Get data from first tbody and first div
Select desired part of string using split
Requirement
how to get url of second td of multiple url
Get data from second tbody and div
how to get data of second/third element of two same div class name
how to get data of second/third td of second tbody
Get data from first tbody and div
Top 10 ODI teams in men’s cricket along with the records for matches, points and rating
step 1 first install libraries
pip install bs4
pip install request
step 2 import libraries
from bs4 import BeautifulSoup
import requests
step3:Send an HTTP GET request to the URL and (status code 200)
page = requests.get('https://www.icc-cricket.com/rankings/mens/player-rankings/odi')
page
output
<Response [200]>
step4: check page content
soup= BeautifulSoup(page.content)
soup
output
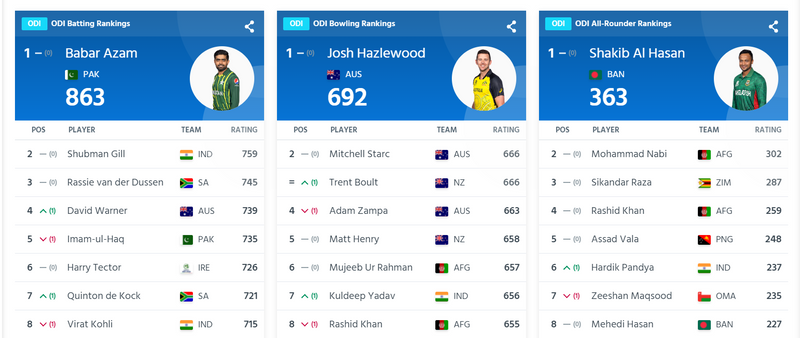
step5: get first player name
first_player = soup.find('div', class_="rankings-block__banner--name")
first_player.text
output
'Babar Azam'
step6: get first player Team name
first_team = soup.find('div', class_="rankings-block__banner--nationality")
my=first_team.text
cleaned_text = my.split()[0]
cleaned_text
output
'PAK'
step7: get first player Ratings name
first_rating = soup.find('div', class_="rankings-block__banner--rating")
first_rating.text
output
'863'
step8: get all player name except first player
player_td_list = []
tbody = soup.find('tbody')
if tbody:
for tr in tbody.find_all('tr'):
tds = tr.find_all('td')
if len(tds) >= 0:
second_td_content = tds[1].text
player_td_list.append(second_td_content.strip())
player_td_list
output

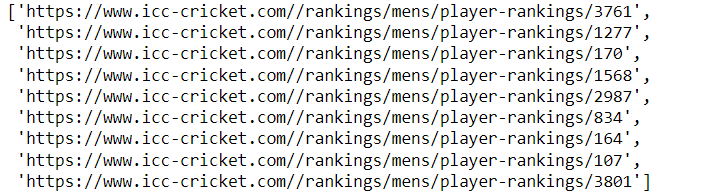
step9: get all player url except first player url
url_list = []
tbody = soup.find('tbody')
if tbody:
for tr in tbody.find_all('tr'):
tds = tr.find_all('td')
if len(tds) >= 0:
second_td_content = tds[1].text
a_tag = tds[1].find('a')
url = a_tag['href']
full_url = "https://www.icc-cricket.com/" + url
url_list.append(full_url)
url_list
output
step10: get all players team except first player team
team_td_list = []
tbody = soup.find('tbody')
if tbody:
for tr in tbody.find_all('tr'):
tds = tr.find_all('td')
if len(tds) >= 0:
second_td_content = tds[2].text
team_td_list.append(second_td_content.strip())
team_td_list
output
step11: get all players ratings except first player ratings
rating_td_list = []
tbody = soup.find('tbody')
if tbody:
for tr in tbody.find_all('tr'):
tds = tr.find_all('td')
if len(tds) >= 0:
second_td_content = tds[3].text
rating_td_list.append(second_td_content.strip())
rating_td_list
output
step12: add first player to all player list
player_td_list.insert(0, first_player.text)
player_td_list
output
step13: add first player team to all player team list

