How to scrape data of multiple page by click 2nd,3rd,4th so on by selecting the second element in the list of elements by CLASS_Name
How to select elements By.NAME to search elements
How to select div,button,a tag class element using xpath
How to getting the link from the list for next page in multiple pagination by click next button
Q4: Scrape data of first 100 sunglasses listings on flipkart.com. You have to scrape four attributes:
- Brand
- ProductDescription
- Price The attributes which you have to scrape is ticked marked in the below image.
Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get('https://www.flipkart.com/')
Step 5: Find the Search Input Element
input_field = driver.find_element(By.NAME,"q")
Step 6: Find the Search Input Element for sunglasses by sending S Keys to the Input Element and then submit button
input_field.send_keys("sunglasses")
input_submit = driver.find_element(By.CLASS_NAME,"_2iLD__").click()
Step 7: Scrape the Results
brand=[]
pro_description=[]
price=[]
Step 8: Scrape the all brand
all_brand=driver.find_elements(By.CLASS_NAME,"_2WkVRV")
all_brand
brand = []
# Define the number of data points you want to collect
desired_count = 100
# While loop to keep clicking pagination or load more button
while len(brand) < desired_count:
# Find all elements with class "_2WkVRV" on the current page
all_brand_elements = driver.find_elements(By.CLASS_NAME, "_2WkVRV")
# Extract the text values and add them to the data list
for element in all_brand_elements:
brand.append(element.text)
# Try to find and click the element that loads more items (e.g., a "Load More" button)
try:
load_more_button = driver.find_element(By.CLASS_NAME, "ge-49M")
load_more_button.click()
except:
# If there are no more items to load, exit the loop
break
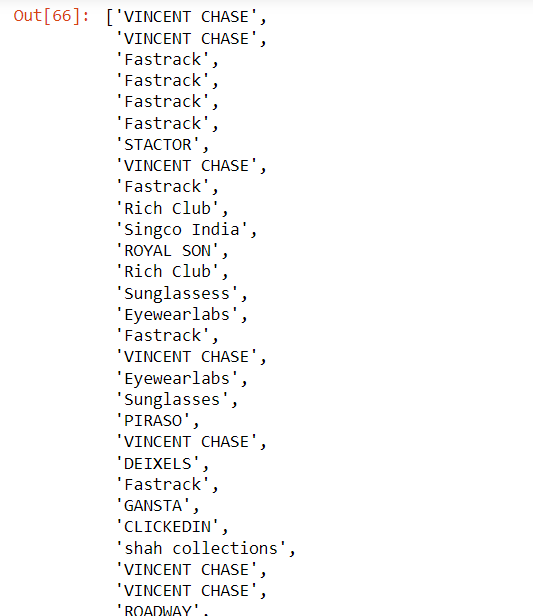
brand = brand[:desired_count]
brand
output
Step 9: Scrape the all product_description
pro_description = []
# Define the number of data points you want to collect
desired_count = 100
while len(pro_description) <= desired_count:
# Find all elements with class "_2WkVRV" on the current page
all_pro_elements = driver.find_elements(By.CLASS_NAME, "IRpwTa")
# Extract the text values and add them to the data list
for element in all_pro_elements:
pro_description.append(element.text)
# Try to find and click the element that loads more items (e.g., a "Load More" button)
try:
load_more_button = driver.find_element(By.CLASS_NAME, "ge-49M")
load_more_button.click()
except:
# If there are no more items to load, exit the loop
break
pro_description = pro_description[:desired_count]
pro_description
output

Step 10: Scrape the all price
price = []
# Define the number of data points you want to collect
desired_count = 100
# While loop to keep clicking pagination or load more button
while len(price) < desired_count:
# Find all elements with class "_2WkVRV" on the current page
all_brand_elements = driver.find_elements(By.CLASS_NAME, "_30jeq3")
# Extract the text values and add them to the data list
for element in all_brand_elements:
price.append(element.text)
# Try to find and click the element that loads more items (e.g., a "Load More" button)
try:
load_more_button = driver.find_element(By.CLASS_NAME, "ge-49M")
load_more_button.click()
except:
# If there are no more items to load, exit the loop
break
price = price[:desired_count]
price
output

step11: make a dataframe
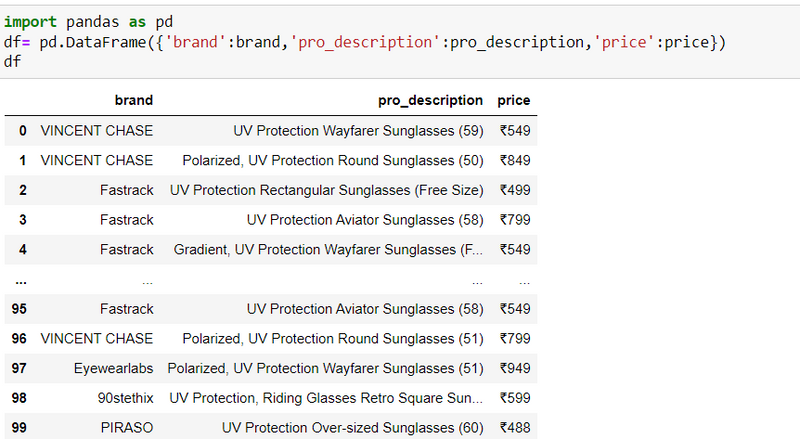
=======================================================
SECOND Examples
Q6: Scrape data forfirst 100 sneakers you find whenyou visit flipkart.com and search for “sneakers” inthe
search field.
