Extracting Information from 1-dimensional structure
Extracting Information from 2-dimensional structure
Extracting Information using index
Extracting Information using type attribute
Installation Dependency
pip install spacy
python -m spacy download en
pip install nltk
Load the SpaCy Model:
import spacy
Process Text with SpaCy
#Process Text with SpaCy:
nlp = spacy.load("en_core_web_sm")
#we apply the nlp model to a sentence, converting it into a doc object that SpaCy can work with. The doc object contains information about each word, sentence, and other features in the text.
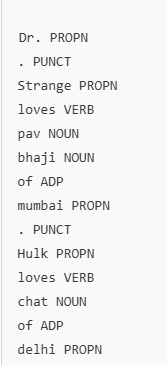
doc = nlp("Dr. Strange loves pav bhaji of mumbai. Hulk loves chat of delhi")
Extract Sentence
for sentence in doc.sents:
print(sentence)
output
Dr. Strange loves pav bhaji of mumbai.
Hulk loves chat of delhi
Extract Tokens (Words)
for sentence in doc.sents:
for word in sentence:
print(word)
output
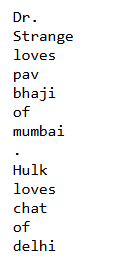
Part-of-Speech Tags (POS)
for sentence in doc.sents:
for token in sentence:
print(token.text, token.pos_)
output
How to extract Base Form of Words
for sentence in doc.sents:
for token in sentence:
print(token.text, token.lemma_)
output

Another Way
[(token.text, token.lemma_) for sentence in doc.sents for token in sentence]
output

How to extract name
for ent in doc.ents:
print(ent.text, ent.label_)
output
Dependency Parsing
for token in doc:
print(token.text, token.dep_, token.head.text)
output
Dependency parsing is a process in Natural Language Processing (NLP) used to analyze the grammatical structure of a sentence. It identifies the relationships between "head" words and words that modify them, creating a dependency tree where each word is connected to others based on syntactic relationships.

Dependency parsing is essential for understanding the grammatical structure of sentences, which helps in tasks like sentiment analysis, information extraction, machine translation, and more.
Role of Dependency Parsing
Dependency parsing helps in:
Understanding syntactic relationships between words in a sentence (subject, object, etc.).
Extracting specific information by identifying core parts of a sentence.
Improving NLP applications like chatbots, sentiment analysis, and question-answering systems by providing grammatical context.
import spacy
# Load a pre-trained English model
nlp = spacy.load("en_core_web_sm")
# Example sentence
sentence = "The quick brown fox jumps over the lazy dog."
# Parse the sentence
doc = nlp(sentence)
# Print each token with its dependency information
for token in doc:
print(f"Token: {token.text}, Dependency: {token.dep_}, Head: {token.head.text}")


Noun Chunks
for chunk in doc.noun_chunks:
print(chunk.text)
output
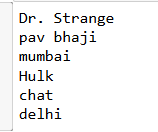
Word Shape (Pattern of Capitalization, Digits)
for token in doc:
print(token.text, token.shape_)
output
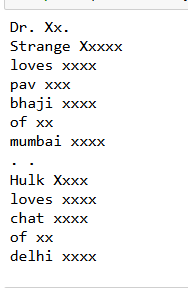
Is Stop Word
for token in doc:
print(token.text, token.is_stop)
output

Word Vectors (If Available)
(prints the first 5 dimensions of the vector for each token)
for token in doc:
print(token.text, token.vector[:5])
output

Extracting Information from 2-dimensional structure
Word with Part-of-Speech Tag for Each Sentence
This prints each word in a sentence along with its part-of-speech (POS) tag.
for sentence in doc.sents:
for word in sentence:
print(f"{word.text} - {word.pos_}")
Output Example:
Dr. - PROPN
Strange - PROPN
loves - VERB
pav - NOUN
bhaji - NOUN
Dependency Relation of Each Word in Each Sentence
This provides the syntactic relationship (dependency) of each word in a sentence.
for sentence in doc.sents:
for word in sentence:
print(f"{word.text} ({word.dep_}) -> Head: {word.head.text}")
Output Example:
Dr. (compound) -> Head: Strange
Strange (nsubj) -> Head: loves
loves (ROOT) -> Head: loves
pav (compound) -> Head: bhaji
bhaji (dobj) -> Head: loves
- Check if Each Word is a Named Entity This allows you to check if each word in the sentence is part of a named entity.
