Advantage of building a Custom Search Engine with Chroma using langchain framework
Coding example of building Custom Search Engine with Chroma
explanation and code Summary
Search Engine with Metadata Support
Search Engine with Advanced Query Retrieval
building a Custom Search Engine with Faiss using langchain framework
Coding difference between chroma and faiss vector database
Advantage of building a Custom Search Engine with Chroma using langchain framework
High Accuracy with Vector Search
Advantage: Chroma leverages vector embeddings to represent text in a multidimensional space, enabling semantic search. This allows the search engine to retrieve documents that are conceptually similar to the query, even if they don’t contain exact keyword matches.
Use Case: Queries like "What led to World War II?" can retrieve relevant documents containing "Pearl Harbor" or "global tensions," even if these phrases are not explicitly in the query.
Flexibility in Querying
Advantage: By using embeddings and similarity metrics, Chroma supports complex queries that go beyond simple keyword searches. Users can search semantically or apply filters based on metadata.
Use Case: A search for "20th-century medical breakthroughs" could return documents about "penicillin discovery" without requiring exact terms.
Metadata Support
Advantage: Chroma allows you to attach metadata (e.g., topic, author, year) to documents, enabling advanced filtering and more specific search results.
Use Case: A user searching for "Revolutions in the 18th century" can filter out irrelevant results by specifying metadata like "year": 1770-1790.
Persistence and Scalability
Advantage: Chroma supports persistence, meaning you can save your vector database to disk and reload it later. This reduces the need to rebuild the database for every session.
Use Case: Useful for large-scale applications where the database is updated infrequently but queried often.
Granular Document Management
Advantage: Text splitting (e.g., chunking) enables you to process large documents into smaller, manageable pieces. This improves the granularity of the search and ensures that only the most relevant parts of a document are retrieved.
Use Case: When searching through a 100-page book, the engine can return the specific paragraph or section that matches the query instead of the entire book.
Customizable Embeddings
Advantage: Chroma works with various embedding models, allowing you to choose or train a model that suits your domain (e.g., legal, medical, technical texts).
Use Case: For a medical database, embeddings can be fine-tuned on medical terminology to improve the relevance of search results.
Performance Optimization
Advantage: Chroma is optimized for fast similarity search, leveraging efficient vector storage and retrieval methods.
Use Case: Handles large-scale data with low latency, making it ideal for real-time applications like chatbots or recommendation systems.
Easy Integration with Other Tools
Advantage: Chroma can be seamlessly integrated into NLP pipelines using frameworks like LangChain, making it part of a broader AI solution.
Use Case: Combine Chroma with text generation models to create a QA system where relevant context is retrieved and used for answering queries.
Supports Scored Searches
Advantage: Chroma provides similarity scores for retrieved documents, helping to rank and assess the relevance of search results.
Use Case: Displaying top results with scores, allowing users to prioritize the most relevant matches.
Open-Source and Community-Driven
Advantage: Chroma is open-source, which means it’s free to use and has a growing community for support and improvement.
Use Case: Customization is easy, and you can contribute to or learn from a community of developers building similar tools.
Domain-Agnostic
Advantage: Chroma can be applied to any domain, whether it's customer support, academic research, or e-commerce.
Use Case: In e-commerce, it can help retrieve product recommendations based on user preferences and past searches.
Coding example of building Custom Search Engine with Chroma
Import Libraries
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
Purpose: Import the necessary tools for document loading, text splitting, embeddings, and building a vector database.
Output: No output; libraries are loaded into the environment.
