How to extract list of element using chunk parameter
More Info about chunk details
How to split data and filtering with langchain and json
Transforming JSON into User-Friendly json Formats using text-splitting
Transforming JSON into into Multiple Formats after text-splitting
How to extract list of element using chunk parameter
from langchain.text_splitters import HTMLHeaderTextSplitter
# Example HTML content for testing
html_content = """
<h1>Introduction</h1>
<p>LangChain is a powerful tool for developing applications with LLMs. It provides utilities for text splitting, document processing, and more.</p>
<h2>Getting Started</h2>
<p>To get started with LangChain, you need to install it using pip. Here's how you can do it:</p>
<h2>Advanced Usage</h2>
<p>In addition to basic usage, LangChain also provides advanced features for handling large documents efficiently.</p>
<h3>Chunking Details</h3>
<p>This section explains how to split large texts into manageable chunks that can be processed easily.</p>
<h3>Additional Features</h3>
<p>LangChain has many features for automating text processing tasks like sentiment analysis, summarization, and more.</p>
<h2>Examples</h2>
<p>Examples of LangChain usage include automatic content extraction, summarization, and text analysis.</p>
"""
# Custom parameters for splitting
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
chunk_size = 100
chunk_overlap = 20
separator = "\n\n"
min_chunk_size = 50
max_chunks = 10
sentence_boundary = True
preserve_formatting = True
paragraph_boundary = True
tokenizer = None # This would be a custom tokenizer if required
exclude_headers = ["h3"]
split_on_emojis = False
chunk_numbering = True
custom_separators = ["###", "---", "**"]
metadata_in_chunks = True
# Initialize the HTMLHeaderTextSplitter with all the custom parameters
html_splitter = HTMLHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator=separator,
min_chunk_size=min_chunk_size,
max_chunks=max_chunks,
sentence_boundary=sentence_boundary,
preserve_formatting=preserve_formatting,
paragraph_boundary=paragraph_boundary,
tokenizer=tokenizer,
exclude_headers=exclude_headers,
split_on_emojis=split_on_emojis,
chunk_numbering=chunk_numbering,
custom_separators=custom_separators,
metadata_in_chunks=metadata_in_chunks,
)
# Split the text using the custom parameters
chunks = html_splitter.split_text(html_content)
# Output the chunks with metadata
for chunk in chunks:
print(f"Chunk {chunk['chunk_index']}:")
print(chunk['content'])
print(f"Metadata: {chunk['metadata']}")
print("----------")

Chunk 1:
<h1>Introduction</h1>
<p>LangChain is a powerful tool for developing applications with LLMs. It provides utilities for text splitting, document processing, and more.</p>
Metadata: {'chunk_index': 1, 'header': 'Header 1', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk 2:
<h2>Getting Started</h2>
<p>To get started with LangChain, you need to install it using pip. Here's how you can do it:</p>
Metadata: {'chunk_index': 2, 'header': 'Header 2', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk 3:
<h2>Advanced Usage</h2>
<p>In addition to basic usage, LangChain also provides advanced features for handling large documents efficiently.</p>
Metadata: {'chunk_index': 3, 'header': 'Header 2', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk 4:
<h3>Chunking Details</h3>
<p>This section explains how to split large texts into manageable chunks that can be processed easily.</p>
Metadata: {'chunk_index': 4, 'header': 'Header 3', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk 5:
<h3>Additional Features</h3>
<p>LangChain has many features for automating text processing tasks like sentiment analysis, summarization, and more.</p>
Metadata: {'chunk_index': 5, 'header': 'Header 3', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk 6:
<h2>Examples</h2>
<p>Examples of LangChain usage include automatic content extraction, summarization, and text analysis.</p>
Metadata: {'chunk_index': 6, 'header': 'Header 2', 'chunk_size': 100, 'preserve_formatting': True}
----------

Another Way using append
from langchain.text_splitters import HTMLHeaderTextSplitter
# Example HTML content for testing
html_content = """
<h1>Introduction</h1>
<p>LangChain is a powerful tool for developing applications with LLMs. It provides utilities for text splitting, document processing, and more.</p>
<h2>Getting Started</h2>
<p>To get started with LangChain, you need to install it using pip. Here's how you can do it:</p>
<h2>Advanced Usage</h2>
<p>In addition to basic usage, LangChain also provides advanced features for handling large documents efficiently.</p>
<h3>Chunking Details</h3>
<p>This section explains how to split large texts into manageable chunks that can be processed easily.</p>
<h3>Additional Features</h3>
<p>LangChain has many features for automating text processing tasks like sentiment analysis, summarization, and more.</p>
<h2>Examples</h2>
<p>Examples of LangChain usage include automatic content extraction, summarization, and text analysis.</p>