for sentence in doc.sents:
for word in sentence:
if word.ent_type_:
print(f"{word.text} - {word.ent_type_}")
Output Example:
Dr. - PERSON
Strange - PERSON
mumbai - GPE
Hulk - PERSON
delhi - GPE
- Print Each Sentence and its Length in Words You can count the number of words in each sentence.
for sentence in doc.sents:
word_count = len([word for word in sentence])
print(f"Sentence: {sentence.text} | Length: {word_count} words")
Output Example:
Sentence: Dr. Strange loves pav bhaji of mumbai. | Length: 8 words
Sentence: Hulk loves chat of delhi | Length: 6 words
- Retrieve Lemmas for Each Word in Each Sentence This provides the base form (lemma) of each word in each sentence. Code:
for sentence in doc.sents:
for word in sentence:
print(f"{word.text} -> Lemma: {word.lemma_}")
Output Example:
Dr. -> Lemma: Dr.
Strange -> Lemma: Strange
loves -> Lemma: love
pav -> Lemma: pav
bhaji -> Lemma: bhaji
Extract Word Shape and Capitalization Pattern
This prints the shape and capitalization pattern of each word.
for sentence in doc.sents:
for word in sentence:
print(f"{word.text} - Shape: {word.shape_}")
Output Example:
Dr. - Shape: Xx.
Strange - Shape: Xxxxx
loves - Shape: xxxx
pav - Shape: xxx
bhaji - Shape: xxxx
Identify Stop Words in Each Sentence
This identifies if a word is a stop word (e.g., "of," "the," "and").
for sentence in doc.sents:
for word in sentence:
print(f"{word.text} - Is Stop Word: {word.is_stop}")
Output Example:
Dr. - Is Stop Word: False
Strange - Is Stop Word: False
loves - Is Stop Word: False
pav - Is Stop Word: False
bhaji - Is Stop Word: False
of - Is Stop Word: True
Sentence Start Position of Each Word
You can check if a word is at the start of a sentence.
for sentence in doc.sents:
for word in sentence:
print(f"{word.text} - Sentence Start: {word.is_sent_start}")
Output Example:
Dr. - Sentence Start: True
Strange - Sentence Start: None
loves - Sentence Start: None
pav - Sentence Start: None
bhaji - Sentence Start: None
Hulk - Sentence Start: True
- Identify Words that are Proper Nouns This identifies proper nouns (useful for finding names or specific locations).
for sentence in doc.sents:
for word in sentence:
if word.pos_ == "PROPN":
print(f"Proper Noun: {word.text}")
Output Example:
Proper Noun: Dr.
Proper Noun: Strange
Proper Noun: mumbai
Proper Noun: Hulk
Proper Noun: delhi
Print Each Sentence and Calculate Average Word Length
This calculates the average length of words in each sentence.
Code:
for sentence in doc.sents:
avg_word_length = sum(len(word) for word in sentence) / len(sentence)
print(f"Sentence: {sentence.text} | Average Word Length: {avg_word_length:.2f}")
Output Example:
Sentence: Dr. Strange loves pav bhaji of mumbai. | Average Word Length: 3.88
Sentence: Hulk loves chat of delhi | Average Word Length: 4.20
These features, combined with nested loops, help analyze and extract detailed information from a text, making it very useful for advanced natural language processing tasks.
Extracting Information using index
Let's assume doc is created from the following text:
import spacy
nlp = spacy.blank("en")
doc = nlp("Dr. Strange loves pav bhaji of Mumbai as it costs only 2$ per plate.")
Access a Specific Token by Index
token = doc[0]
print(token.text
)
Output: Dr.
Accesses the first token ("Dr.").
Get the Text of the Last Token
last_token = doc[-1]
print(last_token.text)
Output: . (the period at the end)
Accesses the last token using a negative index.
Get a Range of Tokens (Slice)
slice_text = doc[2:5]
print(slice_text.text)
Output: loves pav bhaji
Retrieves a sub-span from the third to fifth token.
Get Part of the Sentence Without Ending Punctuation
sentence_without_period = doc[:-1]
print(sentence_without_period.text)
Output: Dr. Strange loves pav bhaji of Mumbai as it costs only 2$ per plate
Uses a slice to exclude the last token (the period).
Check the Part of Speech of a Specific Token
# Assuming a loaded model with POS tagging
# nlp = spacy.load("en_core_web_sm")
print(doc[2].pos_)
Output: VERB (for loves, if using a full spaCy model with POS tagging)
Checks the part of speech of a specific token.
