How to select anchor tag text element and click using By.XPATH
How to scrape results from from a web page by repeatedly extracting elements with a specific class and clicking a "Load More" button
How to select elements By CLASS_NAME
How to select elements By CLASS_NAME using XPATH
Learning Points
click the element that loads more items using LINK_TEXT
How to apply while loop length of the quote list upto desirded count
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get('https://www.azquotes.com/')
Step 5: click anchor tag text Element
target_href = '/top_quotes.html'
# Locate the anchor tag by its href attribute
anchor_element = driver.find_element(By.XPATH, f'//a[@href="{target_href}"]')
# Click the anchor tag (or perform any other action)
anchor_element.click()
Step 8: Scrape the all quote
How to scrape results from from a web page by repeatedly extracting elements with a specific class and clicking a "Load More" button
Step 1:declare variable desired number of data points to collect
Step 2:declare variable as desired count to desired number of data points to collect
Step 3:Sets up a while loop that will continue executing as long as the length of the quote list is less than or equal to the desired count(above declared variable)
step4: collect all title By class_name
step5:store all data in list using append
step6:click the element that loads more items using LINK_TEXT
step7:Use of list slicing to get records upto above declared variable desired_count
quote = []
# Define the number of data points you want to collect
desired_count = 1000
while len(quote) <= desired_count:
# Find all elements with class "_2WkVRV" on the current page
all_quote_elements = driver.find_elements(By.CLASS_NAME, "title")
# Extract the text values and add them to the data list
for element in all_quote_elements:
quote.append(element.text)
# Try to find and click the element that loads more items (e.g., a "Load More" button)
try:
load_more_button = driver.find_element(By.LINK_TEXT, 'Next →')
load_more_button.click()
except:
# If there are no more items to load, exit the loop
break
quote = quote[:desired_count]
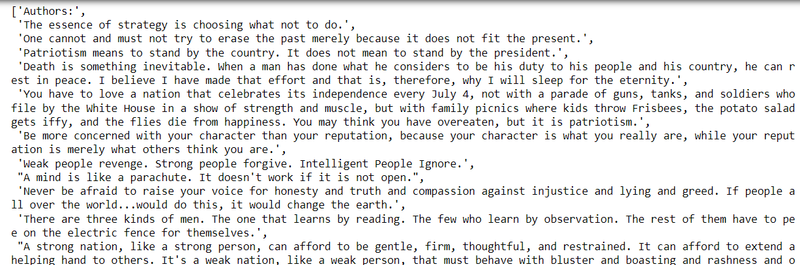
quote
output
Step 9: Scrape the all author
driver=webdriver.Chrome()
driver.get('https://www.azquotes.com/')
target_href = '/top_quotes.html'
# Locate the anchor tag by its href attribute
anchor_element = driver.find_element(By.XPATH, f'//a[@href="{target_href}"]')
anchor_element.click()
# Click the anchor tag (or perform any other action)
data_list=[]
# Define the number of data points you want to collect
desired_count = 1000
while len(quote) <= desired_count:
# Find all elements with class "_2WkVRV" on the current page
all_quote_elements = driver.find_elements(By.CLASS_NAME, "title")
current_data = driver.find_elements(By.XPATH, '//div[@class="author"]/a')
# Extract the text from each data point and add it to the list
for data_point in current_data:
data_list.append(data_point.text)
# Extract the text from each data point and add it to the list
# Try to find and click the element that loads more items (e.g., a "Load More" button)
next_button = None
try:
next_button = driver.find_element(By.LINK_TEXT, 'Next →')
except:
pass
if next_button:
next_button.click()
else:
# If there's no "Next" button or it's not clickable, exit the loop
break
data_list = data_list[:desired_count]
data_list
output

Step 10: Scrape the all description
driver=webdriver.Chrome()
driver.get('https://www.azquotes.com/')
target_href = '/top_quotes.html'
# Locate the anchor tag by its href attribute
anchor_element = driver.find_element(By.XPATH, f'//a[@href="{target_href}"]')
anchor_element.click()
desc=[]
# Define the number of data points you want to collect
desired_count = 1000
while len(quote) <= desired_count:
# Find all elements with class "_2WkVRV" on the current page
tags_div = driver.find_elements(By.CLASS_NAME, 'tags')
# Extract the text from each data point and add it to the list
for description in tags_div:
anchor_tags = description.find_elements(By.TAG_NAME, 'a')
tag_text = ', '.join(tag.text for tag in anchor_tags)
desc.append(tag_text)
# Try to find and click the element that loads more items (e.g., a "Load More" button)
next_button = None
try:
next_button = driver.find_element(By.LINK_TEXT, 'Next →')
except:
pass
if next_button:
next_button.click()
else:
# If there's no "Next" button or it's not clickable, exit the loop
break
desc = desc[:desired_count]
desc
output

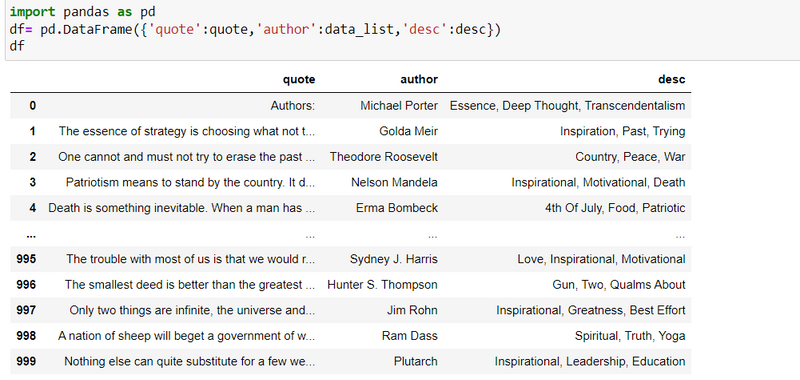
step11: Make a dataframe

Top comments (0)