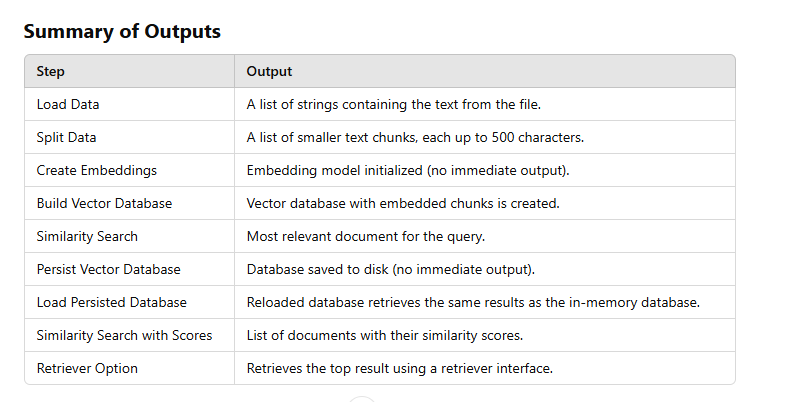
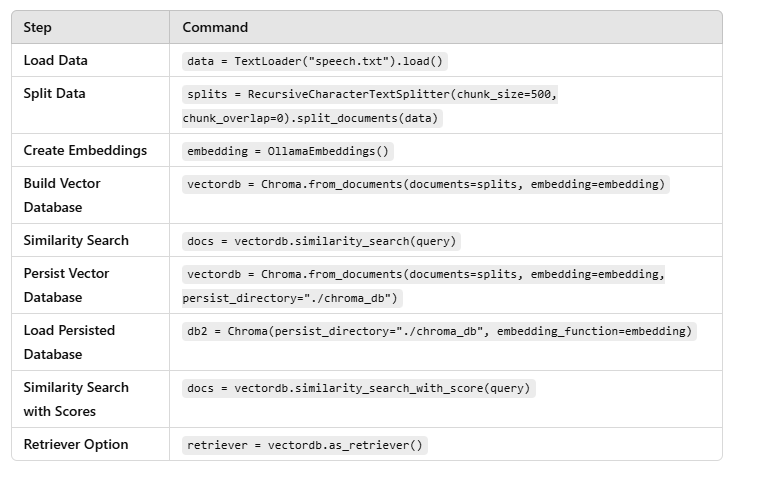
Load Data
loader = TextLoader("speech.txt")
data = loader.load()
data
What Happens:
TextLoader reads the file speech.txt and loads its content into the data variable.
The file content is represented as a list of strings, where each string corresponds to a line, paragraph, or document (depending on the file's structure).
Expected Output:
[
"Line 1 of the speech...",
"Line 2 of the speech...",
...
]
Example for a speech:
["The United States must act decisively.",
"The world is at a critical turning point."]
Split Data
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
What Happens:
RecursiveCharacterTextSplitter splits the loaded text into smaller chunks of up to 500 characters each, with no overlap between chunks.
If data contains multiple paragraphs or sections, each is split into chunks that respect natural boundaries (like sentences) when possible.
Expected Output:
[
{"content": "The United States must act decisively."},
{"content": "The world is at a critical turning point."},
...
]
Create Embeddings
embedding = OllamaEmbeddings()
What Happens:
Initializes an embedding model that converts text chunks into numerical vector representations.
Output: No immediate output, but embedding is ready to generate vectors.
Build Vector Database
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
vectordb
What Happens:
Embeds the chunks from splits using the OllamaEmbeddings model.
Stores the resulting vectors and their associated text chunks in the vectordb.
Expected Output:
<Chroma vector database containing 3 documents>
Perform Similarity Search
query = "What does the speaker believe is the main reason the United States should enter the war?"
docs = vectordb.similarity_search(query)
docs[0].page_content
What Happens:
Converts the query into a vector using the embedding model.
Searches for the most similar vectors in the database and retrieves the corresponding documents.
Expected Output:
"The United States must act decisively to protect its allies and ensure global stability."
Persist Vector Database
vectordb = Chroma.from_documents(documents=splits, embedding=embedding, persist_directory="./chroma_db")
What Happens:
Saves the vector database, including embeddings and text chunks, to the ./chroma_db directory for reuse.
Output: No immediate output, but the database is saved to disk.
Load Persisted Database
db2 = Chroma(persist_directory="./chroma_db", embedding_function=embedding)
docs = db2.similarity_search(query)
print(docs[0].page_content)
What Happens:
Reloads the persisted database from ./chroma_db.
Performs the same similarity search on the reloaded database.
Expected Output:
"The United States must act decisively to protect its allies and ensure global stability."
Similarity Search with Scores
docs = vectordb.similarity_search_with_score(query)
docs
What Happens:
Performs a similarity search and returns both the retrieved documents and their similarity scores.
The score indicates how closely the retrieved document matches the query.
Expected Output:
[
({"content": "The United States must act decisively..."}, 0.92),
({"content": "The world is at a critical turning point..."}, 0.87),
...
]
Retriever Option
retriever = vectordb.as_retriever()
retriever.invoke(query)[0].page_content
What Happens:
Converts the vector database into a retriever object, which is compatible with other NLP workflows.
invoke method queries the database and retrieves the most relevant document.