You have to scrape 3 attributes of each sneaker:
- Brand
- ProductDescription
- Price Step 1: install selenium using python
pip install --upgrade selenium
Step 2: Import Required Libraries
import pandas as pd
from selenium import webdriver
import warnings
warnings.filterwarnings('ignore')
from selenium.webdriver.common.by import By
import time
Step 3: Start a WebDriver Instance
driver=webdriver.Chrome()
Step 4: Navigate to a Webpage
Navigate to the webpage where you want to interact with the search input bar:
driver.get('https://www.flipkart.com/')
Step 5: Find the Search Input Element
input_field = driver.find_element(By.NAME,"q")
Step 6: Find the Search Input Element for sunglasses by sending S Keys to the Input Element and then submit button
input_field.send_keys("sneakers")
input_submit = driver.find_element(By.CLASS_NAME,"_2iLD__").click()
Step 7: Scrape the Results
brand=[]
pro_description=[]
price=[]
brand2=[]
pro_description2=[]
price2=[]
brand3=[]
pro_description3=[]
price3=[]
Step 8: Scrape the all brand
all_brand=driver.find_elements(By.CLASS_NAME,"_2WkVRV")
all_brand
for brands in all_brand:
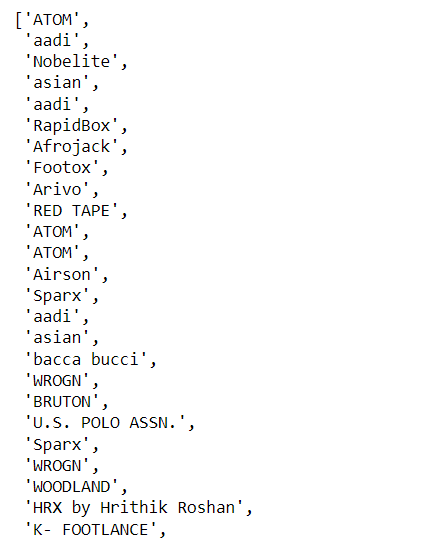
brand.append(brands.text)
brand
output
Step 9: Scrape the all product_description
all_product=driver.find_elements(By.CLASS_NAME,"IRpwTa")
all_product
for products in all_product:
pro_description.append(products.text)
pro_description
output

Step 10: Scrape the all price
all_price=driver.find_elements(By.CLASS_NAME,"_30jeq3")
all_price
price=[]
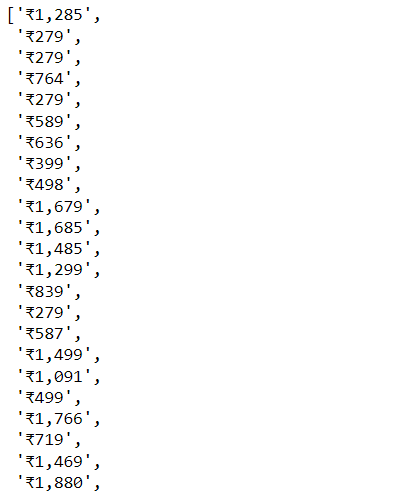
for cost in all_price:
price.append(cost.text)
price
output
step 11: click next page
How to scrape data of multiple page by click 2nd,3rd,4th so on by selecting the second element in the list of elements by CLASS_Name
next_submit = driver.find_elements(By.CLASS_NAME,"ge-49M")[1].click()
step 12: repeat above process
for brands in all_brand:
brand2.append(brands.text)
brand2
all_product=driver.find_elements(By.CLASS_NAME,"IRpwTa")
all_product
for products in all_product:
pro_description2.append(products.text)
pro_description2
all_price=driver.find_elements(By.CLASS_NAME,"_30jeq3")
all_price
price2=[]
for cost in all_price:
price2.append(cost.text)
price2
next_submit = driver.find_elements(By.CLASS_NAME,"ge-49M")[2].click()
all_brand=driver.find_elements(By.CLASS_NAME,"_2WkVRV")
all_brand
for brands in all_brand[0:20]:
brand3.append(brands.text)
brand3
all_product=driver.find_elements(By.CLASS_NAME,"IRpwTa")
all_product
for products in all_product[0:20]:
pro_description3.append(products.text)
pro_description3
all_price=driver.find_elements(By.CLASS_NAME,"_30jeq3")
all_price
price3=[]
for cost in all_price[0:20]:
price3.append(cost.text)
price3
================================================
4)Scrape data of first 100 sunglasses listings on flipkart.com. You have to scrape four attributes:
Brand
Product Description
Price
To scrape the data you have to go through following steps:
Go to flipkart webpage by url https://www.flipkart.com/
Enter “sunglasses” in the search field where “search for products, brands and more” is written and click the search icon
after that you will reach to a webpage having a lot of sunglasses. From this page you can scrap the required data as usual.