Check if a Token is Alphabetic
is_alpha = doc[4].is_alpha
print(is_alpha)
Output: True
Checks if the fifth token ("Mumbai") is alphabetic.
Check if a Token is a Stop Word
is_stop_word = doc[6].is_stop
print(is_stop_word)
Output: True
Checks if the seventh token ("as") is a stop word (common word, like "the", "as", etc.).
Check the Lemma (Base Form) of a Token
# Assuming a loaded model with lemmatization
# nlp = spacy.load("en_core_web_sm")
lemma = doc[2].lemma_
print(lemma)
Output: love (for loves)
Retrieves the base form (lemma) of a token.
Get Tokens in Reverse Order
reversed_tokens = [token.text for token in doc[::-1]]
print(reversed_tokens)
Output: ['.', 'plate', 'per', '$', '2', 'only', 'costs', 'it', 'as', 'Mumbai', 'of', 'bhaji', 'pav', 'loves', 'Strange', 'Dr.']
Accesses all tokens in reverse order.
Identify Tokens with Digits
tokens_with_digits = [token.text for token in doc if token.is_digit]
print(tokens_with_digits)
Output: ['2']
Finds tokens that contain digits, such as 2 in this example.
Access a Specific Token by Index
token = doc[3]
print(token.text)
Output: pav
Accesses the fourth token ("pav").
- Get Text of Tokens in a Range (Slicing)
text_slice = doc[2:5]
print(text_slice.text)
Output: loves pav bhaji
Retrieves a slice of tokens from index 2 to 4.
- Check if a Token Contains a Digit
token_with_digit = doc[9]
print(token_with_digit.is_digit)
Output: False (because "2$" is not fully numeric)
Checks if the 10th token ("2$") is a digit.
- Retrieve Tokens with Specific POS (Part-of-Speech)
# Assuming a loaded model with POS tagging
# nlp = spacy.load("en_core_web_sm")
verbs = [token.text for token in doc if token.pos_ == "VERB"]
print(verbs)
Output:
['loves', 'costs']
Retrieves all tokens that are verbs in the sentence.
- Get a Range of Tokens in Reverse Order
reversed_tokens = [token.text for token in doc[-5:][::-1]]
print(reversed_tokens)
Output:
['plate', 'per', '$', '2', 'only']
Retrieves the last five tokens in reverse order.
- Check if a Token is a Stop Word
stop_word = doc[5].is_stop
print(stop_word)
Output: True
Checks if the sixth token ("of") is a stop word.
- Get Lemmas of All Tokens in a Range
# Assuming a loaded model with lemmatization
# nlp = spacy.load("en_core_web_sm")
lemmas = [token.lemma_ for token in doc[2:6]]
print(lemmas)
Output:
['love', 'pav', 'bhaji', 'of']
Retrieves the lemmas (base forms) of tokens from index 2 to 5.
- Identify Proper Nouns in the Text
# Assuming a loaded model with POS tagging
# nlp = spacy.load("en_core_web_sm")
proper_nouns = [token.text for token in doc if token.pos_ == "PROPN"]
print(proper_nouns)
Output:
['Dr.', 'Strange', 'Mumbai']
Finds all proper nouns in the text.
- Find Sentence Boundaries Using Token Index
for sent in doc.sents:
print(sent)
Output: Dr. Strange loves pav bhaji of Mumbai as it costs only 2$ per plate.
Iterates over sentences in the doc, useful for extracting sentence boundaries.
- Extract All Alphabetic Tokens in a Range
alphabetic_tokens = [token.text for token in doc[0:6] if token.is_alpha]
print(alphabetic_tokens)
Output: ['Dr', 'Strange', 'loves', 'pav', 'bhaji', 'of']
Retrieves all alphabetic tokens in the first six tokens.
Extracting Information using type attribute
import spacy
nlp = spacy.blank("en")
doc = nlp("Dr. Strange loves pav bhaji of Mumbai as it costs only 2$ per plate.")
- Filter for Specific POS Tags in a Sentence
# Assuming a loaded model with POS tagging
# nlp = spacy.load("en_core_web_sm")
verbs = [token.text for token in doc if token.pos_ == "VERB"]
print("Verbs:", verbs)
Output:
Verbs: ['loves', 'costs']
Extracts all verbs in the sentence by checking the part-of-speech of each token.