"""
# Custom parameters for splitting
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
chunk_size = 100
chunk_overlap = 20
separator = "\n\n"
min_chunk_size = 50
max_chunks = 10
sentence_boundary = True
preserve_formatting = True
paragraph_boundary = True
tokenizer = None # This would be a custom tokenizer if required
exclude_headers = ["h3"]
split_on_emojis = False
chunk_numbering = True
custom_separators = ["###", "---", "**"]
metadata_in_chunks = True
# Initialize the HTMLHeaderTextSplitter with all the custom parameters
html_splitter = HTMLHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separator=separator,
min_chunk_size=min_chunk_size,
max_chunks=max_chunks,
sentence_boundary=sentence_boundary,
preserve_formatting=preserve_formatting,
paragraph_boundary=paragraph_boundary,
tokenizer=tokenizer,
exclude_headers=exclude_headers,
split_on_emojis=split_on_emojis,
chunk_numbering=chunk_numbering,
custom_separators=custom_separators,
metadata_in_chunks=metadata_in_chunks,
)
# Split the text using the custom parameters
chunks = html_splitter.split_text(html_content)
# Collect chunks in a list and print it in a structured way
chunk_details = []
for chunk in chunks:
chunk_info = {
"Chunk Index": chunk["chunk_index"],
"Content": chunk["content"],
"Metadata": chunk["metadata"]
}
chunk_details.append(chunk_info)
# Now list out all chunks
for chunk_info in chunk_details:
print(f"Chunk Index: {chunk_info['Chunk Index']}")
print(f"Content: {chunk_info['Content']}")
print(f"Metadata: {chunk_info['Metadata']}")
print("----------")
output
Chunk Index: 1
Content: <h1>Introduction</h1>
<p>LangChain is a powerful tool for developing applications with LLMs. It provides utilities for text splitting, document processing, and more.</p>
Metadata: {'chunk_index': 1, 'header': 'Header 1', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk Index: 2
Content: <h2>Getting Started</h2>
<p>To get started with LangChain, you need to install it using pip. Here's how you can do it:</p>
Metadata: {'chunk_index': 2, 'header': 'Header 2', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk Index: 3
Content: <h2>Advanced Usage</h2>
<p>In addition to basic usage, LangChain also provides advanced features for handling large documents efficiently.</p>
Metadata: {'chunk_index': 3, 'header': 'Header 2', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk Index: 4
Content: <h3>Chunking Details</h3>
<p>This section explains how to split large texts into manageable chunks that can be processed easily.</p>
Metadata: {'chunk_index': 4, 'header': 'Header 3', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk Index: 5
Content: <h3>Additional Features</h3>
<p>LangChain has many features for automating text processing tasks like sentiment analysis, summarization, and more.</p>
Metadata: {'chunk_index': 5, 'header': 'Header 3', 'chunk_size': 100, 'preserve_formatting': True}
----------
Chunk Index: 6
Content: <h2>Examples</h2>
<p>Examples of LangChain usage include automatic content extraction, summarization, and text analysis.</p>
Metadata: {'chunk_index': 6, 'header': 'Header 2', 'chunk_size': 100, 'preserve_formatting': True}
----------
More Info about Chunk Details
Here’s a list of potential chunk details that can be helpful for more advanced chunking scenarios:
Start and End Index:
start_index: The position (index) where the chunk begins in the original text.
end_index: The position (index) where the chunk ends in the original text.
These indices are useful if you want to track the exact locations of each chunk within the original text.
"Start Index": chunk["start_index"],
"End Index": chunk["end_index"]
- Text Length: chunk_length: The length of the chunk in terms of characters or tokens. This provides insight into how much content is being processed in each chunk, which can help you ensure chunks are not too large or small.
"Chunk Length": len(chunk["content"])
- Header: header: The specific header that the chunk starts with (e.g., h1, h2, h3). This is particularly useful when splitting HTML content, as it tells you under which header a chunk begins.
"Header": chunk["header"]
- Sentence Count: sentence_count: The number of sentences in the chunk, useful when sentence-level splitting is enabled. This provides more detailed information on the structure of each chunk.
"Sentence Count": chunk["sentence_count"]
- Word Count: word_count: The total number of words in the chunk. This is particularly useful for analyzing the chunk size in terms of words rather than characters.
"Word Count": len(chunk["content"].split())
- Token Count: token_count: The number of tokens in the chunk (if you're using token-based splitting). This is useful in scenarios where you're processing text with NLP models that work at the token level.
"Token Count": len(chunk["tokens"]) # Assuming `tokens` is available
- Paragraphs: paragraphs: The number of paragraphs in the chunk (if paragraph-based splitting is enabled). This provides insight into how much paragraph-level content is in the chunk.