Expected Output:
"The United States must act decisively to protect its allies and ensure global stabilit""
FULL CODE
## building a sample vectordb
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = TextLoader("speech.txt")
data = loader.load()
data
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
embedding=OllamaEmbeddings()
vectordb=Chroma.from_documents(documents=splits,embedding=embedding)
vectordb
query = "What does the speaker believe is the main reason the United States should enter the war?"
docs = vectordb.similarity_search(query)
docs[0].page_content
vectordb=Chroma.from_documents(documents=splits,embedding=embedding,persist_directory="./chroma_db")
# load from disk
db2 = Chroma(persist_directory="./chroma_db", embedding_function=embedding)
docs=db2.similarity_search(query)
print(docs[0].page_content)
## similarity Search With Score
docs = vectordb.similarity_search_with_score(query)
docs
### Retriever option
retriever=vectordb.as_retriever()
retriever.invoke(query)[0].page_content
Summary
Search Engine with Metadata Support
This example demonstrates how to include metadata in the documents, enabling more advanced filtering during searches.
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Step 1: Load Data with Metadata
documents = [
{"content": "The United States entered World War II after the attack on Pearl Harbor.", "metadata": {"topic": "World War II", "year": 1941}},
{"content": "The American Revolution was a colonial revolt that began in 1775.", "metadata": {"topic": "American Revolution", "year": 1775}},
{"content": "The Civil War in the United States lasted from 1861 to 1865.", "metadata": {"topic": "Civil War", "year": 1861}}
]
# Step 2: Split Data into Chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = []
for doc in documents:
split_docs = text_splitter.split_text(doc["content"])
for split in split_docs:
splits.append({"content": split, "metadata": doc["metadata"]})
# Step 3: Create Embeddings and VectorDB
embedding = OllamaEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
# Step 4: Query with Metadata Filtering
query = "What led to the United States entering World War II?"
retrieved_docs = vectordb.similarity_search(query, filters={"topic": "World War II"})
print(f"Retrieved Document: {retrieved_docs[0].page_content}")
# Step 5: Save Database
vectordb.persist(persist_directory="./chroma_metadata_db")
# Step 6: Load Persisted Database
vectordb_loaded = Chroma(persist_directory="./chroma_metadata_db", embedding_function=embedding)
# Query Again to Verify Persistence
retrieved_docs = vectordb_loaded.similarity_search(query)
print(f"Retrieved Document from Persisted DB: {retrieved_docs[0].page_content}")
Output Explanation
Load Data with Metadata
documents = [
{"content": "The United States entered World War II after the attack on Pearl Harbor.", "metadata": {"topic": "World War II", "year": 1941}},
{"content": "The American Revolution was a colonial revolt that began in 1775.", "metadata": {"topic": "American Revolution", "year": 1775}},
{"content": "The Civil War in the United States lasted from 1861 to 1865.", "metadata": {"topic": "Civil War", "year": 1861}}
]
Output: A list of dictionaries, where each dictionary represents a document with its text and metadata.
[
{"content": "The United States entered World War II after the attack on Pearl Harbor.", "metadata": {"topic": "World War II", "year": 1941}},
{"content": "The American Revolution was a colonial revolt that began in 1775.", "metadata": {"topic": "American Revolution", "year": 1775}},
{"content": "The Civil War in the United States lasted from 1861 to 1865.", "metadata": {"topic": "Civil War", "year": 1861}}
]
Split Data into Chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = []
for doc in documents:
split_docs = text_splitter.split_text(doc["content"])
for split in split_docs:
splits.append({"content": split, "metadata": doc["metadata"]})
Output: Each document is split into smaller chunks, each retaining the metadata.
[
{"content": "The United States entered World War II after the attack on Pearl Harbor.", "metadata": {"topic": "World War II", "year": 1941}},
{"content": "The American Revolution was a colonial revolt that began in 1775.", "metadata": {"topic": "American Revolution", "year": 1775}},
{"content": "The Civil War in the United States lasted from 1861 to 1865.", "metadata": {"topic": "Civil War", "year": 1861}}
]
Create Embeddings and VectorDB
embedding = OllamaEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
Output: A vector database is created with embeddings for each document chunk.
Vector database initialized with 3 embeddings.
