To avoid overloading a website with too many requests in a short time and to space out your requests with appropriate delays, you can implement rate limiting or throttling in your web scraping script. Rate limiting controls the number of requests made per unit of time, and throttling introduces delays between requests. Here's how you can do it using Python and the time.sleep() function:
Determine an Appropriate Delay:
Calculate a delay that allows you to make requests at a reasonable rate. The specific delay will depend on the website's server capacity and their rate limits, if any.
Introduce Delays:
Use the time.sleep() function to introduce delays between requests. This function pauses the script for the specified number of seconds.
Example:
import time
# Set a delay of 2 seconds between requests
delay = 2
for page in range(1, 11):
# Make a request to the website
response = make_request(page)
# Process the response
# Introduce a delay before the next request
time.sleep(delay)
Randomize Delays (Optional):
To make your scraping less predictable and more similar to human behavior, you can randomize the delays within a certain range.
Example:
import time
import random
# Set a random delay between 1 and 3 seconds
min_delay = 1
max_delay = 3
for page in range(1, 11):
# Make a request to the website
response = make_request(page)
# Process the response
# Introduce a random delay before the next request
delay = random.uniform(min_delay, max_delay)
time.sleep(delay)
By introducing delays, you give the website's server time to handle your requests without overwhelming it. This helps ensure that your web scraping is more respectful and doesn't cause disruptions or server load issues. Keep in mind that the appropriate delay may vary from one website to another, so you may need to adjust it based on your observations and the website's policies.
=================================================================
There are a few things you can do to avoid overloading a website while scraping it:
Be polite. Don't scrape the website too quickly or too often. This can put a strain on the website's servers and make it difficult for other users to access the website.
Use a proxy server. A proxy server can help to distribute your traffic across multiple servers, which can help to reduce the load on the website you are scraping.
Respect the robots.txt file. The robots.txt file is a text file that tells web scrapers which pages on a website are allowed to be scraped and which ones are not. It is important to respect the robots.txt file to avoid getting your IP address blocked.
Use a headless browser. A headless browser is a browser that runs without a graphical user interface (GUI). This can make scraping websites more efficient and reduce the load on the website's servers.
Here are some specific examples of how to avoid overloading a website while scraping it:
Use a delay between requests. Don't send too many requests to the website at once. Instead, wait a few seconds between requests. You can use a library like requests to add a delay between requests in Python.
Only scrape the pages you need. Don't scrape the entire website if you only need a few pages. Instead, only scrape the pages that contain the data you need.
Use caching. Cache the pages that you scrape so that you don't have to scrape them again every time you need the data.
Use a cloud-based scraping service. There are a number of cloud-based scraping services that can help you to scrape websites without overloading them. These services typically use a large pool of servers to distribute the traffic across multiple servers.
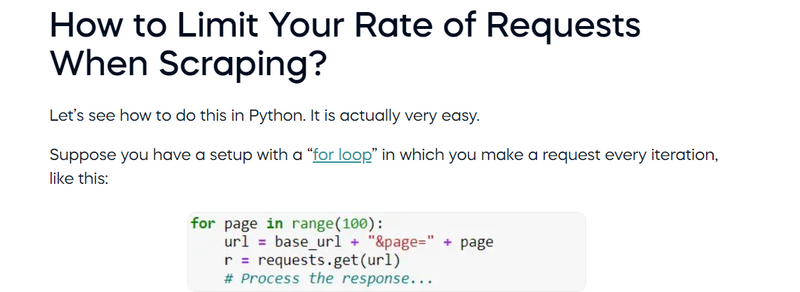
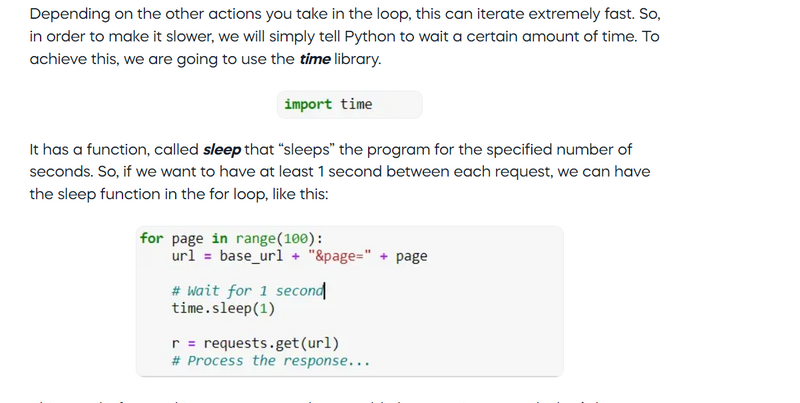
This way, before making a request, Python would always wait 1 second. That’s how we will avoid getting blocked and proceed with scraping the webpage.
Implement rate limiter
To implement a rate limiter in web scraping with Python, you can use the following steps:
Install the ratelimiter library.
Create a RateLimiter object with the desired rate limit.
Call the ratelimiter object's limit() method before making each request.
Handle any exceptions that are raised by the ratelimiter object.
Here is an example of how to implement a rate limiter in web scraping with Python:
import requests
from ratelimiter import RateLimiter
# Create a rate limiter object with a rate limit of 1 request per second
rate_limiter = RateLimiter(max_calls=1, period=1)
# Scrape the website
def scrape_website(url):
response = requests.get(url)
# Check if the rate limiter allows the request
if rate_limiter.limit():
# Make the request
return response.content
else:
# The rate limiter has blocked the request
raise Exception("Rate limit exceeded")
# Scrape the website
url = "https://www.example.com/"
content = scrape_website(url)
# Print the website content
print(content)

Top comments (0)