"Paragraphs": chunk["paragraph_count"]
- Formatted Content (Preserved Formatting): formatted_content: The original HTML or markdown content if preserve_formatting=True. This ensures the original formatting (like HTML tags, bold, italics) is retained.
"Formatted Content": chunk["formatted_content"] # Assuming the chunk stores formatted content
- Custom Separators: used_separators: The specific separator(s) used to split the chunk. This is useful if you're using custom separators like ###, **, or other markers.
"Used Separators": chunk["used_separators"]
- Metadata Tags: metadata_tags: Custom tags associated with the chunk, like source information, author, or document title. This can be helpful for categorizing or tagging chunks based on metadata from the source document.
"Metadata Tags": chunk["metadata_tags"]
- Chunk Sequence Number: chunk_number: The sequence number of the chunk in a series of chunks, especially useful if chunk_numbering=True.
"Chunk Number": chunk["chunk_number"]
- Source or Filename: source_filename: If chunks are derived from files, this can store the filename or source location.
"Source Filename": chunk["source_filename"]
- Emojis/Language Detected: emojis_detected: If split_on_emojis=True, it could provide the detected emojis used as separators. language_detected: In multilingual content, you might store the language detected in the chunk.
"Emojis Detected": chunk["emojis_detected"],
"Language Detected": chunk["language_detected"]
-
Custom Data: custom_data: If any custom data or transformations are applied during chunking, this field could store additional details.
"Custom Data": chunk["custom_data"]
Example Code to List More Chunk Details:
Here's an example showing how you could print out more details for each chunk:
for chunk in chunks:
chunk_info = {
"Chunk Index": chunk["chunk_index"],
"Content": chunk["content"],
"Metadata": chunk["metadata"],
"Start Index": chunk.get("start_index", "N/A"),
"End Index": chunk.get("end_index", "N/A"),
"Chunk Length": len(chunk["content"]),
"Header": chunk.get("header", "N/A"),
"Sentence Count": chunk.get("sentence_count", "N/A"),
"Word Count": len(chunk["content"].split()),
"Token Count": len(chunk.get("tokens", [])),
"Paragraphs": chunk.get("paragraph_count", "N/A"),
"Formatted Content": chunk.get("formatted_content", "N/A"),
"Used Separators": chunk.get("used_separators", "N/A"),
"Metadata Tags": chunk.get("metadata_tags", "N/A"),
"Chunk Number": chunk.get("chunk_number", "N/A"),
"Source Filename": chunk.get("source_filename", "N/A"),
"Emojis Detected": chunk.get("emojis_detected", "N/A"),
"Language Detected": chunk.get("language_detected", "N/A"),
"Custom Data": chunk.get("custom_data", "N/A"),
}
print(f"Chunk Index: {chunk_info['Chunk Index']}")
print(f"Content: {chunk_info['Content']}")
print(f"Metadata: {chunk_info['Metadata']}")
print(f"Start Index: {chunk_info['Start Index']}")
print(f"End Index: {chunk_info['End Index']}")
print(f"Chunk Length: {chunk_info['Chunk Length']}")
print(f"Header: {chunk_info['Header']}")
print(f"Sentence Count: {chunk_info['Sentence Count']}")
print(f"Word Count: {chunk_info['Word Count']}")
print(f"Token Count: {chunk_info['Token Count']}")
print(f"Paragraphs: {chunk_info['Paragraphs']}")
print(f"Formatted Content: {chunk_info['Formatted Content']}")
print(f"Used Separators: {chunk_info['Used Separators']}")
print(f"Metadata Tags: {chunk_info['Metadata Tags']}")
print(f"Chunk Number: {chunk_info['Chunk Number']}")
print(f"Source Filename: {chunk_info['Source Filename']}")
print(f"Emojis Detected: {chunk_info['Emojis Detected']}")
print(f"Language Detected: {chunk_info['Language Detected']}")
print(f"Custom Data: {chunk_info['Custom Data']}")
print("----------")
How to split data and filtering with langchain and json
import pandas as pd
