOTUNE
class_names = ["cat", "dog"]
# Define function to get label from file path
def get_label(file_path):
parts = tf.strings.split(file_path, os.path.sep)
return parts[-2] == class_names # Converts class name to a binary label (0 or 1)
# Define function to process and load image
def process_image(file_path):
label = get_label(file_path)
img = tf.io.read_file(file_path) # Load image file as a string
img = tf.image.decode_jpeg(img, channels=3) # Decode as JPEG, RGB
img = tf.image.resize(img, [IMG_SIZE, IMG_SIZE]) # Resize image to target size
return img, label
# Define data augmentation functions
def augment_image(image, label):
image = tf.image.random_flip_left_right(image) # Random horizontal flip
image = tf.image.random_brightness(image, 0.2) # Random brightness
image = tf.image.random_contrast(image, 0.5, 1.5) # Random contrast
return image, label
# Define function to normalize and scale image
def scale_image(image, label):
image = image / 255.0 # Normalize pixel values to [0, 1]
return image, label
# Load the dataset and apply transformations
file_pattern = "images/*/*" # Path to the images folder with subfolders for each class
dataset = tf.data.Dataset.list_files(file_pattern, shuffle=True)
# Apply transformations in the pipeline
dataset = dataset.map(process_image, num_parallel_calls=AUTOTUNE) # Load and preprocess images
dataset = dataset.map(scale_image, num_parallel_calls=AUTOTUNE) # Scale images
dataset = dataset.cache() # Cache the dataset in memory
dataset = dataset.shuffle(buffer_size=1000) # Shuffle dataset with buffer
dataset = dataset.map(augment_image, num_parallel_calls=AUTOTUNE) # Apply data augmentation
dataset = dataset.batch(BATCH_SIZE) # Batch the dataset
dataset = dataset.prefetch(buffer_size=AUTOTUNE) # Prefetch to improve performance
# Split dataset into training and test sets
train_size = int(0.8 * len(dataset))
train_dataset = dataset.take(train_size)
test_dataset = dataset.skip(train_size)
# Example of iterating through the dataset
for images, labels in train_dataset.take(1):
print("Image batch shape:", images.shape)
print("Label batch shape:", labels.shape)
Explanation of Each Step
File Listing:
dataset = tf.data.Dataset.list_files(file_pattern, shuffle=True)
Loads file paths with tf.data.Dataset.list_files and shuffles the file order for randomness.
Process Image:
dataset = dataset.map(process_image, num_parallel_calls=AUTOTUNE)
Loads and resizes images to a consistent shape, extracting labels from directory structure.
Scale Image:
dataset = dataset.map(scale_image, num_parallel_calls=AUTOTUNE)
Scales pixel values to the [0, 1] range, which improves model convergence.
Caching:
dataset = dataset.cache()
Caches the dataset in memory after the first pass to avoid reloading from disk, speeding up subsequent epochs.
Shuffling:
dataset = dataset.shuffle(buffer_size=1000)
Shuffles images within a buffer, which is necessary for effective training and reducing bias.
Augmentation:
dataset = dataset.map(augment_image, num_parallel_calls=AUTOTUNE)
Applies random augmentations (flipping, brightness, and contrast adjustments) to increase data variability and improve model robustness.
Batching:
dataset = dataset.batch(BATCH_SIZE)
Groups images and labels into batches of size BATCH_SIZE, enabling efficient computation in each training step.
Prefetching:
dataset = dataset.prefetch(buffer_size=AUTOTUNE)
Prefetches the next batch while the current one is being processed, reducing idle time.
Running the Pipeline
When you run this code, the dataset will load, process, augment, and batch images efficiently, allowing you to feed a model without additional processing steps. This setup will improve training time and model performance, especially for large datasets.
Output Example
The output of the last loop will show the shape of the image and label batches:
Image batch shape: (32, 128, 128, 3)
Label batch shape: (32,)

Top comments (0)