Support Vector Machine (SVM) is a supervised machine learning algorithm used for classification and regression tasks. It separates data points into different classes by finding an optimal hyperplane in a high-dimensional feature space. SVM aims to maximize the margin between the hyperplane and the nearest data points of different classes, making it effective for handling complex decision boundaries.


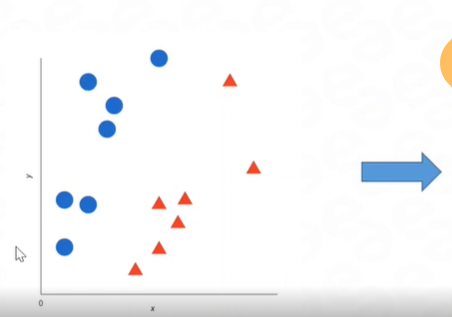
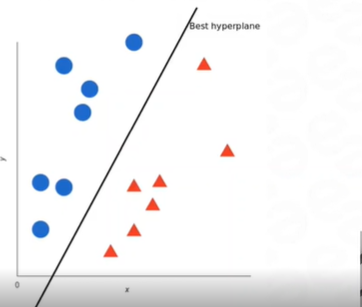



Let's explain SVM with an example of binary classification:
Example:
Suppose we have a dataset with two classes, "Class A" and "Class B", represented by two features (x1, x2). The goal is to classify new data points into one of these two classes.
Training data:
Class A: [(1, 2), (2, 3), (3, 3)]
Class B: [(6, 5), (7, 7), (8, 6)]
Import the required libraries and create the SVM model:
from sklearn import svm
# Create an SVM classifier
clf = svm.SVC(kernel='linear')
Train the SVM model:
# Prepare the training data and labels
X_train = [(1, 2), (2, 3), (3, 3), (6, 5), (7, 7), (8, 6)]
y_train = ['Class A', 'Class A', 'Class A', 'Class B', 'Class B', 'Class B']
# Train the SVM model
clf.fit(X_train, y_train)
Make predictions on new data points:
# Predict the class for a new data point
X_new = [(4, 4)]
y_pred = clf.predict(X_new)
print(y_pred)
Output:
The output of the code snippet will be the predicted class for the new data point (4, 4). It will indicate whether the point belongs to "Class A" or "Class B".
For example, if the output is 'Class A', it means the SVM model has classified the data point (4, 4) as belonging to "Class A".
SVM finds the optimal hyperplane that maximizes the margin between the two classes. In cases where the data is not linearly separable, SVM can still separate the classes by using non-linear kernels such as polynomial or radial basis function (RBF).
Explanation
Let's break down the components:
clf: It is a variable that represents the SVM classifier object. We can use this object to train the model, make predictions, and perform other operations related to SVM.
svm.SVC: svm is the module within scikit-learn that provides implementations of SVM algorithms. SVC stands for Support Vector Classifier, which is the class for SVM classification models.
kernel='linear': This parameter specifies the type of kernel to be used in the SVM model. In this case, we set the kernel to 'linear', indicating that a linear kernel will be used. A linear kernel assumes that the data is linearly separable, and it defines the decision boundary as a hyperplane in the feature space.
By using a linear kernel, the SVM classifier aims to find the optimal hyperplane that best separates the data points of different classes while maximizing the margin. This linear hyperplane is the decision boundary that classifies new data points.
It's important to note that SVMs are not limited to linear kernels. They can also use other types of kernels, such as polynomial or radial basis function (RBF), to handle non-linear decision boundaries. By choosing an appropriate kernel, SVMs can handle complex datasets where the classes are not linearly separable.
The choice of the kernel depends on the nature of the data and the problem at hand. In this case, we specifically set it to 'linear' to demonstrate the use of a linear kernel in SVM classification.

Top comments (0)