from langchain.text_splitters import JsonTextSplitter
# Example JSON data
json_data = [
{
"content": {
"order_id": 101,
"items": [
{"item_id": 1, "name": "Laptop", "price": 1200},
{"item_id": 2, "name": "Mouse", "price": 25}
]
}
},
{
"content": {
"order_id": 102,
"items": [
{"item_id": 3, "name": "Keyboard", "price": 50},
{"item_id": 4, "name": "Monitor", "price": 1500}
]
}
}
]
# Use JsonTextSplitter to split based on 'content' key
chunk_key = "content"
json_splitter = JsonTextSplitter(chunk_key=chunk_key)
chunks = json_splitter.split_text(json_data)
# Filter items with price more than 1000
filtered_items = []
for chunk in chunks:
order_data = chunk.get("content", {})
items = order_data.get("items", [])
# Apply filter: price > 1000
for item in items:
if item["price"] > 1000:
filtered_items.append(item)
# Convert filtered data into a pandas DataFrame to display as a table
df = pd.DataFrame(filtered_items)
# Display the table
import ace_tools as tools; tools.display_dataframe_to_user(name="Filtered Items Table", dataframe=df)
print("Filtered Items (Price > 1000):")
print(df)
Output
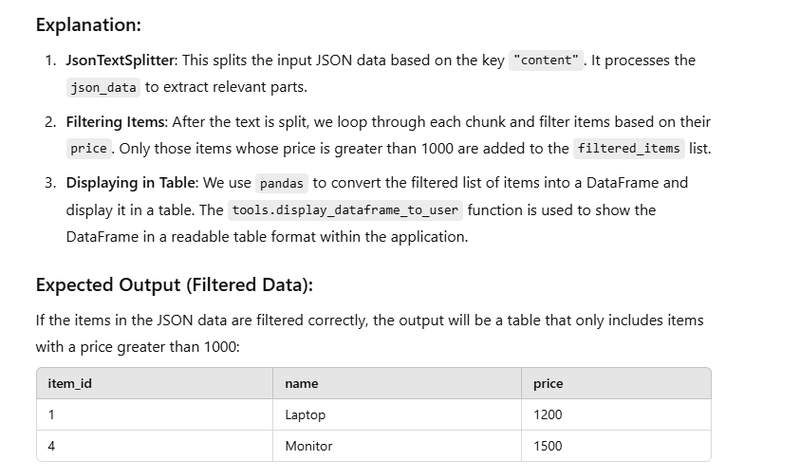
convert nested json data
from langchain_text_splitters import RecursiveJsonSplitter
import json
# Given JSON data
openapi_data = {
'openapi': '3.1.0',
'info': {'title': 'LangSmith', 'version': '0.1.0'},
'paths': {
'/api/v1/sessions/{session_id}': {
'get': {
'tags': ['tracer-sessions'],
'summary': 'Read Tracer Session',
'description': 'Get a specific session.',
'operationId': 'read_tracer_session_api_v1_sessions__session_id__get',
'security': [
{'API Key': []},
{'Tenant ID': []},
{'Bearer Auth': []},
{'API Key': []}
],
'parameters': [
{'name': 'session_id', 'in': 'path', 'required': True, 'schema': {'type': 'string', 'format': 'uuid', 'title': 'Session Id'}},
{'name': 'include_stats', 'in': 'query', 'required': False, 'schema': {'type': 'boolean', 'default': False, 'title': 'Include Stats'}},
{'name': 'accept', 'in': 'header', 'required': False, 'schema': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'title': 'Accept'}}
],
'responses': {
'200': {
'description': 'Successful Response',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/TracerSession'}}}
},
'422': {
'description': 'Validation Error',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/HTTPValidationError'}}}
}
}
},
'patch': {
'tags': ['tracer-sessions'],
'summary': 'Update Tracer Session',
'description': 'Create a new session.',
'operationId': 'update_tracer_session_api_v1_sessions__session_id__patch',
'security': [
{'API Key': []},
{'Tenant ID': []},
{'Bearer Auth': []},
{'API Key': []}
],
'parameters': [
{'name': 'session_id', 'in': 'path', 'required': True, 'schema': {'type': 'string', 'format': 'uuid', 'title': 'Session Id'}}
],
'requestBody': {
'required': True,
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/TracerSessionUpdate'}}}
},
'responses': {
'200': {
'description': 'Successful Response',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/TracerSessionWithoutVirtualFields'}}}
},
'422': {
'description': 'Validation Error',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/HTTPValidationError'}}}
}
}
},
'delete': {
'tags': ['tracer-sessions'],
'summary': 'Delete Tracer Session',
'description': 'Delete a specific session.',
'operationId': 'delete_tracer_session_api_v1_sessions__session_id__delete',
'security': [
{'API Key': []},
{'Tenant ID': []},
{'Bearer Auth': []},
{'API Key': []}
],
'parameters': [
{'name': 'session_id', 'in': 'path', 'required': True, 'schema': {'type': 'string', 'format': 'uuid', 'title': 'Session Id'}}
],
'responses': {
'200': {
'description': 'Successful Response',
'content': {'application/json': {'schema': {}}}
},
'422': {
'description': 'Validation Error',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/HTTPValidationError'}}}