after scraping data from the first page, go to the “Next” Button at the bottom of the page , then click on it
# Activating the chrome browser
driver=webdriver.Chrome()
# Opening the homepage-
driver.get("https://www.flipkart.com/")
# Entering sunglasses in search box-
sunglasses=driver.find_element(By.CLASS_NAME,"_3704LK")
sunglasses.send_keys('sunglasses')
# Closing the pop up-
pop_up=driver.find_element(By.XPATH,"//button[@class='_2KpZ6l _2doB4z']")
pop_up.click()
#Clicking on Search Button-
search=driver.find_element(By.CLASS_NAME,"L0Z3Pu")
search.click()
#Creating Empty List for different attributes-
brand=[]
prod_desciption=[]
price=[]
time.sleep(3)
How to select div,button,a tag class element using xpath
# Scraping Data for different Attributes-
start=0
end=3
for page in range(start,end):
brands=driver.find_elements(By.XPATH,"//div[@class='_2WkVRV']")
for i in brands[0:100]:
brand.append(i.text)
Product_desc=driver.find_elements(By.XPATH,"//a[@class='IRpwTa']")
for i in Product_desc[0:100]:
prod_desciption.append(i.text)
prices=driver.find_elements(By.XPATH,"//div[@class='_30jeq3']")
for i in prices[0:100]:
price.append(i.text)
next_button=driver.find_elements(By.XPATH,"//a[@class='_1LKTO3']")
# Creating Dataframe-
df=pd.DataFrame({'Brand':brand[0:100],'Prod_desc':prod_desciption[0:100],'Price':price[0:100]})
df
============================================================
Q6:Scrape data for first 100 sneakers you find when you visit flipkart.comand search for “sneakers” in the search field.You have to scrape 3 attributes of each sneaker :
- Brand
- Product Description
- Price
- Also note that all the steps required during scraping should be done through code only and not manually.
# Activating the chrome browser
driver=webdriver.Chrome()
# Opening the homepage-
driver.get("https://www.flipkart.com/")
# Entering sneakers in search box-
sneakers=driver.find_element(By.CLASS_NAME,"_3704LK")
sneakers.send_keys('sneakers')
pop_up=driver.find_element(By.XPATH,"//button[@class='_2KpZ6l _2doB4z']")
pop_up.click()
#Clicking on Search Button-
search=driver.find_element(By.CLASS_NAME,"L0Z3Pu")
search.click()
#Creating Empty List for different attributes-
brand=[]
description=[]
price=[]
How to getting the link from the list for next page in multiple pagination by click next button
# Scraping Data for different Attributes-
start=0
end=4
for page in range(start,end):#for loop for scrapping 4 page
brands=driver.find_elements(By.CLASS_NAME,'_2WkVRV')#scraping brands name by class name='_2WkVRV'
for i in brands:
brand.append(i.text)#appending the text in Brand list
prices=driver.find_elements(By.XPATH,"//div[@class='_30jeq3']")# scraping the price from the xpath
for i in prices:
price.append(i.text)
desc=driver.find_elements(By.XPATH,'//a[@class="IRpwTa" or @class="IRpwTa _2-ICcC"]')#scraping description from the xpath
for i in desc:
description.append(i.text)
nxt_button=driver.find_elements(By.XPATH,"//a[@class='_1LKTO3']")#scraping the list of buttons from the page
try:
driver.get(nxt_button[1].get_attribute('href'))#getting the link from the list for next page
except:
driver.get(nxt_button[0].get_attribute('href'))

Top comments (0)