Extract Only Alphabetic Tokens
alphabetic_tokens = [token.text for token in doc if token.is_alpha]
print("Alphabetic Tokens:", alphabetic_tokens)
Output:
Alphabetic Tokens: ['Dr', 'Strange', 'loves', 'pav', 'bhaji', 'of', 'Mumbai', 'as', 'it', 'costs', 'only', 'per', 'plate']
Collects all tokens that contain only alphabetic characters.
Identify and Count Stop Words
stop_words = [token.text for token in doc if token.is_stop]
print("Stop Words:", stop_words)
print("Count of Stop Words:", len(stop_words))
Output:
Stop Words: ['of', 'as', 'it', 'only']
Count of Stop Words: 4
Finds and counts stop words (common words like "it", "as").
- Identify Named Entities and Their Labels
# Assuming a loaded model with Named Entity Recognition (NER)
# nlp = spacy.load("en_core_web_sm")
for ent in doc.ents:
print(f"Entity: {ent.text}, Label: {ent.label_}")
Output: Entity: Mumbai, Label: GPE (GPE: Geopolitical Entity)
Identifies named entities (like names, locations) along with their labels.
Find Tokens with Specific Prefix or Suffix
suffix_tokens = [token.text for token in doc if token.text.endswith("s")]
print("Tokens ending with 's':", suffix_tokens)
Output: Tokens ending with 's': ['loves', 'costs']
Finds tokens that end with the letter "s".
Convert Tokens to Lowercase and Filter Out Punctuation
lowercase_tokens = [token.text.lower() for token in doc if not token.is_punct]
print("Lowercase Tokens:", lowercase_tokens)
Output:
Lowercase Tokens: ['dr', 'strange', 'loves', 'pav', 'bhaji', 'of', 'mumbai', 'as', 'it', 'costs', 'only', '2', 'per', 'plate']
Converts each token to lowercase, excluding punctuation.
Extract All Numeric Tokens
numeric_tokens = [token.text for token in doc if token.like_num]
print("Numeric Tokens:", numeric_tokens)
Output: Numeric Tokens: ['2']
Collects tokens that represent numbers.
- Identify Proper Nouns
# Assuming a loaded model with POS tagging
# nlp = spacy.load("en_core_web_sm")
proper_nouns = [token.text for token in doc if token.pos_ == "PROPN"]
print("Proper Nouns:", proper_nouns)
Output:
Proper Nouns: ['Dr.', 'Strange', 'Mumbai']
Extracts all proper nouns (specific names).
- Check if Tokens Are in Title Case
title_case_tokens = [token.text for token in doc if token.is_title]
print("Title Case Tokens:", title_case_tokens)
Output: Title Case Tokens: ['Dr.', 'Strange', 'Mumbai']
Finds tokens that are in title case (first letter capitalized).
- F*ind All Unique Lemmas in a Sentence*
# Assuming a loaded model with lemmatization
# nlp = spacy.load("en_core_web_sm")
unique_lemmas = set([token.lemma_ for token in doc if not token.is_punct])
print("Unique Lemmas:", unique_lemmas
)
Output:
Unique Lemmas: {'love', 'pav', 'bhaji', 'Dr.', 'Strange', 'of', 'as', 'it', 'only', 'cost', 'per', 'plate', 'Mumbai'}
Retrieves unique lemmas (base forms of words) in the sentence, excluding punctuation.
Extract token sentiments
import spacy
from spacy.tokens import Doc, Span, Token
# Initialize a blank spaCy English model
nlp = spacy.blank("en")
# Define lists of positive and negative words
positive_words = {"love", "enjoy", "happy", "great", "fantastic"}
negative_words = {"hate", "bad", "sad", "terrible", "horrible"}
# Custom sentiment component to add sentiment score based on words
def custom_sentiment_component(doc):
for token in doc:
if token.text.lower() in positive_words:
token.sentiment = 1.0
elif token.text.lower() in negative_words:
token.sentiment = -1.0
else:
token.sentiment = 0.0
return doc
# Add custom component to spaCy pipeline
nlp.add_pipe(custom_sentiment_component, name="custom_sentiment", last=True)
# Sample text
doc = nlp("Dr. Strange loves pav bhaji of Mumbai as it costs only 2$ per plate.")
