Key Ideas
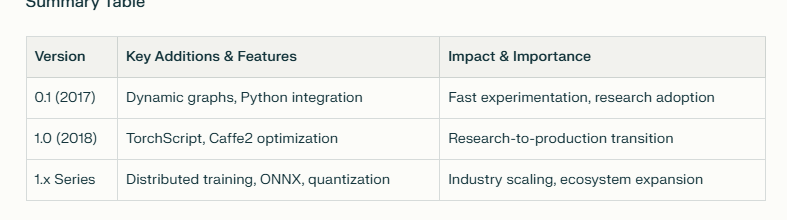
Pytorch version
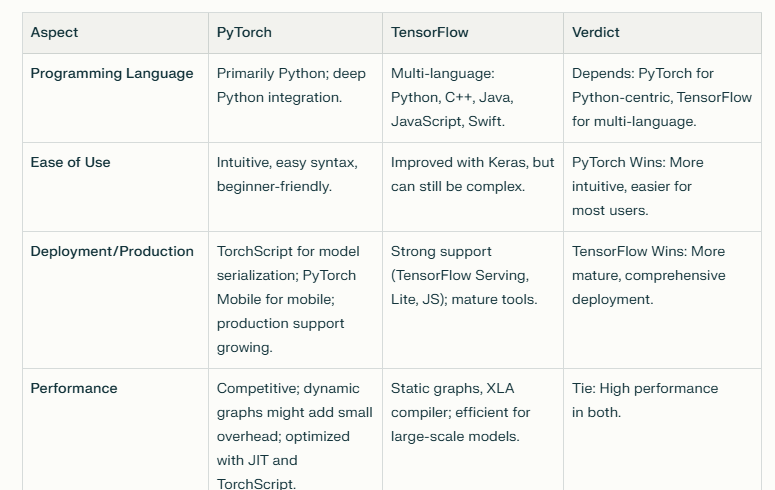
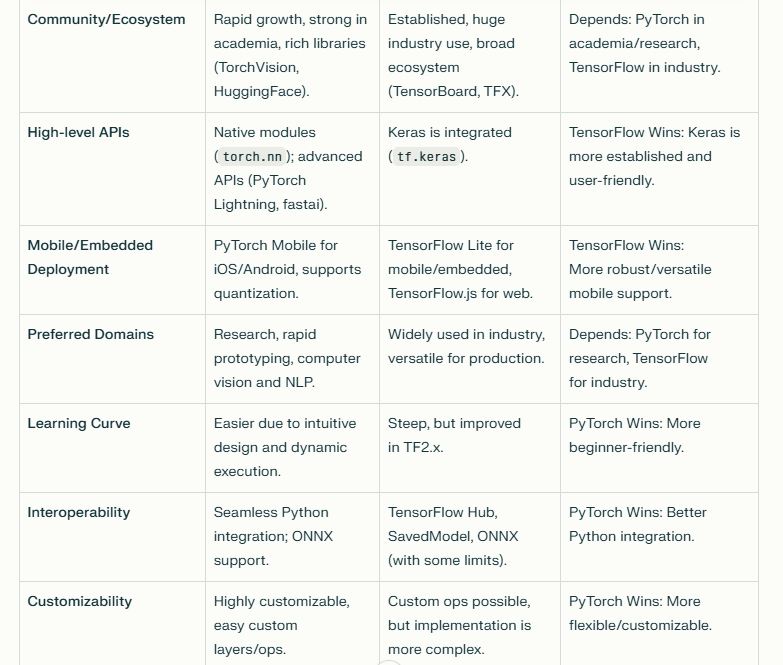
Compariosion between pytorch and tensorflow
Install command in cmd
PyTorch is a Python-based deep learning library that makes it easy to build and train artificial intelligence (AI) models by working with data and mathematical operations in a way that's very similar to regular Python code.
Key Ideas
Tensors: The fundamental data type in PyTorch, similar to NumPy arrays but with added power—they can run on CPUs and GPUs for faster computation.
Pythonic API: PyTorch code looks and feels like regular Python. You can use loops, if statements, and other familiar Python structures in your models.
Dynamic Computation Graph: The structure of your neural network is created on-the-fly as your code runs, which makes PyTorch very flexible for experimenting and debugging.
Ecosystem: PyTorch has lots of modules for different tasks: neural network building blocks (torch.nn), optimization algorithms (torch.optim), automatic differentiation (torch.autograd), and data handling (torch.utils.data).
Easy Interoperability: You can convert PyTorch tensors to and from NumPy arrays, use tools like SciPy or Pandas, and embed PyTorch calculations into other Python programs
Pytorch version
PyTorch 0.1 (2017)
What’s New
Dynamic Computation Graph:
PyTorch introduced the dynamic (define-by-run) computation graph, meaning the graph structure is built on-the-fly as the code runs. This approach is much more flexible than static graphs (like those in TensorFlow 1.x), enabling fast experimentation and easier debugging.
Seamless Python Library Integration:
Native compatibility with popular Python libraries such as NumPy and SciPy, allowing researchers to easily use familiar tools alongside PyTorch’s tensor and neural network utilities.
Impact
Research Adoption:
Made PyTorch the preferred choice for academic research, thanks to its Pythonic and interactive feel.
Intuitive APIs & Flexibility:
Users could write complex models and workflows using standard Python code, and quickly see results or debug step-by-step.
PyTorch 1.0 (2018)
What’s New
TorchScript for Serialization and Optimization:
PyTorch 1.0 introduced TorchScript, a way to convert Python models into a format suitable for production deployment, speeding up inference and enabling model sharing without Python runtime dependencies.
Bridged Research-to-Production Gap:
It became possible to take models developed in research and run them in production environments reliably with little friction.
Improved Performance (Caffe2 Integration):
Many optimizations were added from Facebook’s Caffe2 framework, making PyTorch faster and more scalable, especially for deployment.
Impact
Smooth Deployment:
Researchers could not only experiment but also ship models, making PyTorch attractive for both research and industry.
PyTorch 1.x Series
:
What’s New
Distributed Training:
PyTorch added robust support for training large models across multiple GPUs or even machines, crucial for both industrial-scale work and academic labs.
ONNX Interoperability:
Native export and import of models with ONNX (Open Neural Network Exchange), making it easier to use PyTorch models with other frameworks and production tools.
Quantization:
Techniques for compressing models (using lower precision like int8 instead of float32) were added, improving performance on edge devices or real-time applications.
Library Ecosystem (TorchVision, TorchText, TorchAudio):
PyTorch greatly expanded its tools for computer vision, natural language processing, and audio/speech processing. Prebuilt modules, datasets, and augmentation tools sped up prototyping and research.
Impact
Industry Adoption and Community Growth:
Wider use in commercial and opensource projects.
Robust Community Libraries:
PyTorch Lightning and Huggingface Transformers emerged, standardizing best practices, reusable components, and simplifying advanced tasks.
Cloud Support:
Improvements for deployment on cloud infrastructure made PyTorch favored for scalable machine learning solutions
Compariosion between pytorch and tensorflow

install command in cmd
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu

Top comments (0)