Write a python program to scrape mentioned news details from https://www.cnbc.com/world/?region=world and
make data frame
i) Headline
ii) Time
iii) News Link
How to get all text data of anchor tag of specific class
How to get all url of anchor tag of specific class
How to count all element of list
step 1 first install libraries
pip install bs4
pip install request
step 2 import libraries
from bs4 import BeautifulSoup
import requests
step3:Send an HTTP GET request to the URL and (status code 200)
page = requests.get('https://www.cnbc.com/world/?region=world')
page
output
<Response [200]>
step4: check page content
soup= BeautifulSoup(page.content)
soup
output
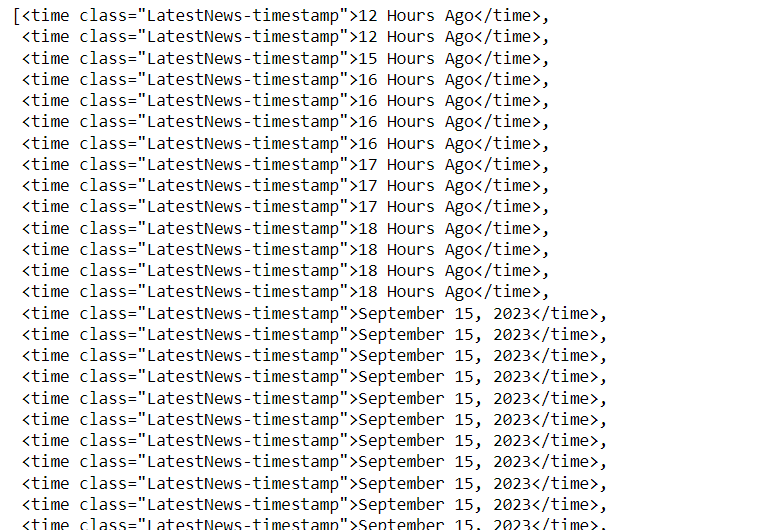
step5: get data of particular class of time tag
data = soup.find_all('time', class_="LatestNews-timestamp")
data
Output
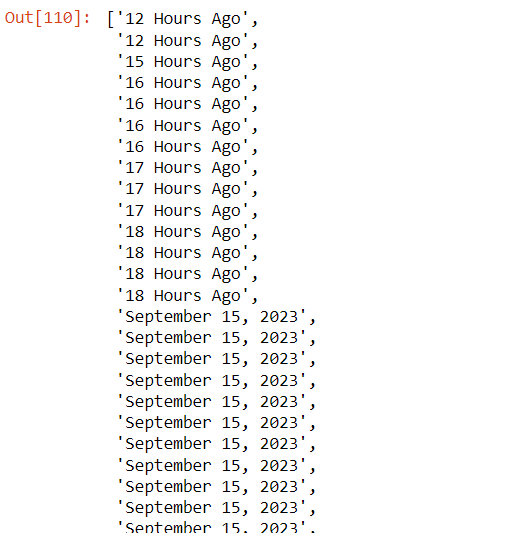
step6: get all data of time and store in list
hour=[]
for tag in data:
hour.append(tag.text.strip())
hour
Output
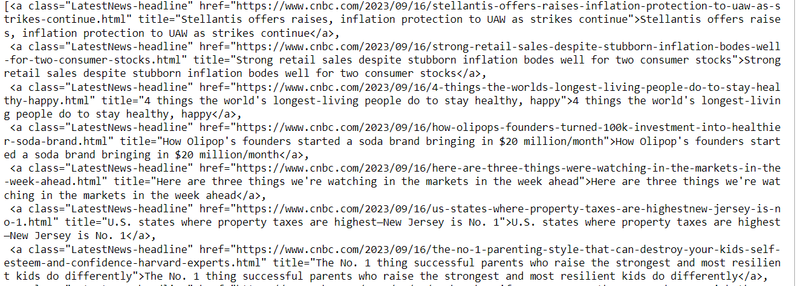
step7: get all data of anchor tag of specific class
heads = soup.find_all('a', class_="LatestNews-headline")
heads
Output
step8: get all data of anchor tag and store in list
How to get all text data of anchor tag of specific class
latest_news=[]
for tag in heads:
latest_news.append(tag.text.strip())
latest_news
output
step9: to check total n0 of element in list
How to count all element of list

count_hour = len(hour)
count_hour
Output
30
step10: get all url of anchor tag and store in list
How to get all url of anchor tag of specific class
url_list = []
# Loop through the anchor tags and extract the 'href' attribute
for anchor in heads:
url = anchor.get('href')
url_list.append(url)
url_list

step11: convert all data into dataframe
import pandas as pd
df= pd.DataFrame({'headline':latest_news,'time':hour,'url':url_list})
df
output


Top comments (0)