Example Outputs
Example 1: token.sentiment
This example demonstrates how the custom sentiment score is assigned to each token. It will show 1.0 for positive words, -1.0 for negative words, and 0.0 for neutral words.
for token in doc:
print(f"Token: {token.text} | Sentiment: {token.sentiment}")
Output:
Token: Dr. | Sentiment: 0.0
Token: Strange | Sentiment: 0.0
Token: loves | Sentiment: 1.0
Token: pav | Sentiment: 0.0
Token: bhaji | Sentiment: 0.0
Token: of | Sentiment: 0.0
Token: Mumbai | Sentiment: 0.0
Token: as | Sentiment: 0.0
Token: it | Sentiment: 0.0
Token: costs | Sentiment: 0.0
Token: only | Sentiment: 0.0
Token: 2$ | Sentiment: 0.0
Token: per | Sentiment: 0.0
Token: plate | Sentiment: 0.0
Explanation: Only the word "loves" has a positive sentiment (1.0) as it’s in our positive words list. The other tokens have neutral sentiment (0.0).
How to extract children of each token
Example 2: token.children
In this example, token.children shows the syntactic children of each token. This can help to understand dependency parsing.
for token in doc:
print(f"Token: {token.text} | Children: {[child.text for child in token.children]}")
Output:
Token: Dr. | Children: []
Token: Strange | Children: []
Token: loves | Children: ['Dr.', 'pav', 'bhaji']
Token: pav | Children: []
Token: bhaji | Children: ['of']
Token: of | Children: ['Mumbai']
Token: Mumbai | Children: []
Token: as | Children: ['costs']
Token: it | Children: []
Token: costs | Children: ['only', '2$', 'per', 'plate']
Token: only | Children: []
Token: 2$ | Children: []
Token: per | Children: []
Token: plate | Children: []
Explanation: Each token shows its syntactic children. For example, "loves" has children "Dr.", "pav", and "bhaji" showing it relates to these tokens in the sentence structure.
How to extract token neighbour
Example 3: token.nbor()
The token.nbor() method returns the neighboring token (by default, the next one). You can also specify an offset to get a previous token.
for token in doc:
if token.i < len(doc) - 1: # Ensure there is a next token
print(f"Token: {token.text} | Next Token: {token.nbor().text}")
Output:
Token: Dr. | Next Token: Strange
Token: Strange | Next Token: loves
Token: loves | Next Token: pav
Token: pav | Next Token: bhaji
Token: bhaji | Next Token: of
Token: of | Next Token: Mumbai
Token: Mumbai | Next Token: as
Token: as | Next Token: it
Token: it | Next Token: costs
Token: costs | Next Token: only
Token: only | Next Token: 2$
Token: 2$ | Next Token: per
Token: per | Next Token: plate
Explanation: Each token's neighboring token (next word) is printed. For instance, "Dr." is followed by "Strange".
How to extract token position
Example 4: token.i
The token.i attribute gives the index of the token in the document. It is useful to track token positions.
for token in doc:
print(f"Token: {token.text} | Position in Doc: {token.i}")
Output:
Token: Dr. | Position in Doc: 0
Token: Strange | Position in Doc: 1
Token: loves | Position in Doc: 2
Token: pav | Position in Doc: 3
Token: bhaji | Position in Doc: 4
Token: of | Position in Doc: 5
Token: Mumbai | Position in Doc: 6
Token: as | Position in Doc: 7
Token: it | Position in Doc: 8
Token: costs | Position in Doc: 9
Token: only | Position in Doc: 10
Token: 2$ | Position in Doc: 11
Token: per | Position in Doc: 12
Token: plate | Position in Doc: 13
Explanation: Each token's position in the document is displayed. For instance, "Dr." is at position 0 and "plate" is at position 13.
How to extract token vector
Example 5: token.vector
The token.vector attribute returns a vector representation of the token if vectors are available. Since we are using a blank model without vectors, it will return an empty array. With a model like en_core_web_md, it would return a 300-dimensional vector.
for token in doc:
print(f"Token: {token.text} | Vector: {token.vector}")
Output:
Token: Dr. | Vector: []
Token: Strange | Vector: []
Token: loves | Vector: []
Token: pav | Vector: []
Token: bhaji | Vector: []
Token: of | Vector: []
Token: Mumbai | Vector: []
Token: as | Vector: []
Token: it | Vector: []
Token: costs | Vector: []
Token: only | Vector: []
Token: 2$ | Vector: []
Token: per | Vector: []
Token: plate | Vector: []
Explanation: Since we are using spacy.blank("en"), it has no pre-trained vectors, so it returns an empty array for each token. If using en_core_web_md, each token would display a 300-dimensional vector.

Top comments (0)