}
}
}
},
'/api/v1/sessions': {
'get': {
'tags': ['tracer-sessions'],
'summary': 'Read Tracer Sessions',
'description': 'Get all sessions.',
'operationId': 'read_tracer_sessions_api_v1_sessions_get',
'security': [
{'API Key': []},
{'Tenant ID': []},
{'Bearer Auth': []},
{'API Key': []}
],
'parameters': [
{'name': 'reference_free', 'in': 'query', 'required': False, 'schema': {'anyOf': [{'type': 'boolean'}, {'type': 'null'}], 'title': 'Reference Free'}},
{'name': 'reference_dataset', 'in': 'query', 'required': False, 'schema': {'anyOf': [{'type': 'array', 'items': {'type': 'string', 'format': 'uuid'}}, {'type': 'null'}], 'title': 'Reference Dataset'}},
{'name': 'id', 'in': 'query', 'required': False, 'schema': {'anyOf': [{'type': 'array', 'items': {'type': 'string', 'format': 'uuid'}}, {'type': 'null'}], 'title': 'Id'}},
{'name': 'name', 'in': 'query', 'required': False, 'schema': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'title': 'Name'}},
{'name': 'name_contains', 'in': 'query', 'required': False, 'schema': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'title': 'Name Contains'}},
{'name': 'dataset_version', 'in': 'query', 'required': False, 'schema': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'title': 'Dataset Version'}},
{'name': 'sort_by', 'in': 'query', 'required': False, 'schema': {'allOf': [{'$ref': '#/components/schemas/SessionSortableColumns'}], 'default': 'start_time', 'title': 'Sort By'}},
{'name': 'sort_by_desc', 'in': 'query', 'required': False, 'schema': {'type': 'boolean', 'default': True, 'title': 'Sort By Desc'}},
{'name': 'sort_by_feedback_key', 'in': 'query', 'required': False, 'schema': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'title': 'Sort By Feedback Key'}},
{'name': 'offset', 'in': 'query', 'required': False, 'schema': {'type': 'integer', 'minimum': 0, 'default': 0, 'title': 'Offset'}},
{'name': 'limit', 'in': 'query', 'required': False, 'schema': {'type': 'integer', 'maximum': 100, 'minimum': 1, 'default': 100, 'title': 'Limit'}},
{'name': 'facets', 'in': 'query', 'required': False, 'schema': {'type': 'boolean', 'default': False, 'title': 'Facets'}},
{'name': 'accept', 'in': 'header', 'required': False, 'schema': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'title': 'Accept'}}
],
'responses': {
'200': {
'description': 'Successful Response',
'content': {'application/json': {'schema': {'type': 'array', 'items': {'$ref': '#/components/schemas/TracerSession'}, 'title': 'Response Read Tracer Sessions Api V1 Sessions Get'}}}
},
'422': {
'description': 'Validation Error',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/HTTPValidationError'}}}
}
}
},
'post': {
'tags': ['tracer-sessions'],
'summary': 'Create Tracer Session',
'description': 'Create a new session.',
'operationId': 'create_tracer_session_api_v1_sessions_post',
'security': [
{'API Key': []},
{'Tenant ID': []},
{'Bearer Auth': []},
{'API Key': []}
],
'parameters': [
{'name': 'upsert', 'in': 'query', 'required': False, 'schema': {'type': 'boolean', 'default': False, 'title': 'Upsert'}}
],
'requestBody': {
'required': True,
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/TracerSessionCreate'}}}
},
'responses': {
'200': {
'description': 'Successful Response',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/TracerSessionWithoutVirtualFields'}}}
},
'422': {
'description': 'Validation Error',
'content': {'application/json': {'schema': {'$ref': '#/components/schemas/HTTPValidationError'}}}
}
}
}
}
}
}
from langchain_text_splitters import RecursiveJsonSplitter
json_splitter=RecursiveJsonSplitter(max_chunk_size=300)
json_chunks=json_splitter.split_json(json_data)
json_chunks
output
[
{
"id": 1,
"name": "Item 1",
"details": "Some details here",
...
},
{
"id": 2,
"name": "Item 2",
"details": "Some more details here",
...
},
...