Query with Metadata Filtering
query = "What led to the United States entering World War II?"
retrieved_docs = vectordb.similarity_search(query, filters={"topic": "World War II"})
print(f"Retrieved Document: {retrieved_docs[0].page_content}")
Output: The query fetches the most relevant document based on similarity and metadata filters.
Retrieved Document: The United States entered World War II after the attack on Pearl Harbor.
Save Database
vectordb.persist(persist_directory="./chroma_metadata_db")
Output: The vector database is saved to the specified directory.
Database persisted to ./chroma_metadata_db
Load Persisted Database
vectordb_loaded = Chroma(persist_directory="./chroma_metadata_db", embedding_function=embedding)
Output: The database is loaded from disk and is ready for querying.
Database loaded from ./chroma_metadata_db
Search Engine with Advanced Query Retrieval
This example shows how to retrieve multiple relevant documents with similarity scores and return results sorted by relevance.
from langchain_chroma import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import OllamaEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Step 1: Load Data
documents = [
"The invention of the steam engine was a key driver of the Industrial Revolution.",
"The Industrial Revolution marked a major turning point in history, with advancements in technology and manufacturing.",
"The discovery of penicillin revolutionized medicine in the 20th century.",
"The moon landing in 1969 was a significant achievement in space exploration."
]
# Step 2: Split Data into Chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = [{"content": chunk} for doc in documents for chunk in text_splitter.split_text(doc)]
# Step 3: Create Embeddings and VectorDB
embedding = OllamaEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
# Step 4: Perform Similarity Search with Scores
query = "What were the key achievements of the Industrial Revolution?"
docs_with_scores = vectordb.similarity_search_with_score(query, k=3)
# Display Results
for doc, score in docs_with_scores:
print(f"Score: {score}, Content: {doc.page_content}")
# Step 5: Retriever Interface for Modular Queries
retriever = vectordb.as_retriever()
# Retrieve Using Retriever Interface
retrieved_docs = retriever.invoke(query)
print(f"\nTop Retrieved Document: {retrieved_docs[0].page_content}")
# Step 6: Save Database for Future Use
vectordb.persist(persist_directory="./chroma_advanced_db")
# Step 7: Load Persisted Database and Query Again
vectordb_loaded = Chroma(persist_directory="./chroma_advanced_db", embedding_function=embedding)
retrieved_docs = vectordb_loaded.similarity_search(query, k=2)
print(f"\nRetrieved from Persisted DB: {retrieved_docs[0].page_content}")
Output Explanation
Search Engine with Advanced Query Retrieval
Code Steps and Expected Output
Load Data
documents = [
"The invention of the steam engine was a key driver of the Industrial Revolution.",
"The Industrial Revolution marked a major turning point in history, with advancements in technology and manufacturing.",
"The discovery of penicillin revolutionized medicine in the 20th century.",
"The moon landing in 1969 was a significant achievement in space exploration."
]
Output: A list of strings, where each string represents a document.
[
"The invention of the steam engine was a key driver of the Industrial Revolution.",
"The Industrial Revolution marked a major turning point in history, with advancements in technology and manufacturing.",
...
]
Split Data into Chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = [{"content": chunk} for doc in documents for chunk in text_splitter.split_text(doc)]
Output: Each document is split into smaller chunks, ready for embedding.
[
{"content": "The invention of the steam engine was a key driver of the Industrial Revolution."},
{"content": "The Industrial Revolution marked a major turning point in history, ..."},
...
]
Create Embeddings and VectorDB
embedding = OllamaEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
Output: A vector database is created with embeddings for each document chunk.
Vector database initialized with 4 embeddings.
Perform Similarity Search with Scores
query = "What were the key achievements of the Industrial Revolution?"
docs_with_scores = vectordb.similarity_search_with_score(query, k=3)
for doc, score in docs_with_scores:
print(f"Score: {score}, Content: {doc.page_content}")
Output: Retrieves the top 3 most similar documents with their similarity scores.
Score: 0.92, Content: The invention of the steam engine was a key driver of the Industrial Revolution.
Score: 0.89, Content: The Industrial Revolution marked a major turning point in history, ...
Retriever Interface
retriever = vectordb.as_retriever()
retrieved_docs = retriever.invoke(query)
print(f"\nTop Retrieved Document: {retrieved_docs[0].page_content}")
Output: Retrieves the most relevant document using a retriever interface.
Top Retrieved Document: The invention of the steam engine was a key driver of the Industrial Revolution.