team_td_list.insert(0, cleaned_text)
team_td_list
output
step14: add first player rating to all player ratings
rating_td_list.insert(0, first_rating.text)
rating_td_list
output
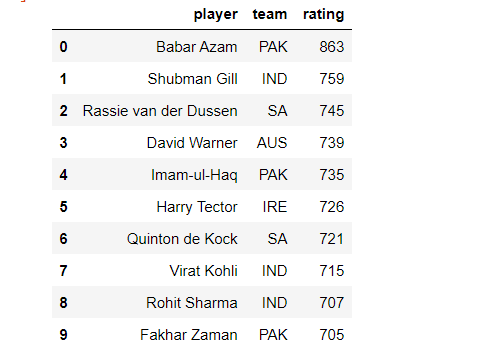
step15: stores all player name ,team and ratings in dataframe
import pandas as pd
df=pd.DataFrame({'player':player_td_list,'team':team_td_list,'rating':rating_td_list})
df
output
Select desired part of string using split
# Given string
text = '\n\nPAK\n 863\n'
# Split the string by newline and spaces, and select the first part
cleaned_text = text.split()[0]
# Print the cleaned text
print(cleaned_text)
=====================or===================
first_team = soup.find('div', class_="rankings-block__banner--nationality")
my=first_team.text
cleaned_text = my.split()[0]
cleaned_text
====================================
Get data from second tbody and div
step 1 first install libraries
pip install bs4
pip install request
step 2 import libraries
from bs4 import BeautifulSoup
import requests
step3:Send an HTTP GET request to the URL and (status code 200)
page = requests.get('https://www.icc-cricket.com/rankings/mens/player-rankings/odi/bowling')
page
output
<Response [200]>
step4: check page content
soup= BeautifulSoup(page.content)
soup
output
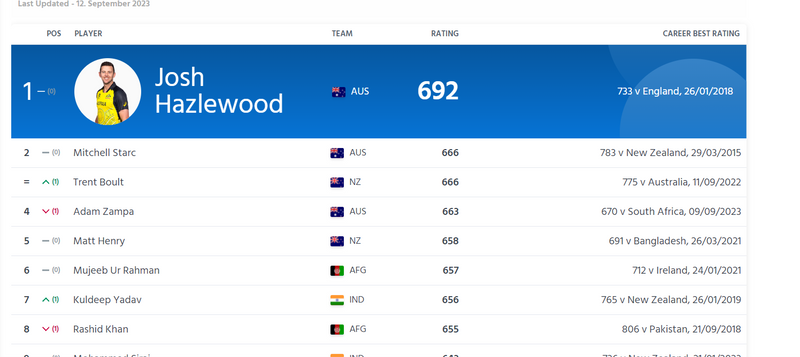
step5: get first player name
elements = soup.find_all(class_='col-4 col-12-desk touch-scroll-list__element')
elements
output
how to get data of second/third element of two same div class name
if len(elements) >= 2:
second_element = elements[1]
second_element
output
banner_name_div = second_element.find(class_='rankings-block__banner--name')
first_player_bowler = banner_name_div.get_text()
first_player_bowler
output
'Josh Hazlewood'
step6: get first player Team name
first_bowler_team = second_element.find('div', class_="rankings-block__banner--nationality")
my=first_bowler_team.text
first_bowler = my.split()[0]
first_bowler
output
'AUS'
step7: get first player Ratings name
first_rating = second_element.find('div', class_="rankings-block__banner--rating")
first_rating.text
output
'692'
step8: get all player name except first player
how to get data of second/third td of second tbody
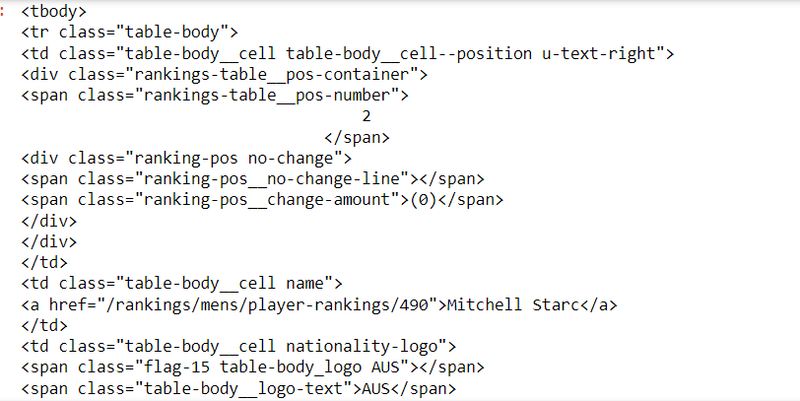
tbody_elements = soup.find_all('tbody')
if len(tbody_elements) >= 2:
second_tbody = tbody_elements[1]
second_tbody
output
bowler_td_list = []
for tr in second_tbody.find_all('tr'):
td_elements = tr.find_all('td')
if len(td_elements) >= 0:
second_td_data = td_elements[1].get_text()
bowler_td_list.append(second_td_data.strip())
bowler_td_list
output

step10: get all players team except first player team
bowler_team_list = []
for tr in second_tbody.find_all('tr'):
td_elements = tr.find_all('td')
if len(td_elements) >= 0:
second_td_data = td_elements[2].get_text()
bowler_team_list.append(second_td_data.strip())
bowler_team_list
output
step11: get all players ratings except first player ratings
bowler_rating_list = []
for tr in second_tbody.find_all('tr'):
td_elements = tr.find_all('td')
if len(td_elements) >= 0:
second_td_data = td_elements[3].get_text()
bowler_rating_list.append(second_td_data.strip())
bowler_rating_list
output
step12: add first player to all player list
bowler_td_list.insert(0, first_player_bowler)
bowler_td_list
output

step13: add first player team to all player team list
bowler_team_list.insert(0, first_bowler)
bowler_team_list
output
step14: add first player rating to all player ratings
bowler_rating_list.insert(0, first_rating.text)
bowler_rating_list
output
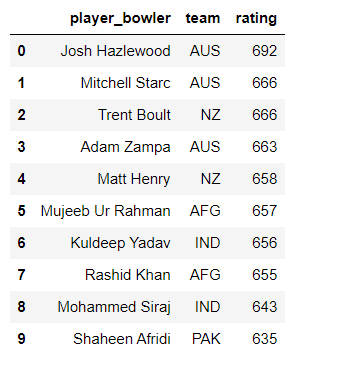
step15: stores all player name ,team and ratings in dataframe
import pandas as pd
df=pd.DataFrame({'player_bowler':bowler_td_list,'team':bowler_team_list,'rating':bowler_rating_list})
df
output

Top comments (0)