]
for chunk in json_chunks[:3]:
print(chunk)
Expected Output:
This loop will print the first three chunks of the json_chunks list. Each chunk will be a portion of the original JSON data, and each chunk will have a size not exceeding 300 characters. Here's an example of what it might look like if the chunks contain dictionary-like structures:
{
"id": 1,
"name": "Item 1",
"description": "Some description here",
"other_field": "Details of the item"
}
{
"id": 2,
"name": "Item 2",
"description": "Another description here",
"other_field": "Additional details"
}
{
"id": 3,
"name": "Item 3",
"description": "Yet another description",
"other_field": "Further details"
}
Transforming JSON into User-Friendly Formats using text-splitting
from langchain.text_splitters import RecursiveCharacterTextSplitter
import datetime
# Sample JSON Data
json_data = [
{"title": "Introduction", "content": "LangChain is a library for large language model applications."},
{"title": "Getting Started", "content": "This section covers installation and setup."},
{"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more."},
{"title": "Examples", "content": "Here we show examples of different configurations and usages."},
]
# Initialize LangChain's text splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
# Split the content in each JSON entry using the text splitter
split_json_data = [{"title": item["title"], "content": text_splitter.split_text(item["content"])} for item in json_data]
print(split_json_data)
# Function to process the 10 examples and apply the text splitting logic
def process_json(json_data):
for item in json_data:
print(f"Title: {item['title']}")
print("Content chunks:")
for chunk in item["content"]:
print(chunk)
print("-" * 40)
# 1. Flat JSON (Standard Format)
print("1. Flat JSON (Standard Format)")
process_json(split_json_data)
# 2. JSON as a Dictionary with Indexed Keys
print("2. JSON as a Dictionary with Indexed Keys")
indexed_json = {i: item for i, item in enumerate(split_json_data)}
process_json(indexed_json.values())
# 3. Nested JSON by Categories (e.g., Titles)
print("3. Nested JSON by Categories (e.g., Titles)")
nested_by_title = {item["title"]: item for item in split_json_data}
process_json(nested_by_title.values())
# 4. Concatenated Content JSON
print("4. Concatenated Content JSON")
concatenated_content = {"all_content": " ".join(" ".join(chunk) for item in split_json_data for chunk in item["content"])}
print(concatenated_content)
print("-" * 40)
# 5. JSON with Content Length as an Additional Field
print("5. JSON with Content Length as an Additional Field")
length_added_json = [{**item, "content_length": sum(len(chunk) for chunk in item["content"])} for item in split_json_data]
process_json(length_added_json)
# 6. Hierarchical JSON by Section Level
print("6. Hierarchical JSON by Section Level")
hierarchical_json = {
"Main": split_json_data[0],
"Subsections": split_json_data[1:]
}
process_json([hierarchical_json["Main"]])
process_json(hierarchical_json["Subsections"])
# 7. JSON as a CSV-Like Structure
print("7. JSON as a CSV-Like Structure")
csv_like_json = [["title", "content"]] + [[item["title"], " ".join(item["content"])] for item in split_json_data]
for row in csv_like_json:
print(row)
print("-" * 40)
# 8. Inverted JSON (Content as Keys)
print("8. Inverted JSON (Content as Keys)")
inverted_json = {chunk: item["title"] for item in split_json_data for chunk in item["content"]}
for content, title in inverted_json.items():
print(f"Content: {content}\nTitle: {title}")
print("-" * 40)
# 9. JSON with Sequential Numbering in Titles
print("9. JSON with Sequential Numbering in Titles")
numbered_json = [{"title": f"{i+1}. {item['title']}", "content": item["content"]} for i, item in enumerate(split_json_data)]
process_json(numbered_json)
# 10. JSON with Metadata for Each Entry
print("10. JSON with Metadata for Each Entry")
metadata_json = [
{**item, "metadata": {"timestamp": datetime.datetime.now().isoformat(), "author": "Author Name"}}
for item in split_json_data
]
process_json(metadata_json)
Output Example
1st Example: Flat JSON (Standard Format)
flat_json = json_data
print(flat_json)
Explanation: This example simply prints the original list of dictionaries in a flat structure, where each entry in the JSON data is presented as-is. The content is not grouped, reorganized, or indexed.
Output:
print(split_json_data)
[
{
"title": "Introduction",
"content": ["LangChain is a library for large language model applications."]
},
{
"title": "Getting Started",
"content": ["This section covers installation and setup."]
},
{
"title": "Advanced Usage",
"content": ["Advanced features include text splitting, document processing, and more."]
},
{
"title": "Examples",
"content": ["Here we show examples of different configurations and usages."]
}
]
[
{"title": "Introduction", "content": "LangChain is a library for large language model applications."},
{"title": "Getting Started", "content": "This section covers installation and setup."},
{"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more."},
{"title": "Examples", "content": "Here we show examples of different configurations and usages."}
]
2nd Example: JSON as a Dictionary with Indexed Keys
indexed_json = {i: item for i, item in enumerate(json_data)}
print(indexed_json)
Explanation: Here, the list is transformed into a dictionary where each item from the list is assigned an index as the key. This format makes it easy to access each entry by index (e.g., indexed_json[0]).
Output:
{
0: {"title": "Introduction", "content": "LangChain is a library for large language model applications."},
1: {"title": "Getting Started", "content": "This section covers installation and setup."},
2: {"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more."},
3: {"title": "Examples", "content": "Here we show examples of different configurations and usages."}
}
3rd Example: Nested JSON by Categories (e.g., Titles)
nested_by_title = {item["title"]: item for item in json_data}
print(nested_by_title)
Explanation: This example creates a nested dictionary where each entry's title is used as the key. This allows you to directly access each section by its title (e.g., nested_by_title["Introduction"]).