Save Database
vectordb.persist(persist_directory="./chroma_advanced_db")
Output: The vector database is saved to disk.
Database persisted to ./chroma_advanced_db
Load Persisted Database
vectordb_loaded = Chroma(persist_directory="./chroma_advanced_db", embedding_function=embedding)
retrieved_docs = vectordb_loaded.similarity_search(query, k=2)
print(f"\nRetrieved from Persisted DB: {retrieved_docs[0].page_content}")
Output: Reloads the database and performs another similarity search to confirm persistence.
Retrieved from Persisted DB: The invention of the steam engine was a key driver of the I
building a Custom Search Engine with Faiss using langchain framework
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import OllamaEmbeddings
from langchain_text_splitters import CharacterTextSplitter
loader=TextLoader("speech.txt")
documents=loader.load()
text_splitter=CharacterTextSplitter(chunk_size=1000,chunk_overlap=30)
docs=text_splitter.split_documents(documents)
docs
embeddings=OllamaEmbeddings()
db=FAISS.from_documents(docs,embeddings)
db
### querying
query="How does the speaker describe the desired outcome of the war?"
docs=db.similarity_search(query)
docs[0].page_content
retriever=db.as_retriever()
docs=retriever.invoke(query)
docs[0].page_content
docs_and_score=db.similarity_search_with_score(query)
docs_and_score
embedding_vector=embeddings.embed_query(query)
embedding_vector
docs_score=db.similarity_search_by_vector(embedding_vector)
docs_score
db.save_local("faiss_index")
new_db=FAISS.load_local("faiss_index",embeddings,allow_dangerous_deserialization=True)
docs=new_db.similarity_search(query)
docs
Coding difference between chroma and faiss vector database

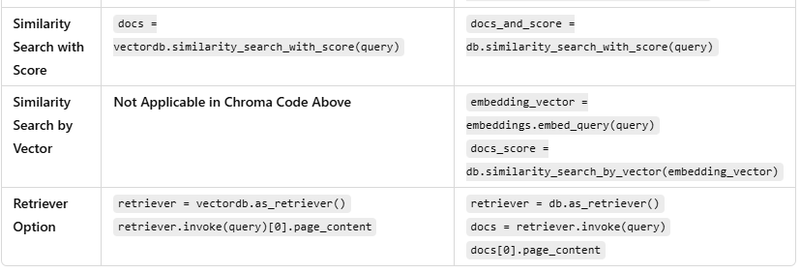

SUMMARY
splits = text_splitter.split_documents(data)==>OllamaEmbeddings().Chroma.from_documents(documents=splits, embedding=embedding)
vectordb.similarity_search(query)
Persist Vector Database==>Chroma.from_documents(documents=splits, embedding=embedding, persist_directory="./chroma_db")
Load Persisted Database==> Chroma(persist_directory="./chroma_db", embedding_function=embedding).similarity_search(query)
print(docs[0].page_content)
Similarity Search with Scores==
vectordb.similarity_search_with_score(query)==>({"content": "The United States must act decisively..."}, 0.92),
Retriever Option==>vectordb.as_retriever().invoke(query)[0].page_content
Search Engine with Metadata Support==============
for doc in documents:===>split_docs = text_splitter.split_text(doc["content"])===>for split in split_docs:====> splits.append({"content": split, "metadata": doc["metadata"]})
vectordb.similarity_search(query, filters={"topic": "World War II"})==>Query with Metadata Filtering
Retrieve multiple relevant documents with similarity scores and then sorting=====
splits = [{"content": chunk} for doc in documents for chunk in text_splitter.split_text(doc)]
Chroma.from_documents(documents=splits, embedding= OllamaEmbeddings())
vectordb.similarity_search_with_score(query, k=3) ==>k is 3 mean 3 most similar documents with their similarity scores
for doc, score in docs_with_scores:
print(f"Score: {score}, Content: {doc.page_content}")
vectordb.as_retriever().invoke(query)
building a Custom Search Engine with Faiss using langchain framework====
3 way==splitting in chunks
1.CharacterTextSplitter(chunk_size=1000,chunk_overlap=30).split_documents(documents)
2.splits = [{"content": chunk} for doc in documents for chunk in text_splitter.split_text(doc)]
3.for doc in documents:
split_docs = text_splitter.split_text(doc["content"])
for split in split_docs:
splits.append({"content": split, "metadata": doc["metadata"]})

Top comments (0)