Output:
{
"Introduction": {"title": "Introduction", "content": "LangChain is a library for large language model applications."},
"Getting Started": {"title": "Getting Started", "content": "This section covers installation and setup."},
"Advanced Usage": {"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more."},
"Examples": {"title": "Examples", "content": "Here we show examples of different configurations and usages."}
}
4th Example: Concatenated Content JSON
concatenated_content = {"all_content": " ".join(item["content"] for item in json_data)}
print(concatenated_content)
Explanation: This example combines the content fields from each entry into one single string and stores it in a dictionary under the key "all_content". This approach is useful if you want to aggregate or summarize all the content into a single field.
Output:
{
"all_content": "LangChain is a library for large language model applications. This section covers installation and setup. Advanced features include text splitting, document processing, and more. Here we show examples of different configurations and usages."
}
5th Example: JSON with Content Length as an Additional Field
length_added_json = [{**item, "content_length": len(item["content"])} for item in json_data]
print(length_added_json)
Explanation: In this case, each dictionary in the original JSON data is augmented with an additional content_length key that shows the length of the content string for that entry.
Output:
[
{"title": "Introduction", "content": "LangChain is a library for large language model applications.", "content_length": 74},
{"title": "Getting Started", "content": "This section covers installation and setup.", "content_length": 44},
{"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more.", "content_length": 82},
{"title": "Examples", "content": "Here we show examples of different configurations and usages.", "content_length": 72}
]
6th Example: Hierarchical JSON by Section Level
hierarchical_json = {
"Main": json_data[0],
"Subsections": json_data[1:]
}
print(hierarchical_json)
Explanation: This example organizes the JSON into a hierarchical structure, with one "Main" entry (the first item) and the rest categorized as "Subsections." This structure could be helpful if you're building a hierarchical navigation or document structure.
Output:
{
"Main": {"title": "Introduction", "content": "LangChain is a library for large language model applications."},
"Subsections": [
{"title": "Getting Started", "content": "This section covers installation and setup."},
{"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more."},
{"title": "Examples", "content": "Here we show examples of different configurations and usages."}
]
}
7th Example: JSON as a CSV-Like Structure
csv_like_json = [["title", "content"]] + [[item["title"], item["content"]] for item in json_data]
print(csv_like_json)
Explanation: This example converts the JSON data into a CSV-like structure, where the first row contains headers ("title" and "content") and the following rows represent the data. This format is useful for converting to CSV files or tabular representations.
Output:
[
["title", "content"],
["Introduction", "LangChain is a library for large language model applications."],
["Getting Started", "This section covers installation and setup."],
["Advanced Usage", "Advanced features include text splitting, document processing, and more."],
["Examples", "Here we show examples of different configurations and usages."]
]
8th Example: Inverted JSON (Content as Keys)
inverted_json = {item["content"]: item["title"] for item in json_data}
print(inverted_json)
Explanation: This example inverts the structure of the original JSON data by using the content field as the key and the title field as the value. This would work well if the content is unique, and you need to reference sections by their content.
Output:
{
"LangChain is a library for large language model applications.": "Introduction",
"This section covers installation and setup.": "Getting Started",
"Advanced features include text splitting, document processing, and more.": "Advanced Usage",
"Here we show examples of different configurations and usages.": "Examples"
}
9th Example: JSON with Sequential Numbering in Titles
numbered_json = [{"title": f"{i+1}. {item['title']}", "content": item["content"]} for i, item in enumerate(json_data)]
print(numbered_json)
Explanation: This example adds a sequential number to each title, making it easier to reference the order of the sections in a list-like format. This could be used in tutorials, documentation, or courses where order matters.
Output:
[
{"title": "1. Introduction", "content": "LangChain is a library for large language model applications."},
{"title": "2. Getting Started", "content": "This section covers installation and setup."},
{"title": "3. Advanced Usage", "content": "Advanced features include text splitting, document processing, and more."},
{"title": "4. Examples", "content": "Here we show examples of different configurations and usages."}
]
10th Example: JSON with Metadata for Each Entry
import datetime
metadata_json = [
{**item, "metadata": {"timestamp": datetime.datetime.now().isoformat(), "author": "Author Name"}}
for item in json_data
]
print(metadata_json)
Explanation: In this example, each entry in the JSON is enhanced with metadata, such as a timestamp and an author field. This approach is useful when you need to track when the data was created or who created it.
Output:
[
{"title": "Introduction", "content": "LangChain is a library for large language model applications.", "metadata": {"timestamp": "2024-11-14T12:34:56.789123", "author": "Author Name"}},
{"title": "Getting Started", "content": "This section covers installation and setup.", "metadata": {"timestamp": "2024-11-14T12:34:56.789123", "author": "Author Name"}},
{"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more.", "metadata": {"timestamp": "2024-11-14T12:34:56.789123", "author": "Author Name"}},
{"title": "Examples", "content": "Here we show examples of different configurations and usages.", "metadata": {"timestamp": "2024-11-14T12:34:56.789123", "author": "Author Name"}}
]
Summary of Outputs:
Concatenated Content JSON: Aggregates content into a single field.
JSON with Content Length: Adds a length field for each entry.
Hierarchical JSON by Section Level: Organizes sections into "Main" and "Subsections".
JSON as CSV-Like Structure: Transforms data into a tabular-like format.
Inverted JSON: Inverts the structure by using content as keys.
JSON with Sequential Numbering in Titles: Adds sequential numbering to titles.
JSON with Metadata: Enhances each entry with timestamp and author information.
Transforming JSON into into Multiple Formats after text-splitting
json_data = [
{"title": "Introduction", "content": "LangChain is a library for large language model applications."},
{"title": "Getting Started", "content": "This section covers installation and setup."},
{"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more."},
{"title": "Examples", "content": "Here we show examples of different configurations and usages."},
]
Plain Text Output
This example joins all content fields into a single plain text string:
plain_text = "\n".join(item["content"] for item in json_data)
print(plain_text)
Output:
LangChain is a library for large language model applications.
This section covers installation and setup.
Advanced features include text splitting, document processing, and more.
Here we show examples of different configurations and usages.
- Table Format Using Pandas DataFrame This converts the JSON data to a table format using pandas:
import pandas as pd
df = pd.DataFrame(json_data)
print(df)
Output:

This saves the JSON data into a CSV file (json_data.csv):
df.to_csv("json_data.csv", index=False)
CSV File (json_data.csv):

- HTML Format for Web Display This converts the JSON data into an HTML table format:
html_table = df.to_html(index=False)
with open("json_data.html", "w") as file:
file.write(html_table)
HTML File (json_data.html):
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th>title</th>
<th>content</th>
</tr>
</thead>
<tbody>
<tr>
<td>Introduction</td>
<td>LangChain is a library for large language model applications.</td>
</tr>
<tr>
<td>Getting Started</td>
<td>This section covers installation and setup.</td>
</tr>
<tr>
<td>Advanced Usage</td>
<td>Advanced features include text splitting, document processing, and more.</td>
</tr>
<tr>
<td>Examples</td>
<td>Here we show examples of different configurations and usages.</td>
</tr>
</tbody>
</table>
PDF Format Using ReportLab
This converts the JSON data into a PDF file:
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
pdf = canvas.Canvas("json_data.pdf", pagesize=letter)
pdf.drawString(100, 750, "JSON Data in PDF Format:")
y = 700
for item in json_data:
pdf.drawString(100, y, f"Title: {item['title']}")
y -= 20
pdf.drawString(120, y, f"Content: {item['content']}")
y -= 40
pdf.save()
PDF Output (json_data.pdf):
JSON Data in PDF Format:
Title: Introduction
Content: LangChain is a library for large language model applications.
Title: Getting Started
Content: This section covers installation and setup.
Title: Advanced Usage
Content: Advanced features include text splitting, document processing, and more.
Title: Examples
Content: Here we show examples of different configurations and usages.
JSON Format with Concatenated Content
This example concatenates all content fields into a single JSON entry:
concatenated_json = {"all_content": " ".join(item["content"] for item in json_data)}
print(concatenated_json)
Output:
{
"all_content": "LangChain is a library for large language model applications. This section covers installation and setup. Advanced features include text splitting, document processing, and more. Here we show examples of different configurations and usages."
}
- Markdown Format for Documentation This example converts the JSON data into Markdown format:
markdown_text = "\n".join(f"### {item['title']}\n\n{item['content']}" for item in json_data)
with open("json_data.md", "w") as file:
file.write(markdown_text)
Markdown File (json_data.md):
### Introduction
LangChain is a library for large language model applications.
### Getting Started
This section covers installation and setup.
### Advanced Usage
Advanced features include text splitting, document processing, and more.
### Examples
Here we show examples of different configurations and usages.
Excel Format Using Pandas
This saves the JSON data into an Excel file:
df.to_excel("json_data.xlsx", index=False)

JSONL (JSON Lines) Format
This saves the JSON data in JSON Lines format for easier streaming:
import json
with open("json_data.jsonl", "w") as file:
for item in json_data:
file.write(f"{json.dumps(item)}\n")
JSONL File (json_data.jsonl):
{"title": "Introduction", "content": "LangChain is a library for large language model applications."}
{"title": "Getting Started", "content": "This section covers installation and setup."}
{"title": "Advanced Usage", "content": "Advanced features include text splitting, document processing, and more."}
{"title": "Examples", "content": "Here we show examples of different configurations and usages}

Top comments (0)